









前面介绍了各种配置,以及查询语法,这里通过图形界面,简单的讲解一下solr的查询。
仅通过截图来介绍一些最基本的用法:
首先打开主界面,点击Query
直接点击Excute Query按钮
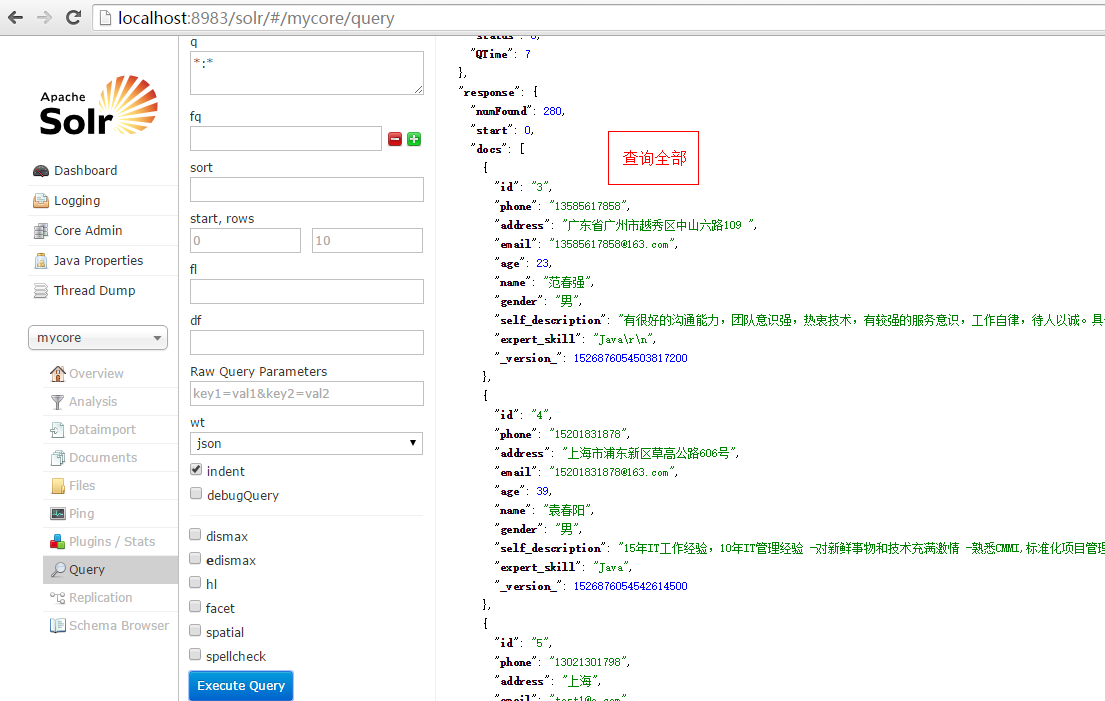
输入条件q进行查询
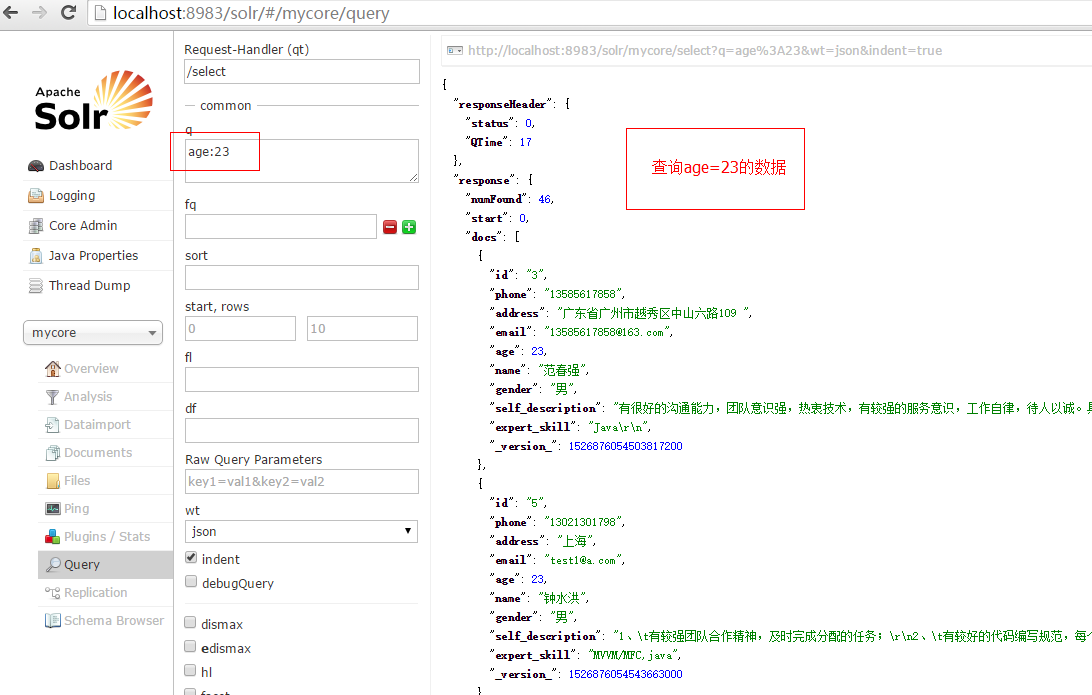
使用fq进行查询,注意这里的keyword是用来检索的字段,他包含name、address、gender、expert_skill,这几个属性,所以我搜索“海”能够查询出来有海字的记录
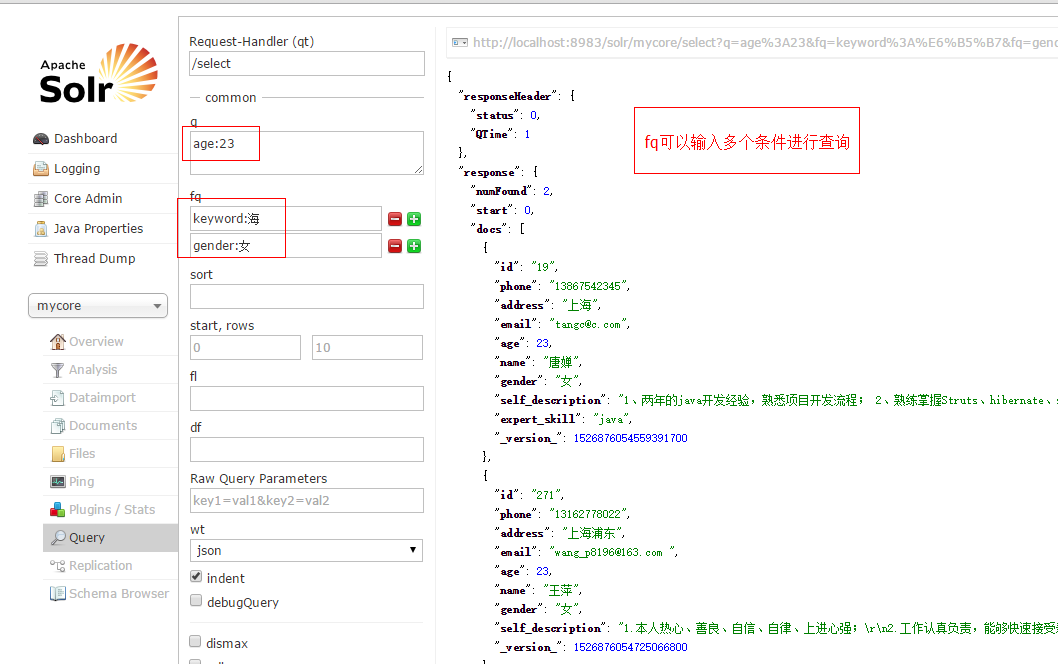
使用sort排序
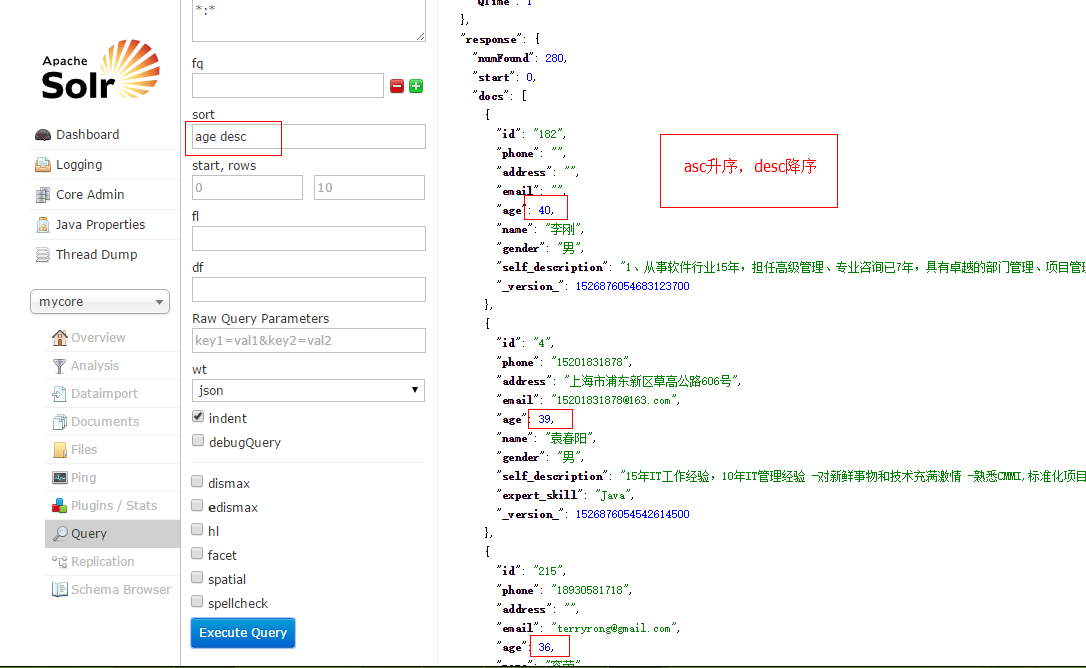
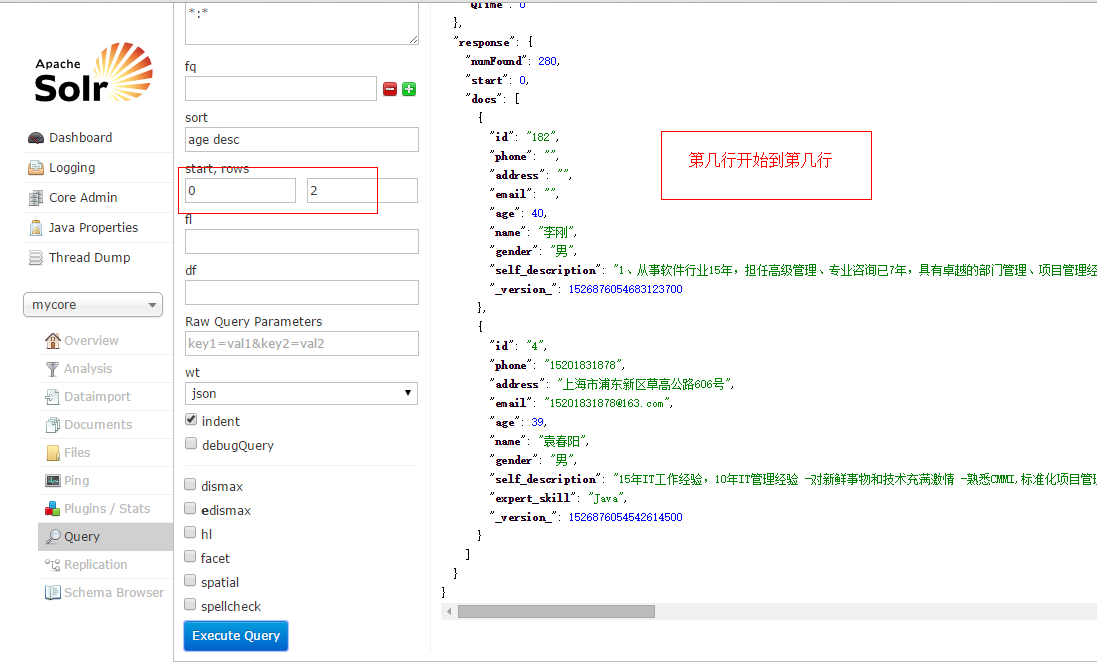
使用start和rows,一般是分页的时候使用的
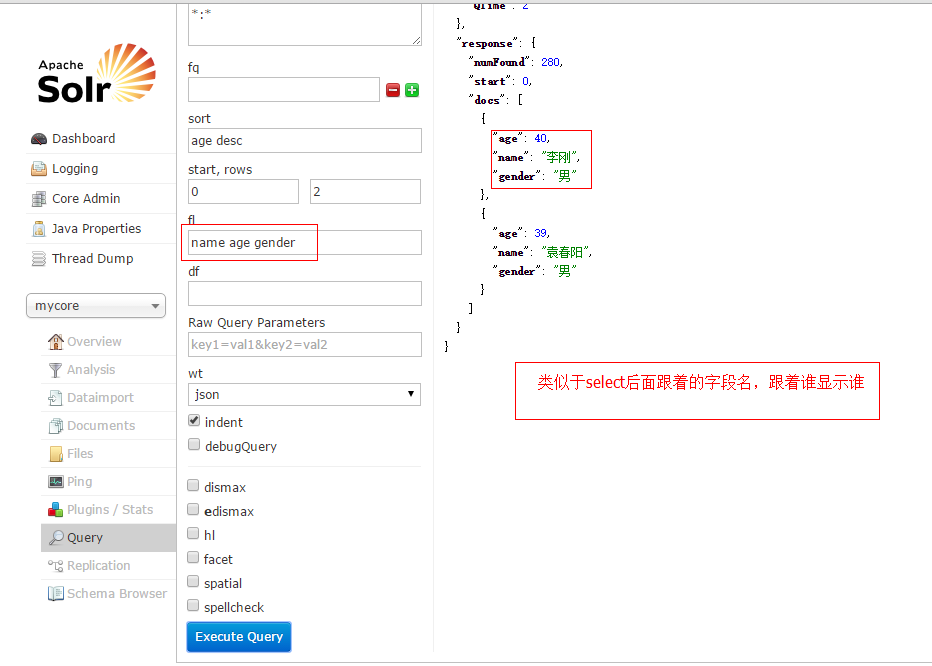
使用fl决定查询哪些字段
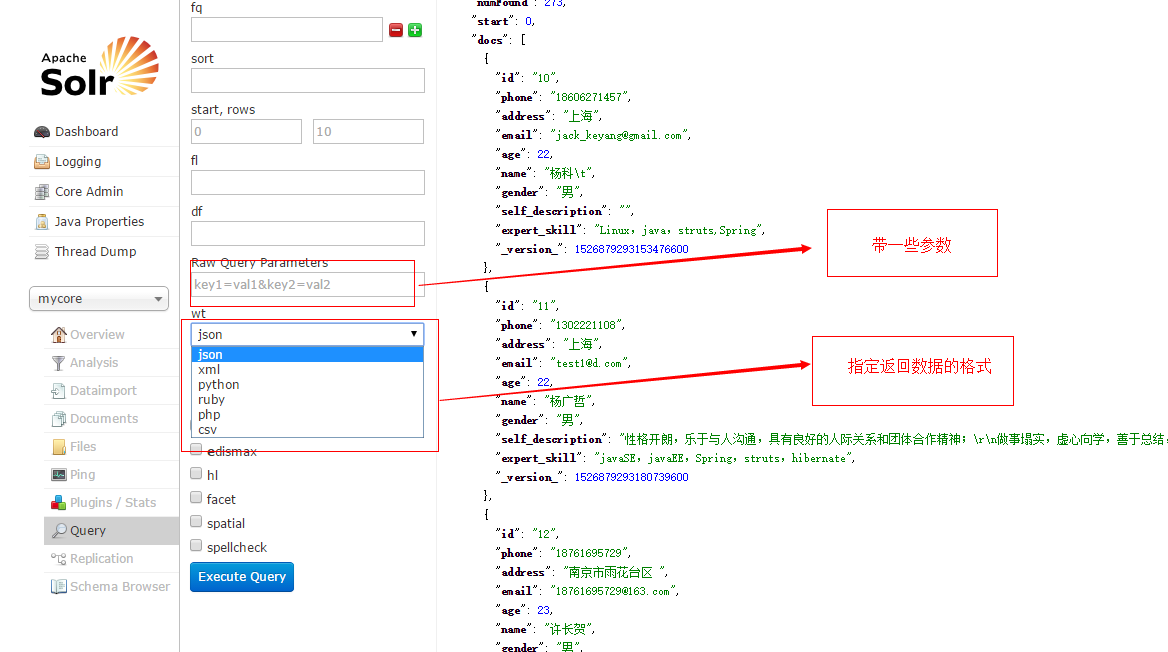
df – 默认的查询字段,一般默认指定
ok,最简单的query应用,就先说这些
下面我先给大家贴一下我的solr的基本配置。
schema.xml
