







这个文章是对N Kalchbrenner于2014年发表的《A Convolutional Neural Network for Modelling Sentences》论文的一些笔记。笔记基本按照文章的结构来的。
论文下载地址 https://www.aclweb.org/anthology/P14-1062
0. 问题的背景
- 所谓句子建模,即represent the semantic content of sentence. 但是如果从句子层面上对句子进行建模却又是比较困难的, 因为一个句子, 通常是独一无二 (Problem: individual sentences are rarely observed or not observed at all.) , 因此,基于words或者n-grams这些比较经常出现的无素来对句子建模是比较可取的。
- 词表征学习 传统的NLP, 把Words当成discrete symbols(localist representation.) 来对待,通过One-hot编码这样的表示, 可以表示出了词的惟一性, 但不能维持词与词的联系,如 Seattle motel 与 Seattle hotel是一个意思,但使用one-hot编码的话, 却不能体现它们之间的联系。
- 当我们考虑什么样的词经常出现在一起, 我们可以使用共现矩阵来表示,这样的共现矩阵通常设置为对称的, 即不对左右顺序进行区分, 但这种简单的共现矩阵却存在着一些问题
- increase in size with vocabulary
- very high dimensional: require a lot of storage
- subsequent classification models have sparse issues
- Models are less robust
- 解决的方案: store “most” of the import information in a fixed, small number of dimensions: a dense vector usually around 25-1000 dimensions, 如可以使用SVD对这样的共现矩阵进行矩阵分解,通过矩阵分解的方式可以缓解前面的问题,但SVD矩阵分解同样有一些问题:
- 但还是有各种各样的问题, 如当维度很大时, 计算量太大
- 不能处理新的单词组合
- 那我们是否可以直接不使用共现矩阵的方式,直接学习出这样的低维向量呢! 自然可以, Word2Vec方法就是这样处理的, 使用分布式表示来表征词已经成为了一种趋势.
- 但如何word2vec的方式来做句子建模呢,这个就是作者发表的论文所要解决的问题了.
1. 引言
- 使用神经句子模型的优势
- 可以通过预测的方式(如预测某个词语或词组)来获得词语的词向量表示.
- 并且通过有监督的学习,可以做 fine-tune, 以使得这些词向量可以适应某些特殊的任务
- 除此之外, 神经句子模型还可以学会造句(其内部强大的分类能力)
- 论文的特点: 一维的卷积操作; k-max池化方法; 动态的k取值以适应不同长度的句子; 使用多个卷积提取特征. 等等…
2. 背景
- 一维卷积
- 一维卷积的操作如下图如示:
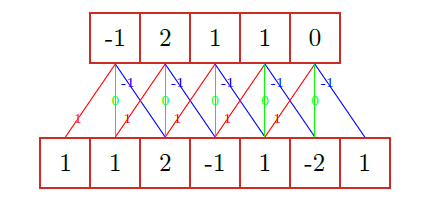
- 一维卷积有两种形式: 窄卷积和宽卷积

- 窄卷积对边界处理不好, 尤其是当卷积比较大时, 会造成上层的输出过少. 而宽卷积可以很好的处理边界问题,同时输出不会减少.
- 假设我们的词向量的维度为 d d d, 则将 d d d个卷积核组成一个卷积矩阵 m ∈ R d × m \mathbf{m} \in \mathbb{R}^{d\times m} m∈Rd×m, 其中 m m m为卷积核的大小, 而一个句子就可以描述成 s ∈ R d × s \mathbf{s} \in \mathbb{R}^{d\times s} s∈Rd×s. TDNN使用的是窄卷积,同时使用Max-Pooling的方式
- TDNN的优势:
- 对词语的顺序敏感,不依赖于词语的具体位置
- 并不需要外部的依赖(如不依赖解析树)
- 对所有的词语一视同仁(当然,除了边界词语因为使用窄卷积的方式而忽略了部分信息)
- TDNN的劣势:
- 特征的感受野依赖于 m m m取值的大小, 而当 m m m取值偏大时, 又会给边界词语带来更多的信息损失.
- 使用max-pooling, 将无法区分1和多(whether a relevant feature in one of the rows occurs just one or multiple times)
- 每一次窄卷积之后,输出都会减少,这样会导致各种各样的麻烦
3. Convolutional Neural Networks with Dynamic k-Max Pooling
- 下图给出了作者提出的整体模型的示意图

- 由于窄卷积会带来各种各样的不便, 因此舍去, 转而使用宽卷积
- 由于Max-Pooling的缺陷, 因此使用 k k k-Max Pooling代替, 即在做Pooling的时候, 找出 k k k个最大的结果, 并且保持它原本的顺序输出. 使用 k k k-Pooling可以保持特征原有的顺序, 同时也不会对特定的位置信息敏感.
- 动态的 k k k值计算: 除了最后一层的 k k k值是由问题给出外, 其它各层的 k k k值是通过计算得到的。求 k k k值的问题, 可以理解为, 当你知道了句子的长度之后,你如何通过设定一个 k k k值, 才能使得最后一层的输出恰好满足结果. 如当有一个句子的长度为 s = 18 s=18 s=18时, 要求层数为3, 同时 k t o p = 3 k_{top}=3 ktop=3时, 这时就应该设 k 1 = 12 , k 2 = 6 , k 3 = k t o p = 3 k_{1}=12, k_{2}=6, k_{3}=k_{top}=3 k1=12,k2=6,k3=ktop=3.
- 非线性的特征变换
以输入层为例, 词向量的维度为 d d d, 那我们就需要 d d d个卷积核, 每个卷积核的大小为 m m m, 那么, 在经过卷积核处理之后, 就需要进入"非线性"的激活函数了。文章在处理这个问题时, 使用了一个技巧, 它通过重组 m \mathbf{m} m和 s \mathbf{s} s, 使得原本要 d d d次单独计算的过程, 可以合并成一次来完全运算, 使得可以并行处理, 提高速度(具体过程详见论文) - 在计算机视觉任务中,在同一层中,我们会使用多个卷积核来提取不同的特征, 同样,在这里,我们也可以在同一层里,提取不同的特征。这样我们就可以得到一个4维的张量 m j , k i m^{i}_{j,k} mj,ki, 这里之所以是4维是, 是因为 i i i表示层数, k k k表示该层的每 k k k个卷积核心, 而每个 m m m实际上都是一个二维的 m ∈ R d × m \mathbf{m} \in \mathbb{R}^{d\times m} m∈Rd×m, 因此构成4维的张量.
- Folding: 在前面的过程中,词向量的每个维度都是完全独立的(除了最后的那一层全连接层), 没有交互的. 论文给出了一种折叠的方法, 它在卷积层之前, k k k-max池化层之前使用, 将相邻的两行简单进行相加, 使得原本 d d d维的特征图,减低为 d / 2 d/2 d/2维的特征图.
模型的特点
- 保留了句子中词序信息和词语之间的相对位置;
- 宽卷积的结果是传统卷积的一个扩展,某种意义上,也是n-gram的一个扩展,更加考虑句子边缘信息;
- 模型不需要任何的先验知识,例如句法依存树等,并且模型考虑了句子中相隔较远的词语之间的语义信息。
至此, 模型部分完毕, 实验部分省略…(完)。















 1515
1515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









