







1 背景
去年,国内大模型赚钱最爽的一个方向,就是卖数据。
我也跟一些卖数据团队咨询过,他们把国内各个你能想到的主流中文平台的数据都爬下来,打包卖了。
国内的头部玩家,手头数据是一定不缺的,买就行了。
同时,这些玩家显卡资源管够的情况下,肯定是会把能train的数据都train一轮。
除非是预训练数据有大的更新,例如清洗的质量更高了,生成数据有大的突破。
或者训练手段有大的迭代,重训大模型的价值是在不断降低的。
但底座模型的通用能力,本身就是有上限的,它就是做不到所有都很强。
我们想要把某个领域加强,别的领域就或多或少的会被影响。
从2022年这篇OpenAI这篇论文开始,Training language models to follow instructions with human feedback。
Aligntment Tax就一直存在。

但很多场景,例如,教育,代码场景,用户的需求往往比较集中。
那么保证通用能力不跌很多的情况下,努力把domain效果提上去就好了。
也就是做continue pretrain(领域大模型)
除此之外
英文到中文的continue pretrain,例如把llama增训成中文(国内很多公司的操作,这并不丢人,效果还挺好)。
long context的continue pretrain。
关于continue pretrain做了一个小范围分享,具体参看论文。
https://arxiv.org/pdf/2406.01375
。
2 步骤
continue pretrain的步骤整体分成三步。
2.1 扩词表
不是所有的continue pretrain都需要扩词表。
举个例子
用llama英文底座,增训成中文的,因为词表差距很大,往往都需要添加词表。
做教育大模型,一堆标点符号,底座模型覆盖的不好,也需要扩充。
你需要自行判断,底座模型的词表跟你的任务的词表分布差距如何。
2.2 Domain Continue Pretrain
2.2.1 Replay
需要采样pretrain阶段的数据。
还有一个潜在的坑,现在的pretrain往往会在最后阶段混入sft数据,关于这个的合理性,我在之前的文章中有过讨论。
但现在开源base模型,最多也就开源样本比例。
这些pretrain的模型,最后混了那些SFT数据来提升某些领域的效果,只能靠经验来反推了。
(所以continue pretrain后对比原base掉点严重,可能是你少混了一些SFT数据。
2.2.2 比例控制
domain数据占比过高,可能loss就直接崩了。
占比太低,学习效率低,会导致最后domain提升不大。
但麻烦的点,就是如何判断什么比例是最佳的。
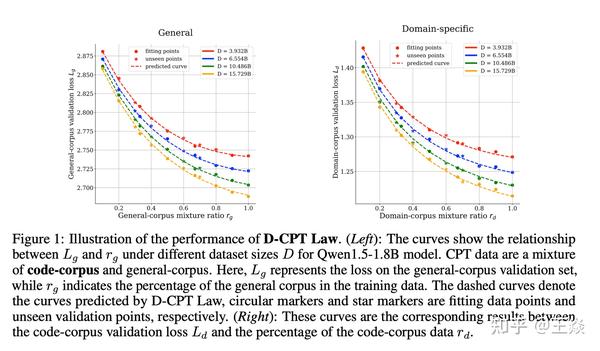
张舸和浩然的论文发现,continue pretrain阶段,随着domain数据占比的提升,通用loss和domain loss的确是一个此消彼长,然后趋于稳定的过程。
假设通用数据的占比是r,那么domain数据的占比就是1-r,张舸和浩然的论文中给出的关于数据比例的scaling law的公式为
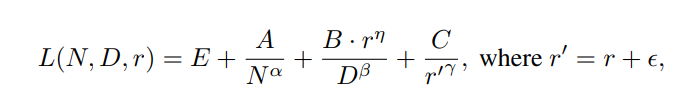
增大domain数据的占比,那么domain loss会降低,通用loss会上升,在拟合好上述公式后,就可以计算不同比例下domain loss和通用loss的预估值
domain数据有了,预训练replay数据有了。在小规模的实验(模型参数量小,训练数据少)下continue pretrain,得到一些实验数据点,用实验数据点拟合上述公式,得到拟合参数值,就可以算更大参数量下的domain loss和通用loss。
2.2.3 Scaling Law
我想要去计算,我要训练多少步,loss才会降低到一个不错的级别。
还是上面的scalling law
可以计算出大概训练多少步后,domain loss几乎就不会再下降了
问题在于,pretrain都做了的公司,其实continue pretrain的训练,不差这点训练成本,大不了我多train一会。
但对于一些中小厂来讲,最多也就continue pretrain一个7B模型,能大致知道一个节点,价值还是很大的。
scaling law失效的情况。
张舸和浩然是在qwen模型做实验,参数量也没那么大,并且还多了一个ratio的变量,导致公式变得更加复杂,并且还有不同domain的数据质量不一致的情况。
所以,这篇论文更大的意义,在于告诉我们,continue pretrain是能有一个公式来拟合预测loss下降的情况。
但这个公式,可能还是需要大家亲自去拿小模型自己实验一下。
2.2.4 参数
continue pretrain的lr和pretrain的lr要怎么设定。
维持pretrain的lr不变,warmup直接设定为零,不需要warmup。
batch size也是调大一些,会有一些不错的效果。
如果有退火,从经验来看,需要把lr涨回去,这个时候loss会有一个相对波动比较大的阶段,但你再观察一段时间会稳定下来。
所以,还是需要具体情况,具体分析。
不同的base模型的操作会有区别,大家自行探索。
2.3 Domain对齐
对其是另外的一个世界了,先不展开。
但比例方面,大家往往也是会吧domain的SFT数据比例调的高一点,来保证最后的效果。
3 不同domain的特点
continue pretrain分成三大类
领域知识,语言类,long context
受到词表,知识难度,attention分布的影响,这几类知识的学习都会有不少的差距。
