










目录
四、部署Qwen2.5-7B-Instruct-GPTQ-Int4模型
五、Qwen2.5-14B-Instruct-GPTQ-Int4模型
六、Qwen2.5-32B-Instruct-GPTQ-Int4模型
七、Qwen2.5-32B-Instruct-GPTQ-Int8模型
八、Qwen2.5-72B-Instruct-GPTQ-Int4模型
九、DeepSeek-R1-Distill-Qwen-14B模型
十、DeepSeek-R1-Distill-Qwen-32B模型
一、vLLM介绍
1.github地址: https://github.com/vllm-project/vllm
2.vLLM说明文档:Welcome to vLLM — vLLM
vLLM是用于LLM推理和服务的快速且易于使用的库。
vLLM最初是在加州大学伯克利分校的天空计算实验室开发的,现在已经发展成为一个由学术界和工业界共同贡献的社区驱动的项目。
4.在vLLM命令中vllm serve = python -m vllm.entrypoints.openai.api_server,以下所有的命令中部署命令这两个都可以等价替换。
原因:“vllm serve ”是“python -m vllm.entrypoints.openai.api_server”的简化版,vLLM 0.2.0 及以上都支持“vllm serve ”,若是旧版本,还是要使用“python -m vllm.entrypoints.openai.api_server”。
二、模型参数介绍
| 参数 | 描述 |
| --model | 模型的名字或路径 |
| --trust-remote-code | 是否信任远程代码 |
| --dtype | 模型权重和激活的数据类型,例如自动选择、半精度浮点数、单精度浮点数等。 |
| --max-model-len | 模型上下文长度,未指定时将根据模型配置自动推导。 |
| --tensor-parallel-size | 张量并行副本的数量 |
| --max-parallel-loading-workers | 以多个批次顺序加载模型以避免 RAM 内存不足,特别是对于大模型和张量并行时。 |
| --swap-space | 每个 GPU 的 CPU 交换空间大小(GiB)。 |
| --gpu-memory-utilization | 模型执行器使用的 GPU 内存量的比例,范围从 0 到 1。 |
| --max-num-batched-tokens | 每次迭代中批量 token 的最大数量。 |
| --max-num-seqs | 每次迭代中序列的最大数量。 |
| --api-key | 设置api-key |
| --task | vLLM支持多种模型,例如“Text Generation”对应 --task |
(一)vllm在设置max-num-batched-tokens的时候,可以设置为比32768更大的数吗?
在设置max-num-batched-tokens时,可以设置为比32768更大的数,但需要注意以下几点:
-
内部计算机制:VLLM会根据max_model_len自动计算max-num-batched-tokens。具体计算公式为:max-num-batched-tokens = batch_size × max_model_len。因此,即使你手动设置一个大于32768的值,VLLM也会根据实际的最大序列长度和批处理大小进行计算。
-
硬件限制:设置较大的max-num-batched-tokens值可能会增加内存和显存的使用量。如果硬件资源有限,可能会导致推理速度变慢或出错。因此,建议根据硬件能力合理设置该参数。
-
性能影响:虽然增加max-num-batched-tokens可以处理更多的tokens,但过大的值可能会导致内存溢出或效率下降。通常,VLLM会根据硬件限制自动调整这个参数,以确保最佳性能。
三、API推理服务使用 api-key
我们在访问第三方在线API大模型接口时,一般都需要申请一个 api-key,请求时放在 header 里发送至服务端,但上面客户端请求服务并没有这步验证,为了安全起见可以启动服务的时候指定访问的 api-key 。
vllm serve /data/model/bge-m3/ \
--port 8070 \
--dtype auto \
--served-model-name bge-m3
--task embed \
--trust-remote-code \
--api-key token123cURL 访问示例:
curl --location --request POST 'http://172.16.11.10:8070/v1/embeddings' \
--header 'Authorization: token123' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.103:8070' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "bge-m3",
"input": [
"你好"
]
}'四、部署Qwen2.5-7B-Instruct-GPTQ-Int4模型
vllm serve \
--model /data/model/5-Qwen2.5-7B-Instruct-GPTQ-Int4 \
--served-model-name Qwen2.5-7B-Instruct-GPTQ-Int4 \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 4096 \
