







这个笔记是对2014年VGG网络《Very Deep Convolutional NetWorks for Large-Scale Image Recognition》一些笔记。笔记按照文章的结构来做的。
论文下载地址 http://arxiv.org/pdf/1409.1556v6.pdf
1. 引言
- 自2012年AlexNet神经网络引起大量的关注之后, 大量的研究者在尝试着对它进行改进, 如:
- 在第1个卷积层中, 使用更小的接收窗口及更小的步幅带来结果的提升
- 对训练数据及测试数据进行基于多尺度变换也会提升模型的效果
这篇论文是希望对卷积神经网络的深度进行探讨. VGG通过使用小的卷积核,来增加卷积层的数量以加深网络,发现深度越深,网络学习能力越好,分类能力越强。
2. 网络配置
- 和AlexNet的数据预处理的方式一样, 首先计算得到训练集中RGB三个通道的均值, 然后让每张图片RGB都减掉这样相应的均值.
- 采用3×3的卷积核, stride=1, 主要是因为
- 3×3的卷积核是最小的能够捕获上下左右和中心概念的尺寸
- 使用多个小的卷积核, 可以达到一个大的卷积核差不多的感受野, 同时还可以减少网络的参数. 如三个3×3和一个7×7的感受野都是7, 假设filters的数量为C的话,那么3个3×3的卷积层参数个数 3 ∗ 3 ∗ 3 ∗ C ∗ C = 27 C 2 3*3*3*C*C=27C^{2} 3∗3∗3∗C∗C=27C2;一个7×7的卷积层参数为 49 C 2 49C^{2} 49C2
- 多个3×3的卷基层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判别能力.
- 论文也使用过1×1的卷积核. 其作用是在不改变输入输出维数的情况下,对输入进行线性变换,同时通过ReLU增加非线性处理,增加网络的非线性表达能力。
- 池化层中使用 Max-Pooling:2×2,间隔strides=2;
- 全连接层和AlexNet中的设置一样,前两个全连接级使用4096个神经元, 最后一层使用1000个神经元, 以对应ILSVRC的输出.
- 作者在经过实验之后,指出AlexNet使用的LRN并没能提升效果, 反而增加了计算量, 因此, 作者在后面的实验中,舍弃了LRN.
3.分类
- 尽管VGG比Alex-net有更多的参数,更深的层次;但是VGG需要很少的迭代次数就开始收敛。这是因为:
(1)深度和较小的filter尺寸起到了隐式的规则化的作用。
(2)在特定的层使用了预训练得到的数据进行参数的初始化。 - 训练数据的处理(多尺度训练)
多尺度的意义在于图片中的物体的尺度有变化,多尺度可以更好的识别物体。有一个概念需要了解下: 各项同性缩放(isotropically-rescaled), 也称同比缩放, 它是指将图片等比例地进行缩放, 使图像不发生变形, 记缩放后最短边的像素为S. 具体地, 论文给出两种方式的训练数据的处理方法。
- 在不同的尺度下,训练两个不同的模型, 如S=256和S=384, 先是训练S=256的,然后拿最后的参数, 来做fine-tuning, 去训练S=384的模型(这种方法叫做固定尺度的训练方法)
- 对于每张图片, 缩放到[256, 384]之间随机的一个S, 然后对缩放后的数据进行训练。这种方式是对尺度抖动(Scale jittering) 的数据增强, 网络参数初始化时使用S=384时的参数.
- 同时, 可以对得到的图片进行水平翻转、RGB通道变换, 来进一步地数据增强.
- 在VGG网络的测试阶段, 对于测试数据进行预测时, 有两种预测方法 [ 1 ] ^{[1]} [1]:
- 方法1: multi-crop,即对图像进行多样本的随机裁剪,然后通过网络预测每一个样本的结构,最终对所有结果平均
- 方法2: densely, 利用FCN的思想,将原图直接送到网络进行预测,将最后的全连接层改为1x1的卷积,这样最后可以得出一个预测的score map,再对结果求平均,下图展示的就是FCN的示意图:

这种方式可以支持多尺度的输入, 下面两张图 [ 2 ] ^{[2]} [2]可以展示出处理不同尺度的输入时的过程:
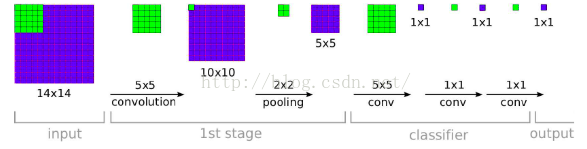
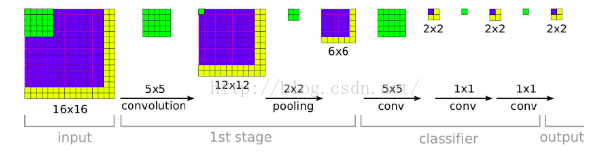
- 上述两种方法分析:
- Szegedy et al.在2014年得出multi-crops相对于FCN效果要好
- multi-crops相当于对于dense evaluation的补充,原因在于,两者在边界的处理方式不同:multi-crop相当于padding补充0值,而dense evaluation相当于padding补充了相邻的像素值,并且增大了感受野
- multi-crop存在重复计算带来的效率的问题
- 论文原话: Also, multi-crop evaluation is complementary to dense evaluation due to different convolution boundary conditions: when applying a ConvNet to a crop, the convolved feature maps are padded with zeros, while in the case of dense evaluation the padding for the same crop naturally comes from the neighbouring parts of an image (due to both the convolutions and spatial pooling), which substantially increases the overall network receptive field, so more context is captured.
- 作者的观点是倾向于 dense evaluation的. 原文"While we believe that in practice the increased computation time of multiple crops does not justify the potential gains in accuracy" 以及"Another line of improvements dealt with training and testing the networks densely over the whole image and over multiple scales (Sermanet et al., 2014; Howard, 2014)“ .
- 作者也做了对比实验: for reference we also evaluate our networks using 50 crops per scale (5 × 5 regular grid with 2 flips), for a total of 150 crops over 3 scales, which is comparable to 144 crops over 4 scales used by Szegedy et al. (2014)."
- 超参数设置
批量大小 batchsize = 256;
权重衰减 weight decay = 0.0005;
学习率learning_rate = 0.01, 衰减因子为0.1;
动量momentun = 0.9, 优化方式为带动量的SGD)
迭代步数: 370K
轮数 Epoches = 75
其它实验及结论部分就省略了…(完)
参考
[1] VGG网络的测试方法总结参考 https://blog.csdn.net/C_chuxin/article/details/82832229
[2] FCN可以参考https://blog.csdn.net/hjimce/article/details/50187881















 1877
1877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









