







线性回归,是监督性学习的一种方法,分为单变量和多变量两种。
我的理解,就是希望对于目前已有的数据,或曰训练集,由一个函数H来拟合其输入和输出的关系。
这里的函数实际上叫做”hypothesis”,通常是线性的,输入就是”features”,通常用X来表示,输出用Y来表示。
H通常只能拟合Y,而不是完全正确描述X和Y的关系。
函数H具有若干参数
θ
,我们希望通过一种算法,来自动的选择
θ
的值,使得函数H在输入为X的时候,输出值能最接近结果Y。
相当于有一个标准来”监督修正”学习的效果,这个标准就是已有的输入X和结果Y,这也就是监督性学习的含义。
线性回归常用的算法有梯度下降和正规方程两种。
梯度下降法
定义一个代价函数 J(θ) ,该函数代表了函数 Hθ(x) 拟合数据的误差大小。
当 Hθ(x) 拟合数据的效果很差时, J(θ) 的值就会较大。
通过某种方法来改变 θ ,就可以使得 Hθ(x) 拟合数据的效果变得更好,表现为 J(θ) 的值减小。
J(θ) 的值减小到一定值后会收敛,此时算法结束。
首先来看单变量的线性回归。
1. 单变量
假设训练集中输入为x,输出为y,样本容量为m,并假设
hθ(x)=θ0+θ1∗x
。
定义代价函数(Cost Function)为
J(θ0,θ1)=12m∑i=1m(hθ(x(i))−y(i))2
J
是关于
J
在三维空间中实际上是一个碗形的表面,表面上任意一点的高度即为
站在某一点环顾四周,总会发现有一个方向是”下坡”的方向,并且在该方向下坡最快,将
θ0
和
θ1
的值不断的往下坡的方向进行修正,就可以使得
J
最终到达”碗底”的最小值,此时就达到了收敛状态。
然而,当学习速率
α
太大时,直观的看就是一次迈的步子太大,跳过了最低点,而后面的步子迈得更大,于是就一直在碗上跳来跳去,离碗底越来越远。这样就不会达到收敛状态。
实际编程时,可能要找多次,才能确定一个比较好的学习速率。可以做一个检测,当发现
J
在迭代过程中越来越大时,使得当前学习速率减半,直到
另外,对于比较复杂的代价函数, J 可能不止一个最低点,因此梯度下降法容易陷入局部最优解,而达不到全局最优解,此时需要从多个点进行尝试“下坡”,比较每次尝试最终到达的局部最优解,选出局部最优解中的最优解。
迭代公式
repeat until converge{
θ0=θ0−α∗∑mi=1(hθ(x(i))−y(i))
θ1=θ1−α∗∑mi=1(hθ(x(i))−y(i))∗x(i)}
出于兴(dan)趣(teng),我用C语言实现了一遍,很简单就不做注释了。
void sum(double* xset, double* yset, double theta0, double theta1, double* sum0, double* sum1, int m) { *sum0 = 0; *sum1 = 0; double diff; for(int i = 0;i < m;i++){ diff = theta0 + theta1 * xset[i] - yset[i]; *sum0 += diff; *sum1 += diff * xset[i]; } } //不能使用C语言的abs函数 //因为它的参数和返回值都是int #define abs(a,b) ((a)>(b)?((a)-(b)):((b)-(a))) void gradientdescent(double* xset, double* yset, int m, double alpha) { double theta0 = 0, theta1 = 0; double newtheta0 = 1, newtheta1 = 1; double sum0, sum1; int count = 0; //为了防止不收敛时的死循环,可以在这里限制迭代次数 while(abs(newtheta1,theta1) > 0.000001){ theta0 = newtheta0; theta1 = newtheta1; printf("theta: %f %f ", theta0, theta1); sum(xset, yset, theta0, theta1, &sum0, &sum1, m); newtheta0 = theta0 - alpha * sum0; newtheta1 = theta1 - alpha * sum1; printf("new theta: %f %f\n", newtheta0, newtheta1); count++; } printf("theta: %f %f count: %d", theta0, theta1, count); } int main() { double xset[] = {1,2,3,4,5,6,7,8,9,10}; double yset[] = {2.1, 3.9, 5.8, 8, 10, 12.2, 14.1, 16, 18.1, 19.9}; gradientdescent(xset, yset, sizeof(xset)/sizeof(double), 0.005); return 0; }最后得到的输出为
theta: -0.026007 2.006572 count: 708
其中 2.006572 是斜率,-0.026007 是直线在y轴上的截距
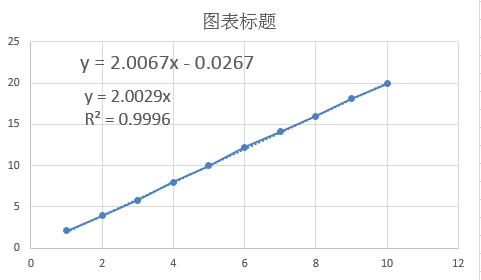
通过Excel计算得到的函数如下图
可以看出两者结果还是相当一致的。
如果使用Octave实现,就比较简单了
function [theta, J_history] = gradientDescent(X, y, theta, alpha, num_iters) m = length(y); % number of training examples J_history = zeros(num_iters, 1); alpha=alpha/m; for iter = 1:num_iters theta1 = theta(1) - alpha * sum(X * theta - y); theta2 = theta(2) - alpha * sum((X * theta - y).*X(:,2)); J_history(iter) = computeCost(X, y, theta); end end2. 多变量
现实中遇到更多的是多变量的情况,也就对于 (x1,x2,⋯,xn) 和输出y,希望找到一个向量 θ=[θ1,θ2,⋯,θn] ,并令 Hθ(x)=θ1x1+θ2x2+⋯+θnxn ,使用 H 来拟合Y。
仍然定义一个函数
J(θ) ,表示函数 Hθ(x) 对于训练集的拟合程度。当拟合程度差时, J 的值较大。
此时x 从单个值变成了向量,但是 J 的形式变化并不大。
J(θ)=12m∑i=1m(hθ(x(i))−y(i))2=12m∑i=1m(θTx−y)2 从单变量到多变量,代码更加简洁。
代码如下,关键部分只有一行代码。function [theta] = gradientDescentMulti(X, y, theta, alpha, num_iters) alpha_avg = alpha/length(y); for iter = 1:num_iters theta = theta - alpha_avg * (X' * (X*theta-y)) end end















 7923
7923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