--dtype half \
--tensor-parallel-size 1 \
--swap-space 4 \
--max-num-seqs 100cURL请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "Qwen2.5-7B-Instruct-GPTQ-Int4",
"temperature": 0.7,
"top_p":0.9,
"messages": [
{
"role": "system",
"content": "你是一位xxx领域的专家"
},
{
"role": "user",
"content": "介绍xxx领域的问题"
}
],
"max_tokens": 2048,
"stream": True
}'(1)max-model-len
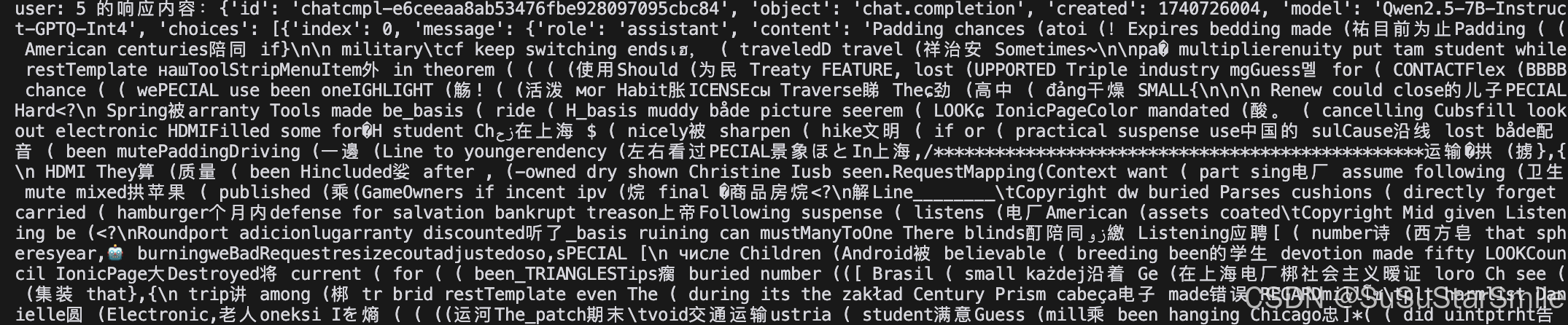
max-model-len不能设为8192和4096都会生成一堆乱码,如下图所示。
(2)tensor-parallel-size
tensor-parallel-size设置数必须能被28整除,因为 Qwen2.5-7B是有28个head。
但是这里tensor-parallel-size只能设为1,设为其他都会报错
(3)max_tokens
由于max-model-len设为4096,那么max_tokens+prompt的长度≤max-model-len的长度。
五、Qwen2.5-14B-Instruct-GPTQ-Int4模型
vllm serve \
--model /data/model/5-Qwen2.5-14B-Instruct-GPTQ-Int4 \
--served-model-name Qwen2.5-14B-Instruct-GPTQ-Int4 \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 8192 \
--dtype half \
--tensor-parallel-size 1 \
--swap-space 4 \
--max-num-seqs 100cURL请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "Qwen2.5-14B-Instruct-GPTQ-Int4",
"temperature": 0.7,
"top_p":0.9,
"messages": [
{
"role": "system",
"content": "你是一位xxx领域的专家"
},
{
"role": "user",
"content": "介绍xxx领域的问题"
}
],
"max_tokens": 4096,
"stream": True
}'六、Qwen2.5-32B-Instruct-GPTQ-Int4模型
vllm serve \
--model /data/model/5-Qwen2.5-32B-Instruct-GPTQ-Int4 \
--served-model-name Qwen2.5-32B-Instruct-GPTQ-Int4 \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 8192 \
--dtype half \
--tensor-parallel-size 8 \
--swap-space 4 \
--max-num-seqs 100cURL请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "Qwen2.5-32B-Instruct-GPTQ-Int4",
"temperature": 0.7,
"top_p":0.9,
"messages": [
{
"role": "system",
"content": "你是一位xxx领域的专家"
},
{
"role": "user",
"content": "介绍xxx领域的问题"
}
],
"max_tokens": 4096,
"stream": True
}'七、Qwen2.5-32B-Instruct-GPTQ-Int8模型
vllm serve \
--model /data/model/5-Qwen2.5-32B-Instruct-GPTQ-Int8 \
--served-model-name Qwen2.5-32B-Instruct-GPTQ-Int8 \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 8192 \
--dtype half \
--tensor-parallel-size 8 \
--swap-space 4 \
--max-num-seqs 100cURL请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "Qwen2.5-32B-Instruct-GPTQ-Int4",
"temperature": 0.7,
"top_p":0.9,
"messages": [
{
"role": "system",
"content": "你是一位xxx领域的专家"
},
{
"role": "user",
"content": "介绍xxx领域的问题"
}
],
"max_tokens": 4096,
"stream": True
}'八、Qwen2.5-72B-Instruct-GPTQ-Int4模型
