







一、摘要

论文:Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs,https://arxiv.org/abs/2406.16860
主页:https://cambrian-mllm.github.io/
代码:https://github.com/cambrian-mllm/cambrian
本文研发团队谢赛宁与LeCun秉持的观念是视觉表征是MLLM能力的突破口,做好MLLM需要回归视觉,而不是一味的增强LLM。研究的直觉是,寒武纪时期生物靠着以视觉为核心的感知能力,完成了对周围环境的理解并在此基础上生存与进化了下来。并且直至现在也表明依然可以靠单纯的视觉对物理世界进行理解并做出高效准确的行为。包括李飞飞、何凯明等学者也是非常认可这样的直觉,所以现在视觉学者们正在号召并躬身进行相应的研发创新,相信不久的未来会有更多有影响力的工作出来。本文介绍了Cambrian-1,这是一组以视觉为中心的多模态大型语言模型(MLLMs)系列,旨在通过大型语言模型(LLMs)和视觉指令调整来评估不同的视觉表示,提供对模型和架构的新见解。Cambrian-1通过实验评估了20多种视觉编码器,并对现有的MLLM基准进行了批判性检查,提出了一个新的视觉中心基准CV-Bench,以改善视觉基础。该方法对比4月份港中文贾佳亚团队的Mini-Gemini: 探索多模态视觉语言模型的新境界又提升了不少性能。
二、算法贡献
a.)视觉编码观察
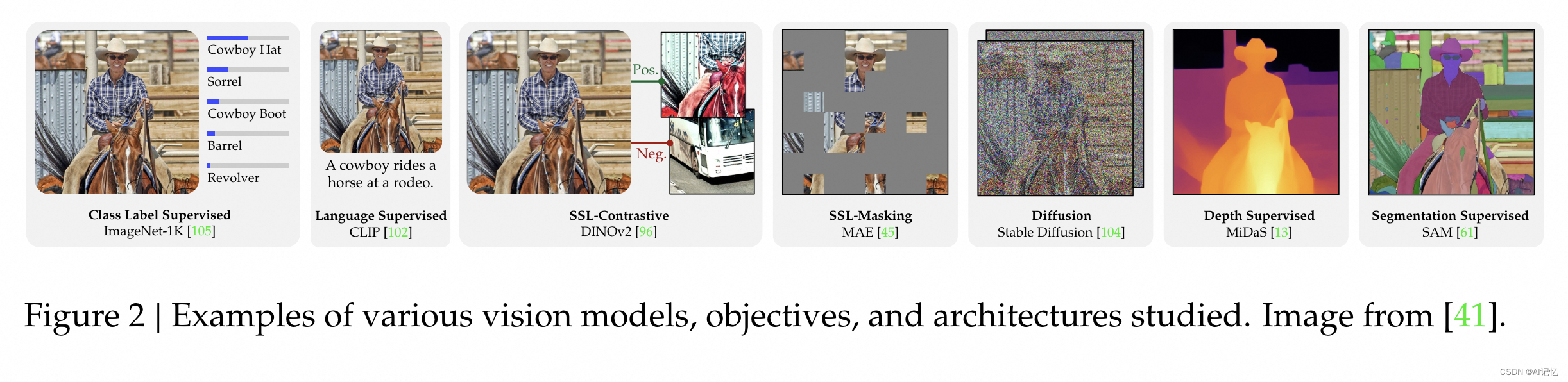
如上图所示,首先简单回顾了下各类视觉任务上的SOTA方法以及相应的方法概览,除了做致敬外,直觉是不同的视觉编码器混合在一起会有性能收益。结果如下图表所示:
