







 文章介绍了文本数据分析在情感分析任务中的重要性,包括标签数量分布、句子长度分布、正负样本长度散点图、词汇总数统计和高频形容词词云等预处理步骤。通过这些分析,可以识别数据不平衡、异常点和高频词汇特征,为模型训练提供指导。
文章介绍了文本数据分析在情感分析任务中的重要性,包括标签数量分布、句子长度分布、正负样本长度散点图、词汇总数统计和高频形容词词云等预处理步骤。通过这些分析,可以识别数据不平衡、异常点和高频词汇特征,为模型训练提供指导。
目录标题
1、概述
文本数据分析的作用:
文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 并指导之后模型训练过程中一些超参数的选择.
常用的几种文本数据分析方法:
- 标签数量分布(不同标签数据的分布)
- 句子长度分布(分是短文本or长文本,根据长度不同选择不同模型)
数据的句子长度分布:分析句子在哪个部分的分布比较集中,有助于后面句子截断过程中超参数的选择
绘制训练集和验证集的散点图的分布:作用:定位异常数据,帮助后期的人工语料的审核工作 - 词频统计与关键词词云(可视化)
数据-验证码1111
数据展示:

数据说明:data.csv中的数据内容共分为2列, 第一列数据0或1, 代表每条文本数据是积极或者消极的评论, 0代表消极, 1代表积极.第二列是评论文本;
2、文本预处理
2.1 数据的标签数量分布
# 导入必备工具包
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# 设置显示风格
plt.style.use('fivethirtyeight')
#pandas读取数据
data = pd.read_csv("E:/shuju/data.csv",encoding='gbk')
#获取数据标签数量分布
sns.countplot("label", data=data) #label列计数
plt.title("data")
plt.show()
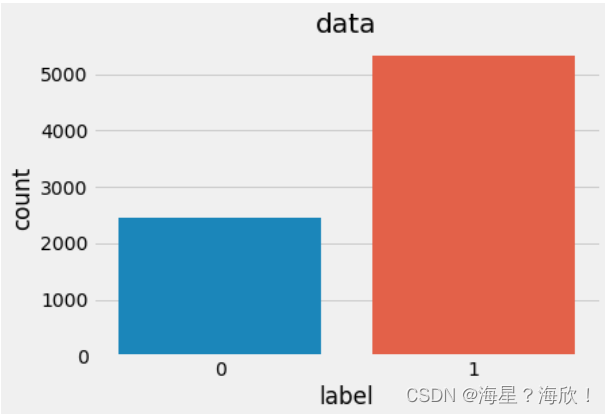
结论:积极文本数据量多于消极文本数据量的两倍
注意:在后续的深度学习模型评估中,一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右, 则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减.本次的样本中正负样本不太均衡,但只做文本预处理,可以不用进行数据增强。
2.2 句子长度分布
句子长度分析,方便后续的截断操作
data.isnull().sum()#查看空值
#空值填充一下,否则后面len()报错
data 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