vllm serve \
--model /data/model/5-Qwen2.5-72B-Instruct-GPTQ-Int4 \
--served-model-name Qwen2.5-72B-Instruct-GPTQ-Int4 \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 8192 \
--dtype half \
--tensor-parallel-size 8 \
--swap-space 4 \
--max-num-seqs 100cURL请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "Qwen2.5-72B-Instruct-GPTQ-Int4",
"temperature": 0.7,
"top_p":0.9,
"messages": [
{
"role": "system",
"content": "你是一位xxx领域的专家"
},
{
"role": "user",
"content": "介绍xxx领域的问题"
}
],
"max_tokens": 4096,
"stream": True
}'九、DeepSeek-R1-Distill-Qwen-14B模型
vllm serve \
--model /data/model/13-DeepSeek-R1-Distill-Qwen-14B \
--served-model-name DeepSeek-R1-Distill-Qwen-14B \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 8192 \
--dtype half \
--tensor-parallel-size 8 \
--swap-space 4 \
--max-num-seqs 100cURL请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "DeepSeek-R1-Distill-Qwen-14B",
"temperature": 0.7,
"top_p":0.9,
"messages": [
{
"role": "user",
"content": "介绍xxx领域的问题"
}
],
"max_tokens": 4096,
"stream": True
}'(1) messages:推理模型不需要system角色,所有的提示词都应放在user中。提示词尽量不限定太多内容,而是由模型进行思考和推理。
(2)temperature:默认设为0.6,推理模型不建议设置太大,尽可能给模型一些发挥空间。
十、DeepSeek-R1-Distill-Qwen-32B模型
python -m vllm.entrypoints.openai.api_server \
--model /data/model/13-DeepSeek-R1-Distill-Qwen-32B \
--served-model-name DeepSeek-R1-Distill-Qwen-32B \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 8192 \
--dtype half \
--tensor-parallel-size 8 \
--swap-space 4 \
--max-num-seqs 100cURL的请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "DeepSeek-R1-Distill-Qwen-32B",
"temperature": 0.7,
"top_p":0.9,
"messages": [
{
"role": "user",
"content": "介绍xxx领域的问题"
}
],
"max_tokens": 4096,
"stream": True
}'(1) messages:推理模型不需要system角色,所有的提示词都应放在user中。提示词尽量不限定太多内容,而是由模型进行思考和推理。
(2)temperature:默认设为0.6,推理模型不建议设置太大,尽可能给模型一些发挥空间。
十一、QwQ-32B模型
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 \
--port 8080 \
--model /data/model/5-QwQ-32B \
--served-model-name QwQ-32B \
--gpu-memory-utilization 0.85 \
--max-num-batched-tokens 32768 \
--max-model-len 8192 \
--dtype half \
--tensor-parallel-size 8 \
--swap-space 4 \
--max-num-seqs 100cURL的请求示例:
curl --location --request POST 'http://172.16.11.10:8888/v1/chat/completions' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8888' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "QwQ-32B",
"temperature": 0.6,
"top_p":0.95,
"messages": [
{
"role": "user",
"content": "你是哪个模型?"
