







最近一两天,“直播答题”已席卷互联网。王思聪力推《冲顶大会》、周鸿祎的花椒直播上线《百万作战》、今日头条&西瓜视频推出《百万英雄》、映客在线答题《芝士超人》、一直播的《黄金十秒》……仿佛一夕之间,众多互联网直播版《开心辞典》冒了出来。

这些直播答题的题目范围涉及很广,天文地理历史科学娱乐影视音乐诗歌礼仪等,每次活动共12道题,也难怪王思聪会挑衅地说“觉得自己很聪明可以来试试”,反正,规则就是10秒中之内未答题和答错题都将被淘汰,且无法角逐当期的奖金。
虽然通过邀请好友可以获得复活次数,但是毕竟复活很宝贵,而且每轮只能复活一次,如果复活之后答错会更加可惜。那么怎么样才能够短时间内提升我们的准确率呢?
原理说明
1.手机进入冲顶大会(或其他答题类APP)
2.获取屏幕截图
- iPhone可以通过WDA进行图片截取,或者通过通过AirPlay/QuickTime投影到电脑上截取,参考链接
- Android可以通过adb截图并拉取到本地
#adb进行截图
adb shell screencap -p /sdcard/autojump.png
adb pull /sdcard/autojump.png .4.使用三种方法对识别出的问题进行判断
#直接用浏览器打开问题
def open_wabpage(question):
webbrowser.open('https://baidu.com/s?wd=' + question)
#根据问题搜索结果计算每个选项出现的次数
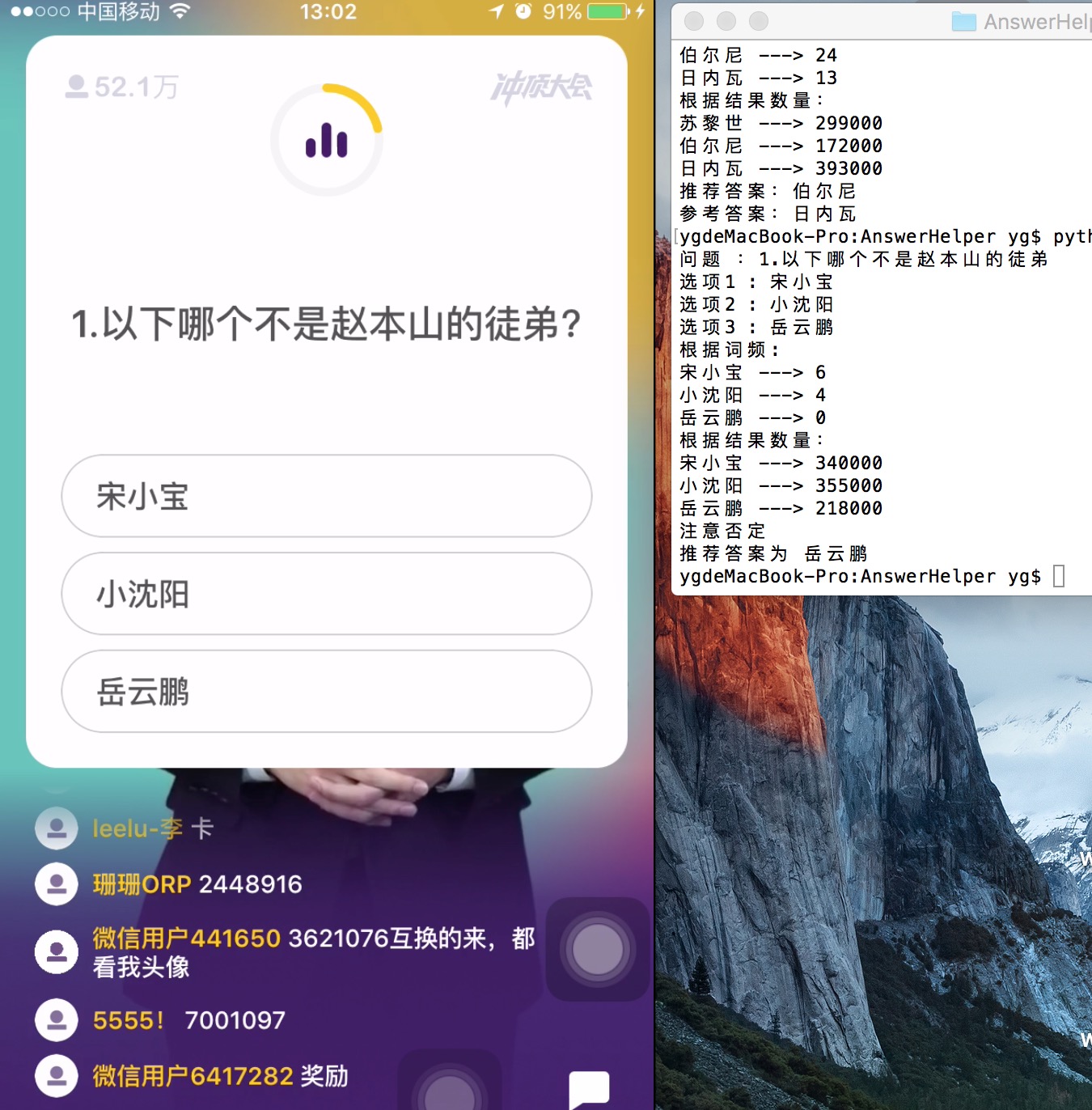
def words_count(question,answers):
print "根据词频:"
req = requests.get(url='http://www.baidu.com/s', params={'wd': question})
body = req.text
counts = []
for answer in answers:
num = body.count(answer)
counts.append(num)
print answer + " ---> " + str(num)
return counts;
#计算问题+每个选项搜索的结果数
def search_count(question,answers):
print "根据结果数量:"
counts = []
for answer in answers:
req = requests.get(url='http://www.baidu.com/s', params={'wd': question +"%20"+answer})
body = req.text
start = body.find(u'百度为您找到相关结果约') + 11
body = body[start:]
end = body.find(u"个")
num = body[:end]
num = num.replace(',', '')
counts.append(num)
print answer + " ---> " + str(num)
return counts 使用教程
1.下载代码并安装Python2.7环境,代码地址见文末2.安装百度orc库
pip install baidu-aip4.在img_utils中选择你喜欢的获取图片的方式,并且调整截图区域
5.在终端中运行
python main.py
运行截图
更新
2018.01.11 冲顶大会增加了api直接抓题功能,几乎无需配置即可分析答案,详情见文末github
辅助工具只能够提升准确率,对于一些很坑很怪的问题可能依然会存在一定问题,后面会不断对判断策略进行优化,也欢迎大家提出一些更优的策略。

















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









