







 本文介绍了EM算法的背景和基本思想,通过身高分布的例子阐述了EM算法解决混合高斯模型参数估计问题的过程。文章详细解析了E步和M步的迭代更新规则,并证明了EM算法的单调性与收敛性,最后讨论了EM算法在聚类问题中的应用。
本文介绍了EM算法的背景和基本思想,通过身高分布的例子阐述了EM算法解决混合高斯模型参数估计问题的过程。文章详细解析了E步和M步的迭代更新规则,并证明了EM算法的单调性与收敛性,最后讨论了EM算法在聚类问题中的应用。
在讲EM算法之前,我们先从一个例子开始。例如,我们随机抽取了400个人的身高,如果男生为200人,我们可以单独得到一个分布,而女生为200人,也可以同样得到一个分布(假设身高服从高斯分布),如图1。

图1 男生和女生各自的分布直方图(男和女没有混合)

图2 男女混合后的分布直方图
假如,分开来计算分布的参数的话,可以使用最大似然估计来估计。现在我们将抽取的这400人混合在一起,来进行统计,如图2所示,那我们如何估计统计模型的参数呢?而这个统计模型是什么呢?(这个好像需要我们自己去假设,这个需要我们通过统计来观察直方图)从图2看,400人的身高的统计直方图(感觉应该是xx模型(分布)的某种组合,线性的?或是非线性的?),这里我们可以构造一个高斯混合模型,然后使用样本(400个数据样例),利用最大似然来估计模型的参数(好像数理统计是从数据出发,来研究数据之间的概率模型(一种数学模型))。
在运用最大似然估计,估计高斯混合模型的参数的时候,遇到了困难(求导很困难)(见高斯混合模型GMM(理论)),因此我们需要使用EM算法来求解(这么说来,EM这个算法的作用是:相当于绕过了这个困难,达到了同样使高斯混合模型的似然函数达到最优的值,擦,这不是和什么牛顿法,梯度下降法之类的算法功能一样?事实上就是这样的,本质上EM算法也是一种最优算法,相当于坐标上升法(Coordinate ascent),至于为什么,下面在解释)。
下面我们开始讲EM算法。
EM算法意思是“Expectation Maximization”。那它为什么要取这样的名字呢?那肯定是有原因的,比如有一个叫BP的算法,之所以这样命名,是和它算法本身的特点有关的,同样的道理EM算法为什么这样命名,同样和它的算法特点有关。不过如何我们先说一下这种算法的基本思想:对于相互依赖的问题,如先有鸡还是先有蛋的问题,为了解决这种你依赖我,我依赖你的循环依赖问题,我们可以先假设一方的值知道了,接着看另外一方的值怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终就会收敛到一个解。
EM的算法流程:
给定的训练样本是

,样例间独立,我们想找到每个样例隐含的类别z(比如在上面的例子中,从400人的身高中随便挑一个出来,它可能属于男生身高这个分布,也可属于女生身高的那个分布。我们可以假设z=0,为属于男生的分布,z=1,为属于女生的分布,x表示身高(1维)),能使得p(x,z)最大。p(x,z)的最大似然估计如下:

由于这里,我们假设x只是一个维度(如身高),并且假设服从高斯分布,那么对于z=0(男生身高分布)和z=1(女生身高分布)的情况,它们对应的概率密度函数为:

由此,可以假设参数

,实际上:

但是现在的问题又来了,因为要估计使得

最大的参数θ,自然我们会想到对参数θ的各个分量求偏导数即可,可是诸如log(f1+f2+...)类型的函数,求倒数很困难。既然有困难就要想办法,惰性使然(好像人类的文明进步都是由于人类固有的惰性哦),人们在思考,可不可以通过其他的、相对容易的、有可以达到同样目的的方法呢?于是人们想到了EM算法,来使得似然函数达到最优值。
EM是一种解决存在隐含变量优化问题的有效方法。既然不能直接最大化
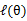
,我们可以不断地建立
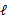
的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
对于每一个样例i(比如张三(第i个抽样对象)的身高为1.81m),让
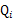
表示该样例隐含变量z(类别:男生身高分布,女生身高分布)的某种分布(概率)(z=0,表示张三身高属于男生那个分布,z=1表示张三身高属于是女生的那个分布,也就是说
(z=0),表示张三属于男生身高分布的概率,
(z=1)表示张三属于女生身高分布的概率),

满足的条件是
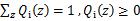
。(如果z是连续性的,那么

是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
可以由前面阐述的内容得到下面的公式:

(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式(其实就是因为似然函数求导难,因此将它进行变形转换(在别处容易求),从而达到求解最大值的目的),考虑到

是凹函数(二阶导数小于0),而且

就是

的期望(回想期望公式中的Lazy Statistician规则)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