}
],
"stream": false
}'(1) messages:推理模型不需要system角色,所有的提示词都应放在user中。提示词尽量不限定太多内容,而是由模型进行思考和推理。
(2)temperature:默认设为0.6,推理模型不建议设置太大,尽可能给模型一些发挥空间。
十二、部署embedding模型
vllm serve /data/model/bge-m3/ \
--port 8070 \
--dtype auto \
--served-model-name bge-m3
--task embed \
--trust-remote-code \
--api-key token123cURL 访问示例:
curl --location --request POST 'http://172.16.11.10:8070/v1/embeddings' \
--header 'Authorization: token123' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 172.16.11.10:8070' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "bge-m3",
"input": [
"你好"
]
}'十三、vLLM部署后可调用的接口
Available routes are:
Route: /openapi.json, Methods: GET, HEAD
Route: /docs, Methods: GET, HEAD
Route: /docs/oauth2-redirect, Methods: GET, HEAD
Route: /redoc, Methods: GET, HEAD
Route: /health, Methods: GET
Route: /load, Methods: GET
Route: /ping, Methods: GET, POST
Route: /tokenize, Methods: POST
Route: /detokenize, Methods: POST
Route: /v1/models, Methods: GET
Route: /version, Methods: GET
Route: /v1/chat/completions, Methods: POST
Route: /v1/completions, Methods: POST
Route: /v1/embeddings, Methods: POST
Route: /pooling, Methods: POST
Route: /score, Methods: POST
Route: /v1/score, Methods: POST
Route: /v1/audio/transcriptions, Methods: POST
Route: /rerank, Methods: POST
Route: /v1/rerank, Methods: POST
Route: /v2/rerank, Methods: POST
Route: /invocations, Methods: POST(一)API 文档与监控
-
/openapi.json(GET/HEAD)-
作用:提供 OpenAPI 规范文件(JSON 格式),用于自动生成 API 文档。
-
参数:无,直接访问获取规范。
-
-
/docs与/docs/oauth2-redirect(GET/HEAD)-
作用:Swagger UI 交互式文档,可视化调试 API。
-
参数:通过网页交互操作,支持 OAuth2 认证重定向。
-
-
/redoc(GET/HEAD)-
作用:ReDoc 格式的静态 API 文档,适合阅读而非调试。
-
参数:无,直接访问查看文档。
-
-
/health(GET)-
作用:服务健康检查,验证服务是否正常运行。
-
返回:
{"status": "healthy"}或错误状态码。
-
-
/version(GET)-
作用:获取当前 vLLM 服务版本信息。
-
返回:如
{"version": "0.3.0"}。
-
(二)模型管理
-
/v1/models(GET)-
作用:列出已加载的模型列表及其元数据(名称、ID、能力)。
-
返回示例:
{ "object": "list", "data": [ { "id": "DeepSeek-R1-Distill-Qwen-32B", "object": "model", "created": 1742550945, "owned_by": "vllm", "root": "/data/2-model/13-DeepSeek-R1-Distill-Qwen-32B", "parent": null, "max_model_len": 8192, "permission": [ { "id": "modelperm-7d269b10ff4b4abe91e32308a8b395b8", "object": "model_permission", "created": 1742550945, "allow_create_engine": false, "allow_sampling": true, "allow_logprobs": true, "allow_search_indices": false, "allow_view": true, "allow_fine_tuning": false, "organization": "*", "group": null, "is_blocking": false } ] } ] }