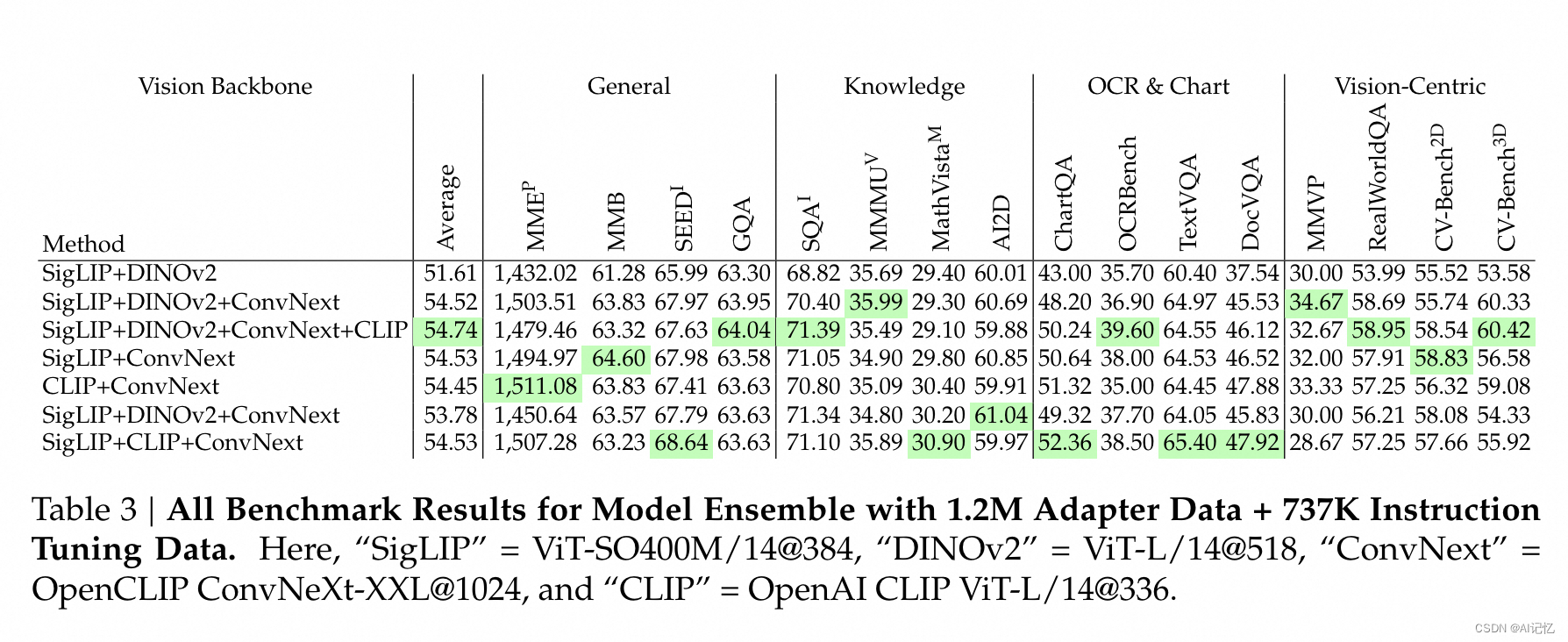
b.)视觉特征聚合(SVA)
如何有效聚合多个视觉编码器特征成为核心,首先通过交叉注意力层与多个视觉编码器特征交互,其次在LLM的每个Block后都引入SVA。如下图所示: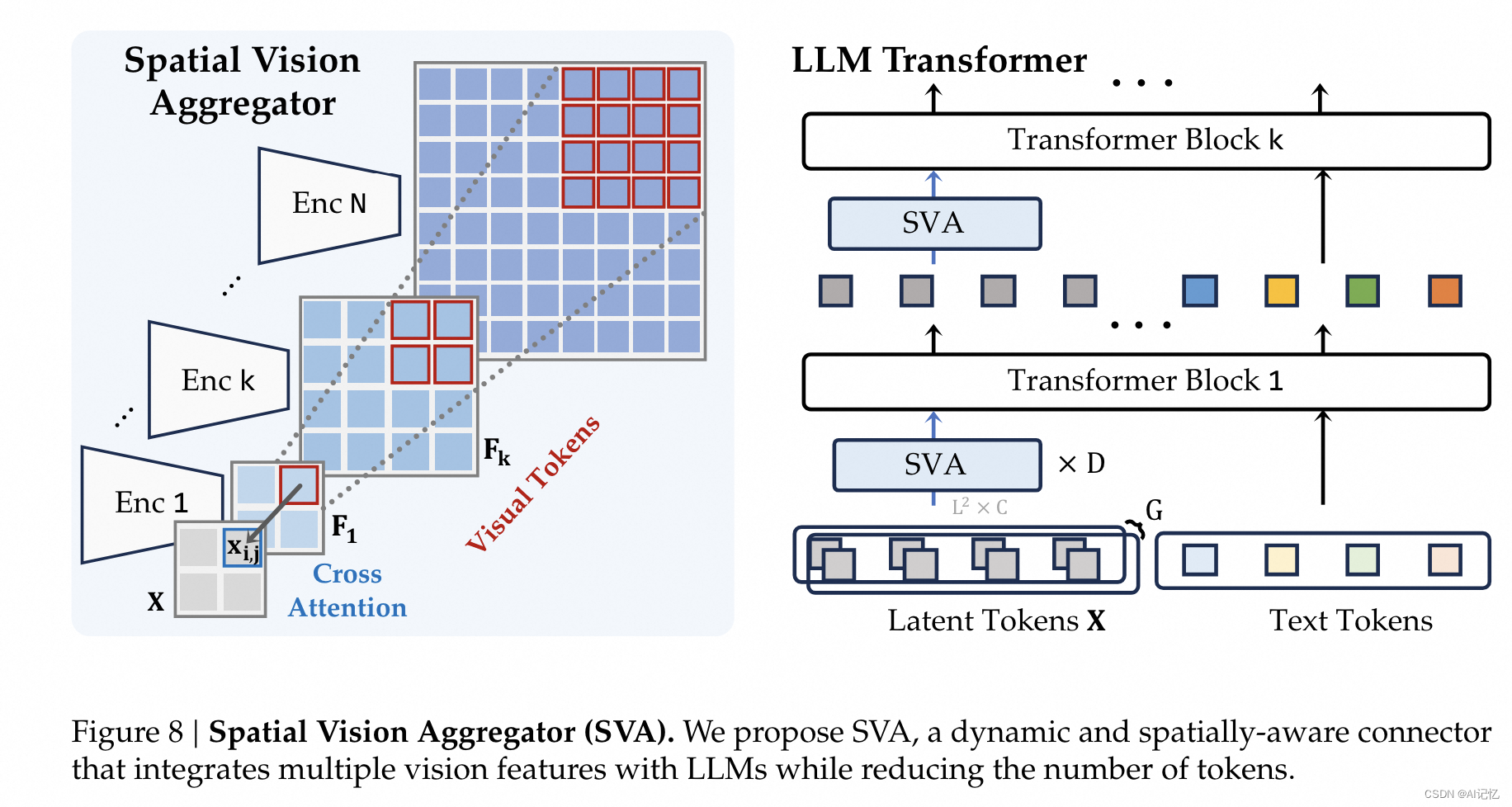
c.)基准数据建设
左图通过开关视觉能力发现不同数据集对视觉依赖不同,有些数据集甚至不需要视觉能力输入,萌生了当前基准测试集有不同类型的基本构思。右图对各MLLM的基准测试集进行分析,得到了四大不同的基准类型:蓝色(通用)、黄色(知识)、红色(图表与OCR)和蓝色(以视觉为中心)。
