







用Python读取PDF年报文件进行词频统计画词云和柱形图
【Python】本文使用pdfplumber库读取江淮汽车2022年年报PDF文件,使用jieba库进行分词,从而进行词频统计,通过词频统计使用wordcloud库和matplotlib库画词云和柱形图
jieba库分词原理
◆ 提供中文词库 pip install jieba
◆ 将待分词的内容与分词词库进行比对
◆ 通过图结构和动态规划方法找到最大概率词组
◆ 增加自定义中文单词的功能
词云相关库
matplotlib:用于绘图的第三方库
wordcloud:用于词云展示的第三方库
注意!运行前请先下载字体库和江淮汽车2022年年报,链接如下:
链接:https://pan.baidu.com/s/1bxFcHqLfNtulJ-M3AS20AA?pwd=8et8
提取码:8et8
完整代码如下:
'''
读取江淮汽车2022年年报PDF文件,进行词频统计,通过词频统计画词云和柱形图
'''
import wordcloud
import matplotlib.pyplot as plt
import pdfplumber
import jieba
import string
# 读取年报内容
pdf = pdfplumber.open('江淮汽车2022年年度报告.pdf')
pages = pdf.pages
text_all = []
for page in pages:
text = page.extract_text()
text_all.append(text)
paper = ''.join(text_all)
pdf.close()
# 使用jieba分词
words = jieba.lcut(paper)
counts = {}
# 为每个词计数
for word in words:
if word not in counts:
counts[word] = 1
else:
counts[word] += 1
# 删除不需要的一些字符
chinese_punctuation = ',。!?;:‘’“”()【】《》〈〉「」『』〔〕—…-·、`√1234567890 □' # 中文标点符号和数字
for punctuation in string.punctuation + chinese_punctuation:
try:
del counts[punctuation] # 删除标点符号
except:
continue
del counts['\n'] # 删除换行符
# 绘制词云
wc = wordcloud.WordCloud(
font_path = 'simhei.ttf', # 中文字体文件
repeat=False, # 词语不重复
background_color = 'white', # 背景颜色
max_words = 100, # 最大词语数量
max_font_size = 120, # 最大字体
min_font_size = 10, # 最小字体
)
wc.generate_from_frequencies(counts)
plt.imshow(wc)
plt.axis('off') # 取消坐标轴
plt.show()
# 绘制柱形图
plt.rcParams['font.sans-serif'] = 'SimHei' # 中文字体
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True) # 从大到小排序
for item in items[:10]:
word = item[0]
number = item[1]
plt.bar(word, number)
plt.show
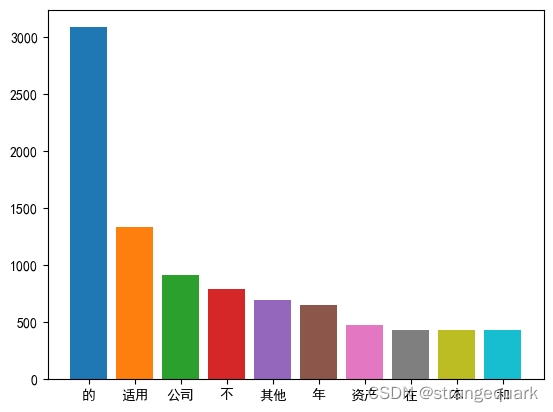
结果如下:
词云:

柱形图:
















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