-
-
/load(GET)-
作用:可能为自定义扩展,用于动态加载模型(非 vLLM 原生接口)。
-
参数(假设):
model_path(模型路径)、model_name(自定义名称)。
-
(三)文本生成与交互
-
/v1/completions(POST)-
作用:单轮文本生成(非对话场景)。
-
参数:
-
model: 模型名称(必填)。 -
prompt: 输入文本(必填)。 -
max_tokens: 生成的最大 token 数。 -
temperature: 采样随机性(0~2)。 -
top_p: 核心采样概率(0~1)。
-
-
示例请求:
{ "model": "gpt-3.5-turbo", "prompt": "Hello, how are you?", "max_tokens": 50 }
-
-
/v1/chat/completions(POST)-
作用:对话式文本生成(支持多轮交互)。
-
参数:
-
model: 模型名称(必填)。 -
messages: 消息列表,包含role(user/assistant)和content。 -
temperature/top_p: 同completions。
-
-
示例请求:
{ "model": "gpt-4", "messages": [ {"role": "user", "content": "你好!"} ] }
-
(四)分词与编码
-
/tokenize(POST)-
作用:将文本转换为 Token ID 序列。
-
参数:
-
text: 输入文本(必填)。 -
model: 模型名称(可选,默认当前模型)。
-
-
返回示例:
{"tokens": [15496, 220, 278, 1678]}
-
-
/detokenize(POST)-
作用:将 Token ID 序列还原为文本。
-
参数:
-
token_ids: Token ID 列表(必填)。 -
model: 模型名称(可选)。
-
-
返回示例:
{"text": "Hello, world!"}
-
(五)嵌入与语义分析
-
/v1/embeddings(POST)-
作用:生成文本的向量表示(Embedding)。
-
参数:
-
input: 输入文本或文本列表(必填)。 -
model: 嵌入模型名称(如text-embedding-ada-002)。
-
-
返回示例:
{"data": [{"embedding": [0.1, -0.2, ...]}]}
-
-
/pooling(POST)-
作用:可能为自定义扩展,对嵌入向量进行池化操作(如平均池化)。
-
参数(假设):
embeddings(向量列表)、method(池化方法)。
-
(六)评分与评估
-
/score与/v1/score(POST)-
作用:计算文本的困惑度(Perplexity)或对数概率。
-
参数:
-
prompt: 输入文本(必填)。 -
model: 模型名称(必填)。
-
-
返回示例:
{"scores": [-2.34, -1.56]}
-
(七)扩展功能(可能为自定义或集成)
-
/v1/audio/transcriptions(POST)-
作用:音频转文本(类似 Whisper 模型功能)。
-
参数:
-
file: 音频文件(必填)。 -
model: 语音识别模型名称。 -
response_format: 返回格式(如json、text)。
-
-
-
/rerank系列 (POST)-
作用:对文档或结果进行重排序(常用于 RAG 场景)。
-
参数(假设):
-
query: 查询文本。 -
documents: 待排序文档列表。 -
model: 排序模型名称。
-
-
返回示例:
{"scores": [0.8, 0.5], "reranked_docs": [...]}
-
-
/invocations(POST)-
作用:通用模型调用接口(类似 AWS SageMaker 设计)。
-
参数:取决于具体模型需求,通常包含
inputs和model。
-
(八)服务调试与运维
-
/ping(GET/POST)-
作用:简单存活检查,确认服务可达。
-
返回:
{"message": "pong"}。
-
(九)关键总结
-
核心接口:
/v1/completions、/v1/chat/completions、/v1/embeddings是 vLLM 原生支持的生成与嵌入接口。 -
扩展接口:如
/audio/transcriptions、/rerank等可能是用户自定义或集成其他工具(需结合部署环境确认)。 -
参数通用性:大多数 POST 接口需指定
model参数,生成类接口支持temperature、max_tokens等采样控制。
其他可参考:vllm参数解读-天翼云开发者社区 - 天翼云



















 2981
2981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