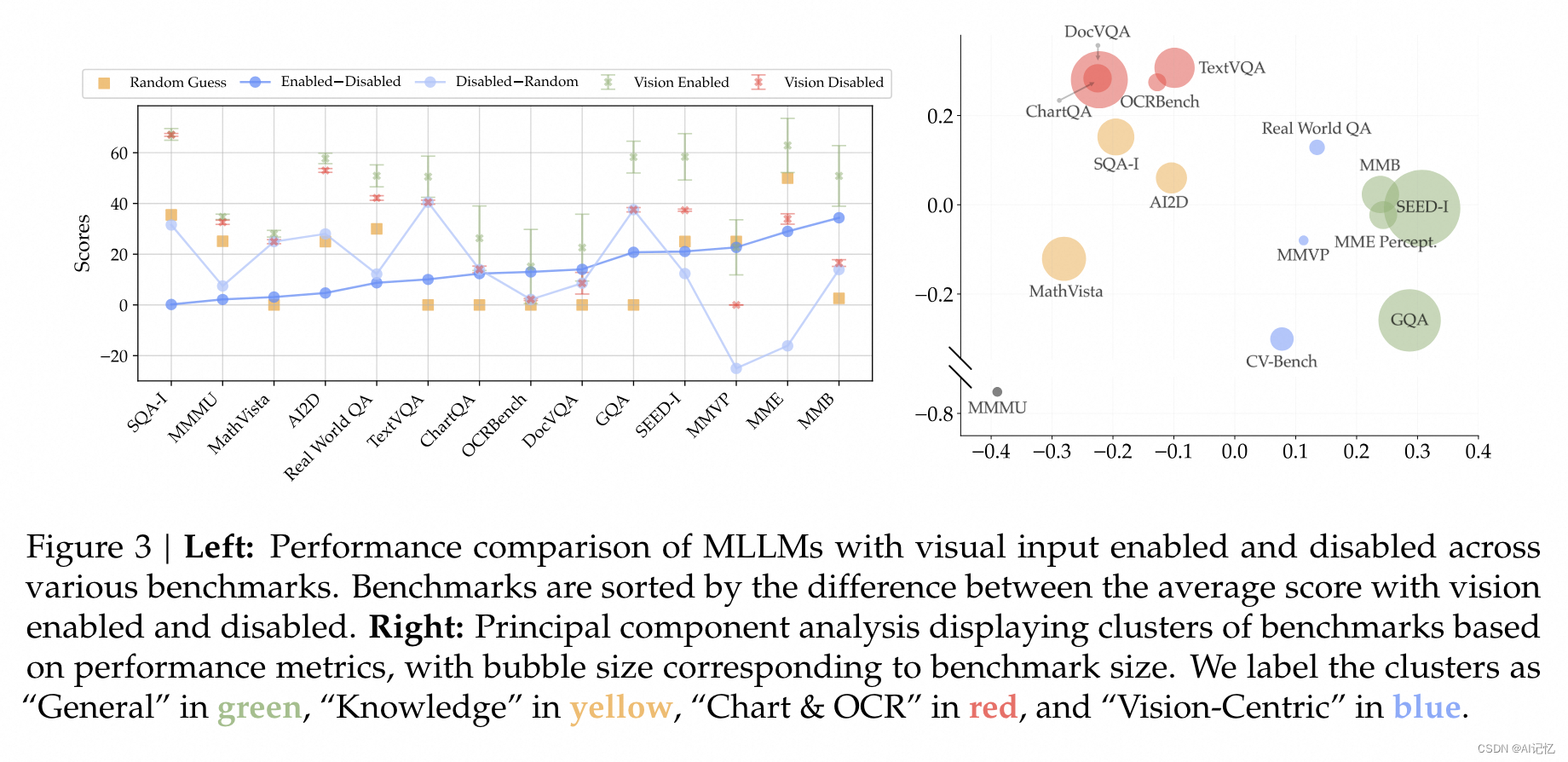
上图中清晰看到视觉为中心的基准测试规模太小,接着作者通过如下图所示指导方法将传统视觉数据集转换为VQA的巧妙方式,提出了以视觉为中心的MLLM基准测试集(CV-Bench)。
d.)指令微调数据
另外本文也着重做了指令微调数据的整理,还简易画出了数据制备的流程图。有需要更多细节的同学可以查看原文。原文中还有诸多关于一些个直觉和结论的观察性实验的分析,是较为严谨的实验科学。