







问题背景:
Here is my code: 这是我的代码:
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
import torch
device = "cuda:0"
model_id = "bigscience/bloom-560m"
quantization_config = QuantoConfig(weights="int8")
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float32, device_map=device)
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello my name is"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))When I run, I obtain the next error: 当我运行时,我得到了以下错误:
RuntimeError: CUDA error: operation not supported CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
However, when I check if CUDA is available I obtain:
然而,当我检查CUDA是否可用时,我得到的结果是:
print('-------------------------------')
print(torch.cuda.is_available())
print(torch.cuda.device_count())
print(torch.cuda.current_device())
print(torch.cuda.device(0))
print(torch.cuda.get_device_name(0))
print('Memory Usage:')
print('Allocated:', round(torch.cuda.memory_allocated(0)/1024**3,1), 'GB')
print('Cached: ', round(torch.cuda.memory_reserved(0)/1024**3,1), 'GB')True 1 0 <torch.cuda.device object at 0x7f8bf6d4a9b0> GRID T4-16Q Memory Usage: Allocated: 0.0 GB Cached: 0.0 GB
I run this code on Colab, and I do not have any issues. I also run the code on another machine with another GPU, and it runs as expected.
我在Colab上运行这段代码,没有任何问题。我也在另一台带有不同GPU的机器上运行了这段代码,并且它按预期运行。
The configuration of the machine where I need to run it fails.
需要运行它的那台机器的配置失败了。
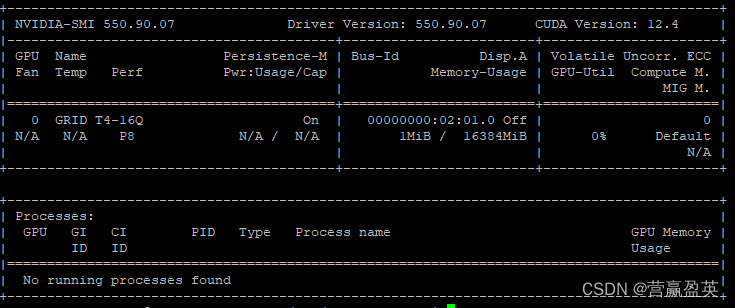
And the libraries:
accelerate 0.31.0 aiohttp 3.9.5 aiosignal 1.3.1 async-timeout 4.0.3 attrs 23.2.0 certifi 2024.6.2 charset-normalizer 3.3.2 datasets 2.20.0 dill 0.3.8 filelock 3.15.1 frozenlist 1.4.1 fsspec 2024.5.0 huggingface-hub 0.23.4 idna 3.7 Jinja2 3.1.4 MarkupSafe 2.1.5 mpmath
1.3.0 multidict 6.0.5 multiprocess 0.70.16 networkx 3.3 ninja 1.11.1.1 numpy 2.0.0 nvidia-cublas-cu12 12.1.3.1 nvidia-cuda-cupti-cu12
12.1.105 nvidia-cuda-nvrtc-cu12 12.1.105 nvidia-cuda-runtime-cu12 12.1.105 nvidia-cudnn-cu12 8.9.2.26 nvidia-cufft-cu12 11.0.2.54 nvidia-curand-cu12 10.3.2.106 nvidia-cusolver-cu12 11.4.5.107 nvidia-cusparse-cu12 12.1.0.106 nvidia-nccl-cu12 2.20.5 nvidia-nvjitlink-cu12 12.5.40 nvidia-nvtx-cu12 12.1.105 packaging 24.1 pandas 2.2.2 pip 24.0 psutil 5.9.8 pyarrow 16.1.0 pyarrow-hotfix 0.6 python-dateutil 2.9.0.post0 pytz 2024.1 PyYAML 6.0.1 quanto 0.2.0 regex 2024.5.15 requests 2.32.3 safetensors 0.4.3 setuptools 65.5.0 six 1.16.0 sympy 1.12.1 tokenizers 0.19.1 torch 2.3.1 tqdm 4.66.4 transformers 4.42.0.dev0 triton 2.3.1 typing_extensions 4.12.2 tzdata
2024.1 urllib3 2.2.2 xxhash 3.4.1 yarl 1.9.4I do not know if this affect you, but the machine is a virtual machine with wmware under a vgpu. Also, I tried to run a simple nn, just for check if the problem was with the transformers library, but I obtained the same error when I tried to locate info on the GPU.
我不知道这是否会影响你,但这台机器是一个在vgpu下的vmware虚拟机。此外,我尝试运行一个简单的神经网络,只是为了检查问题是否出在transformers库上,但是当我尝试在GPU上定位信息时,我得到了相同的错误。
import torch
import torch.nn as nn
dev = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
t1 = torch.randn(1,2)
t2 = torch.randn(1,2).to(dev)
print(t1) # tensor([[-0.2678, 1.9252]])
print(t2) # tensor([[ 0.5117, -3.6247]], device='cuda:0')
t1.to(dev)
print(t1) # tensor([[-0.2678, 1.9252]])
print(t1.is_cuda) # False
t1 = t1.to(dev)
print(t1) # tensor([[-0.2678, 1.9252]], device='cuda:0')
print(t1.is_cuda) # True
class M(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(1,2)
def forward(self, x):
x = self.l1(x)
return x
model = M() # not on cuda
model.to(dev) # is on cuda (all parameters)
print(next(model.parameters()).is_cuda) # TrueTraceback (most recent call last): File “/home/admin/llm/ModelsService/test.py”, line 14, in t2 = torch.randn(1,2).to(dev) RuntimeError: CUDA error: operation not supported CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
by the way here info about my cuda 顺便提一下,这是我关于CUDA的信息
(test310) admin@appdev-llm-lnx1:~/llm/ModelsService$ nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2019 NVIDIA Corporation Built on Sun_Jul_28_19:07:16_PDT_2019 Cuda compilation tools, release 10.1, V10.1.243
问题解决:
ok i will responds myself, if someone has a similar eror, just create the next environment variables:
好的,我自己来回答吧。如果有人遇到类似的错误,只需要创建以下环境变量:
export CUDA_HOME=/usr/local/cuda export PATH=${CUDA_HOME}/bin:${PATH} export LD_LIBRARY_PATH=${CUDA_HOME}/lib64:$LD_LIBRARY_PATH
after that pytorch start working correctly
之后,PyTorch 开始正常工作。

















 5328
5328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











