







R-CNN CVPR2014

一、优缺点
优点:首次把CNN应用于目标检测,是CNN应用于目标检测的里程碑。
缺点:
1、对每张图片都进行裁剪,裁剪下来的大量图片占用大量的内存
2、输入CNN中,由于全连接层的存在,需要对图片固定大小,对裁剪下来的图片要进行归一化处理,使得图片输入到网络中的大小一致(crop/wrap),会导致图片的信息丢失
3、一张图片上每一个裁剪下来的图片都分别放入CNN中提取特征,裁剪下来的图片存在大量的重叠区域,因此重复提取重复区域的特征,导致大量计算的浪费。
4、训练时间特别长

二、流程图
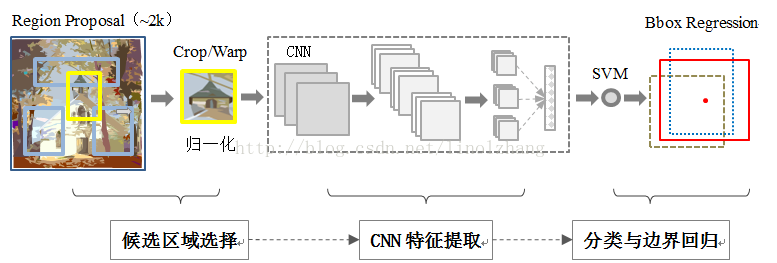

三、整体的过程
1、输入一张图片,在一张图片上用Selective Search方法生成2000个框(bounding box,即为所有可能成为物体的候选区域,即原始图像上裁剪下来的图片,图片的长宽比也是不确定的)。
2、对于不同尺度的框的图片,全部warp到相同的大小(227*227),然后输入到卷积神经网络(AlexNet)提取特征(提取的是4096维的特征)。
3、之后分为两个过程,一个是分类一个是回归。分类即对提取的特征类别进行判断。回归即是对Selective Search提供的框的位置与真实的框的位置进行拟合。
四、Selective Search
1、首先按照一定的规则(如分割方法)形成区域集
2、根据一定的规则对每个区域集与周围相似的区域集进行合并,形成不同尺度的框。、
区域集合并可以根据以下几点去考虑:

3、如下所示:

五、warp的方法

六、模型微调

七、分类
分类即用SVM对bounding box对应的特征进行分类,判断bounding box对应的物体的类别,每一个类别单独训练一个二分类的SVM。每次把特征分别送入多个分类器中进行正负样本的判断 。

八、回归
每一个类别都对应于一个回归模型。让Selected search找到的bounding box和ground truth做一个回归,去拟合ground truth。
8.1、为什么要做bounding box回归
如下图所示,Region proposal 虽然框住的是飞机,但是由于和Ground Truth的IoU<0.5,所以不认为其表示的是飞机。回归可以提高IoU,即提高重合的面积。最后mAP精度提高了3%~4%


上述公式中P为SS搜索到的Bounding box的位置,G为ground truth的位置。
输入:输入为region proposal以及ground truth在Pool5层输出的特征
输出:根据输出的特征,得到(x,y,w, h)。然后对于region proposal得到的(x,y,w,h)去拟合ground truth的(x,y,w,h),求得旋转平移对应得W。
每一个变换都对应了一个目标函数:


九、测试

非极大值抑制作用:测试过程中找到的bounding box可能会很多,很多bounding box可能会重叠,选取最高得分的bounding box,去掉和该bounding box 的IoU大于一定阈值的部分,可去掉冗余。
十、性能















 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