其中领域知识增强类的domain更容易学习,因为基座llm中存在这样的知识,所以起始loss会更低,遗忘程度低,最优的配比低。
语言类的domain和long context的数据更难学习,前者是因为语言的gap导致初始loss偏高,但随着不断的训练,loss会稳定下降,但遗忘程度高,最优配比高,后者对资源的消耗更高,遗忘程度高,最优配比高。
3.1 领域知识Continue Pretrain
3.1.1 难点
比例的控制,训练多少tokens可以拿出来做对齐。
这里参考张舸和浩然论文即可。
3.1.2 样本质量的变化会不会导致scalling law公式的变化
张舸和浩然论文的数据,都是基于公开数据集。
但问题在于,日常大家自己训练,肯定会自己再做一轮清洗。
样本质量的改变,会不会导致这个公式的指导意义出现大的波动?
因为语料质量的提升,可能一条样本顶过去两条。
所以针对不同的领域数据而言,公式中的拟合参数都是不一样的,这里建议在自己的模型上进行实验后,然后确定公式中的拟合参数具体值。
所以,continue pretrain对于头部玩家来讲,意义不是特别大,我完全可以跑10个比例,然后一路二分。
但对中小厂,价值就非常高了。
我上一篇预训练文章发出来后,不少人私底下问我,预训练中英文的比例是多少比较合适。
毕竟除了几个头部玩家,中小厂的显卡还是很紧缺的。
3.2 语言类Continue Pretrain
3.2.1 难点
去年大家的常用做法,就是已知llama的中文占比5%,那么我一点点增大中文的训练样本比例。
而不是算好一个比例,直接硬train,这很容易导致loss直接崩掉。
3.2.2 为什么语言的continue pretrain,比例不能剧烈变动?
当天讨论有两点原因
不同的知识,集中在不同的transformer层
之前内部实验
发现transformer越往上,最后一层的知识往往就越具体,越底层的知识反而越基础。
类似cnn做人脸识别,第一层抽取的特征是线条,到了最后一层就变成了鼻子,人脸这些特征。
语义这些知识,是最基础的知识,往往是在最底层,更新起来影响的层数更多。
domain知识是最后几层,更新起来影响的层数相对更小一些。
扩词表
新词的embedding是随机初始化的,是transformer最底层了。
同理,更新影响面更大。
3.3 Long Context Continue Pretrain
3.3.1 continue pretrain学了什么
拿long context举例子,根据我们的一些分析
LLM本身就具有long context的能力,或者说是已经学到了文本的框架。
而之所以外推不好,其中一个猜测就是attention分布导致的。
而long context的continue pretrain某种程度上是让attention分布的调整。
https://arxiv.org/abs/2404.15574
(例如这篇文章)
知识的重新学习并不是大头。
而中英文,代码,法律等的continue pretrain。
我相信底座模型也是有这样的知识的,他们是不是也是某种attention的调整?
continue pretrain,让底座模型对这块的知识attention更加友好一些?
当然,no free lunch,这种attention调整会带来通用domain的下降(但正如开头所说,只要别跌太狠,这些场景并不是特别care)
从这个角度来看,语言类continue pretrain比领域知识类continue pretrain的attention调整要更难,所以贸然的剧烈样本分布,学崩了也很正常。
3.3.2 做法
long context continue pretrain
fuyao的论文
https://arxiv.org/abs/2402.10171
就是把各种短文本拼接成长的。
进阶的做法,我可以做个聚合,把相似的拼接到一起。
3.3.3 问题
我们的科研团队,有一个方向就是做long context 低成本continue pretrain,benchmark效果还可以,论文都投出去了。
但一直没有拿出来讲的一个原因,就是如何评估continue pretrain的效果。
我们continue pretrain完,找了一些评估集合来评估,发现指标都不错。
但效果真的好,还是得SFT后的效果才能说了算。
Long Context的SFT是另外一种难(不是技术上的),也是我们近期要重点解决的问题。
其实中英文和domain知识的continue pretrain也一样,是否真的好,还是得SFT后的效果说了算。
这次的分享,包括基于这个分享,跟不少人私底下也有一些讨论。
发现,pretrain这半年比较大的进展都是偏架构方面。
例如,MOE,deepseek的MLA(这是一个非常棒的工作和尝试)。
这块往往是架构和算法都很牛的人才能做好。
deepseek的开源moe,也做得非常不错,应该是国内开源top了,他们的pretrain团队做的挺棒的
但算法为主的,做pretrain,往往就是洗数据了。
尴尬的点是,预训练洗数据,因为数据量大,往往都是搞各种小模型+规则,很难说明你做的事情的技术含量,只能体现你对数据的认知很好。
但随着模型参数量的增大,洗这么干净的数据合理么?模型是不是到了后面,自己就能做一些区分了?做那么多label意义真的大么?
对个人的发展的确不是那么友好,这也是真的。
(所以,可以往对其,long context,多模态转移一下,这才是我们算法的主战场















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