也提及了模型对话能力遗忘问题及其解决方法,强烈建议做MLLM训练或者微调的同学仔细精读原文,会有很多收获。
三、实验结果
a.)定性实验结果
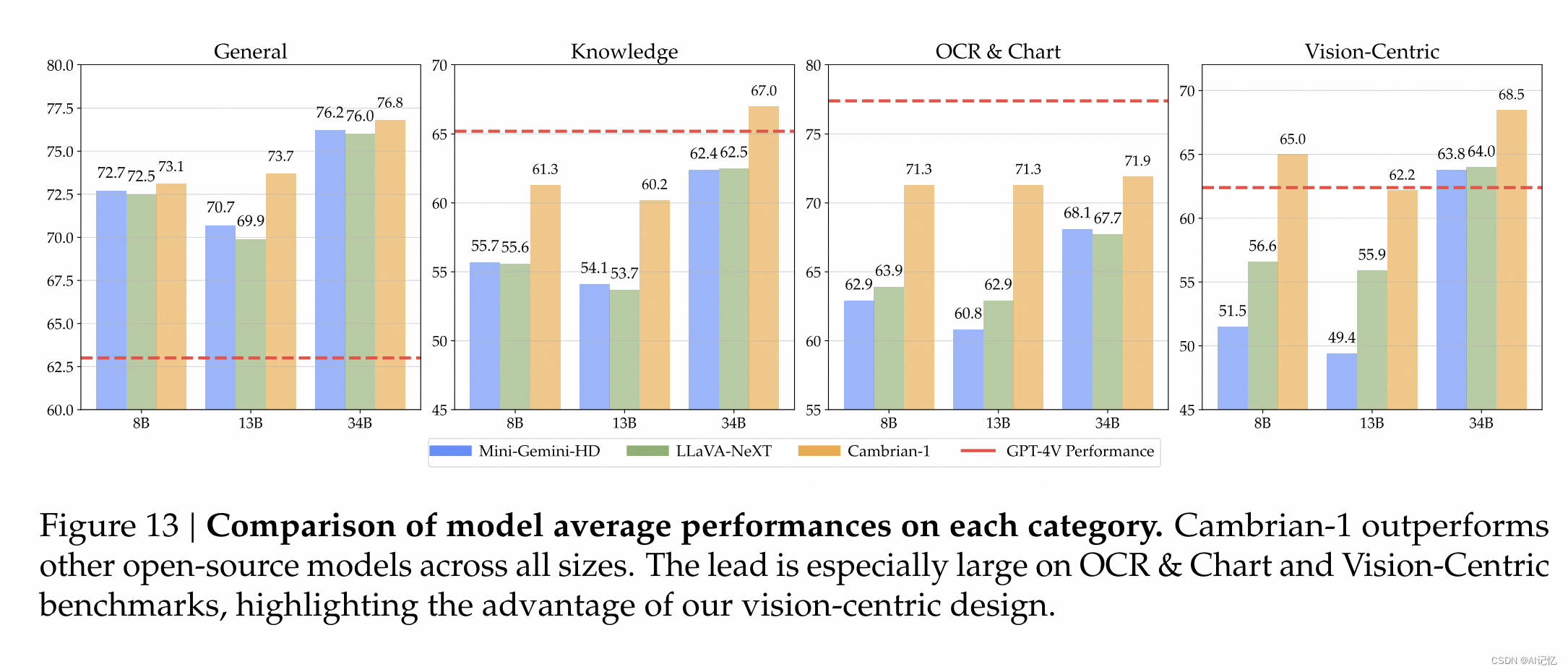
Cambrian-1在多个基准测试中取得了最先进的性能,并且在视觉中心任务中表现出色。
b.)定量实验结果
在CV-Bench基准测试中,Cambrian-1模型在属性识别和空间关系推理任务上的表现显著优于其他系统。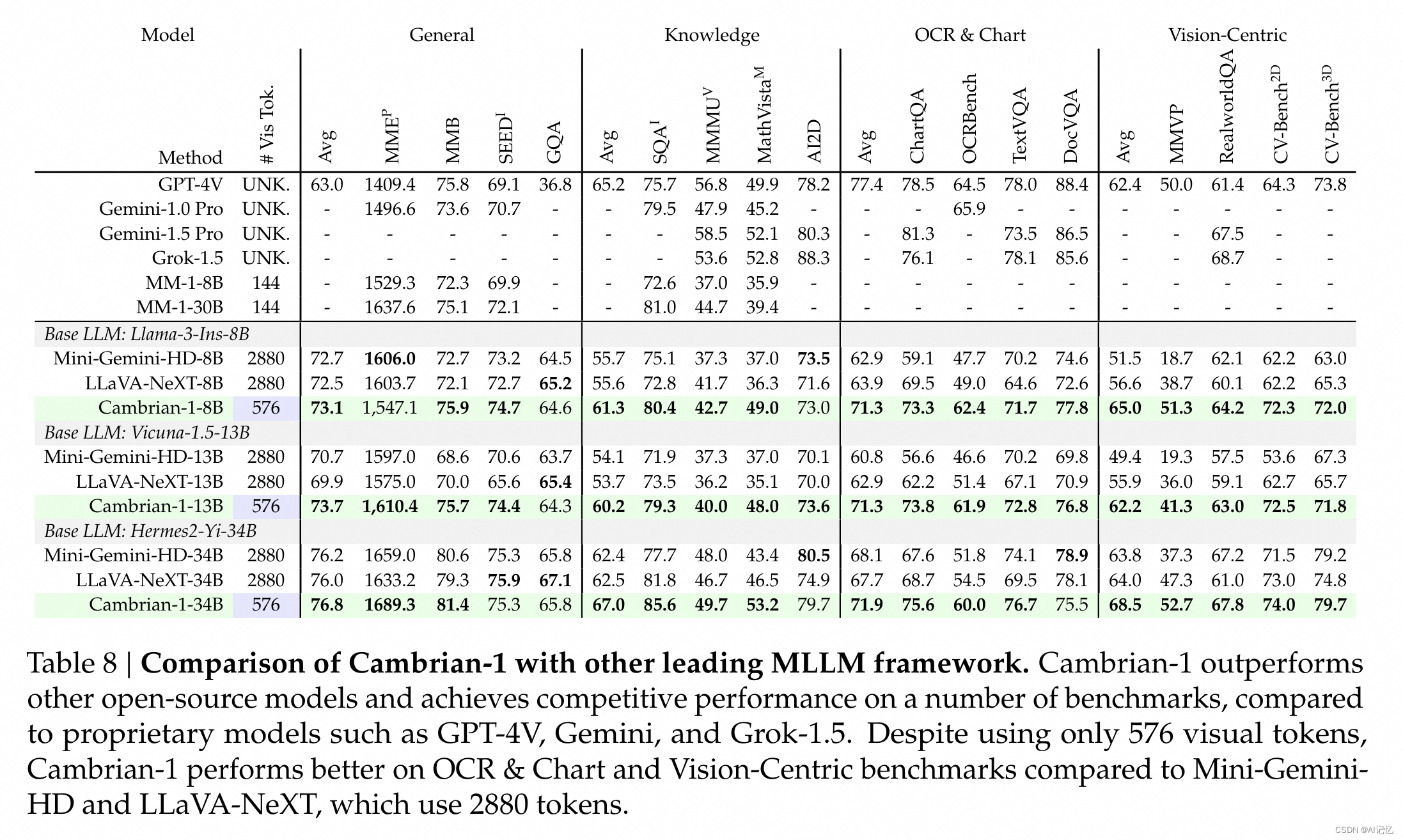