<schema name="example core zero" version="1.1">
<fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<!-- 定义一个分词器 -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- general -->
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="type" type="string" indexed="true" stored="true" multiValued="false" />
<field name="name" type="string" indexed="true" stored="true" multiValued="false" />
<field name="core0" type="string" indexed="true" stored="true" multiValued="false" />
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="age" type="int" indexed="true" stored="true" multiValued="false"/>
<field name="email" type="string" indexed="true" stored="true" multiValued="false"/>
<field name="phone" type="string" indexed="true" stored="true" multiValued="false"/>
<field name="gender" type="string" indexed="true" stored="true" multiValued="false"/>
<field name="address" type="string" indexed="true" stored="true" multiValued="false"/>
<field name="expert_skill" type="string" indexed="true" stored="true" multiValued="false"/>
<field name="self_description" type="string" indexed="true" stored="true" multiValued="false"/>
<!-- 用于做搜索的字段 -->
<field name="keyword" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- 可供搜索的属性 -->
<copyField source="name" dest="keyword"/>
<copyField source="gender" dest="keyword"/>
<copyField source="expert_skill" dest="keyword"/>
<copyField source="address" dest="keyword"/>
<!-- field to use to determine and enforce document uniqueness. -->
<uniqueKey>id</uniqueKey>
<!-- field for the QueryParser to use when an explicit fieldname is absent -->
<defaultSearchField>name</defaultSearchField>
<!-- SolrQueryParser configuration: defaultOperator="AND|OR" -->
<solrQueryParser defaultOperator="OR"/>
</schema>注意:schema.xml中所配置的stopwords.txt和synonyms.txt可以去solr-4.10.4\example\solr\collection1\conf目录下找然后拷贝到自己的solr里,本文是拷贝到mycore\conf下。
solrconfig.xml
只在原有的基础上追加了以下代码
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>data-config.xml
这是个自己创建的文件,与schema.xml、solrconfig.xml在同一个目录
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/simplehr" user="root" password="123456" batchSize="-1" />
<document name="resumeDoc">
<entity name="resume" pk="id"
query="select id,name,age,email,phone,gender,address,expert_skill,self_description from resume where id >= ${dataimporter.request.id}">
</entity>
</document>
</dataConfig>















 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