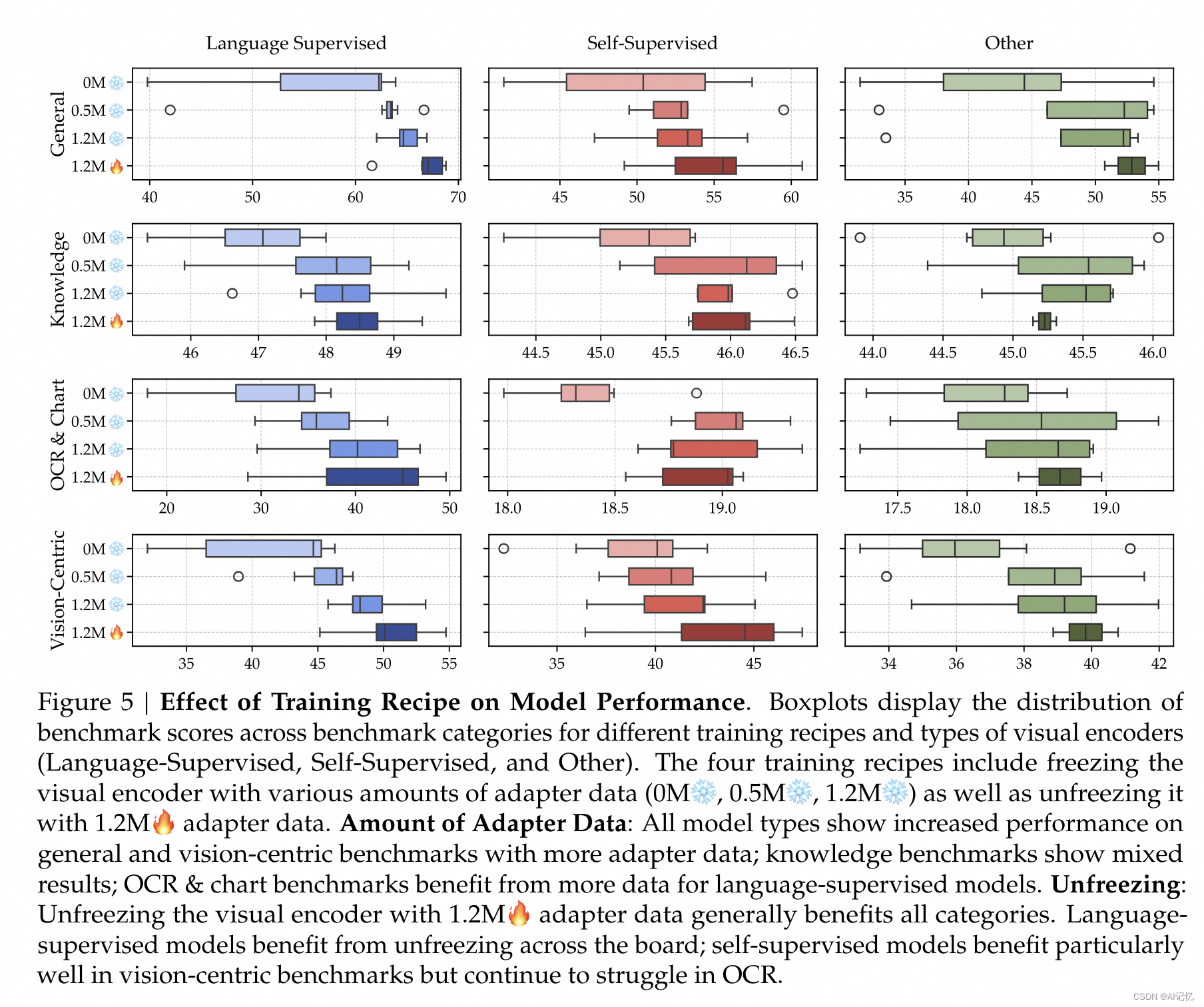
c.)Ablation Study&Limitation
消融研究验证了SVA设计和指令调整策略的有效性,通过对比实验展示了不同配置对模型性能的影响。存在的缺陷是Cambrian-1模型主要针对自然图像和常见对象,要扩展到文档、图表图像、长视频或开放世界环境,需要额外的训练和新算法设计。



















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











