






最近在复现一篇文章中关于其机器学习可解释性以及可视化特征重要度中了解到了一个库包eli5,其项目官方链接戳此处:
ELI5![]() https://github.com/facebookresearch/ELI5
https://github.com/facebookresearch/ELI5
eli5包的相关介绍这里就不多叙述了,简单来说就是通过一个机器学习模型,可以是线性模型、树模型等将特征数据拟合之后输出特征的重要性,帮助理解那些特征对模型最为重要,可以帮助特征的选择。
本以为是一个平平无奇的调包任务,麻木的通过pip下载eli5,该环节没有任何的问题,非常的顺利的看到了Successfully。但是当我导入包的时候意外发生了,直接发生了如下错误,这一大串的红色给我整蒙了,第一次碰到因为导入一整个库包就直接报错的。
import eli5---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[17], line 1
----> 1 import eli5
File c:\Users\AppData\Local\Programs\Python\Python311\Lib\site-packages\eli5\__init__.py:13
6 from .formatters import (
7 format_as_html,
8 format_html_styles,
9 format_as_text,
10 format_as_dict,
11 )
12 from .explain import explain_weights, explain_prediction
---> 13 from .sklearn import explain_weights_sklearn, explain_prediction_sklearn
14 from .transform import transform_feature_names
17 try:
File c:\Users\AppData\Local\Programs\Python\Python311\Lib\site-packages\eli5\sklearn\__init__.py:3
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import
----> 3 from .explain_weights import (
4 explain_weights_sklearn,
5 explain_linear_classifier_weights,
6 explain_linear_regressor_weights,
7 explain_rf_feature_importance,
8 explain_decision_tree,
9 )
10 from .explain_prediction import (
11 explain_prediction_sklearn,
12 explain_prediction_linear_classifier,
13 explain_prediction_linear_regressor,
14 )
15 from .unhashing import (
16 InvertableHashingVectorizer,
17 FeatureUnhasher,
18 invert_hashing_and_fit,
19 )
File c:\Users\AppData\Local\Programs\Python\Python311\Lib\site-packages\eli5\sklearn\explain_weights.py:78
73 from eli5.transform import transform_feature_names
74 from eli5._feature_importances import (
75 get_feature_importances_filtered,
76 get_feature_importance_explanation,
77 )
---> 78 from .permutation_importance import PermutationImportance
81 LINEAR_CAVEATS = """
82 Caveats:
83 1. Be careful with features which are not
(...)
90 classification result for most examples.
91 """.lstrip()
93 HASHING_CAVEATS = """
94 Feature names are restored from their hashes; this is not 100% precise
95 because collisions are possible. For known collisions possible feature names
(...)
99 the result is positive.
100 """.lstrip()
File c:\Users\AppData\Local\Programs\Python\Python311\Lib\site-packages\eli5\sklearn\permutation_importance.py:7
5 import numpy as np
6 from sklearn.model_selection import check_cv
----> 7 from sklearn.utils.metaestimators import if_delegate_has_method
8 from sklearn.utils import check_array, check_random_state
9 from sklearn.base import (
10 BaseEstimator,
11 MetaEstimatorMixin,
12 clone,
13 is_classifier
14 )
ImportError: cannot import name 'if_delegate_has_method' from 'sklearn.utils.metaestimators' (c:\Users\AppData\Local\Programs\Python\Python311\Lib\site-packages\sklearn\utils\metaestimators.py)不过报错已经发生,那我们就从上往下详细看一下报错内容吧。首先看到报错直接出在了import 部分,再往下看发现是库包中的sklearn的相关依赖的导入错误。顺着看到最后发现是permutation_importance.py 模块中 if_delegate_has_method 的导入问题。此时我们不难猜到报错原因是sklearn与eli5之间的版本兼容问题, 貌似是由于sklearn 弃用了 if_delegate_has_method 装饰器并将其替换为另一个名为 available_if 的装饰器导致的导入错误。
既然问题原因明了,其解决方法通过查询eli5项目的issue发现一位大佬的回答,话不多说开始尝试。首先根据报错反馈将permutation_importance.py的路径复制下来黏贴到资源管理器中,会直接打开该Python文件。将第七行导入项的 if_delegate_has_method
from sklearn.utils.metaestimators import if_delegate_has_method更改为:
from sklearn.utils.metaestimators import available_if然后在permutation_importance.py模块中往下翻,找到使用了 if_delegate_has_method 装饰器的代码
@if_delegate_has_method(delegate='wrapped_estimator_')
def score(self, X, y=None, *args, **kwargs):
return self.wrapped_estimator_.score(X, y, *args, **kwargs)
@if_delegate_has_method(delegate='wrapped_estimator_')
def predict(self, X):
return self.wrapped_estimator_.predict(X)
@if_delegate_has_method(delegate='wrapped_estimator_')
def predict_proba(self, X):
return self.wrapped_estimator_.predict_proba(X)
@if_delegate_has_method(delegate='wrapped_estimator_')
def predict_log_proba(self, X):
return self.wrapped_estimator_.predict_log_proba(X)
@if_delegate_has_method(delegate='wrapped_estimator_')
def decision_function(self, X):
return self.wrapped_estimator_.decision_function(X)
将其改为相应的 available_if 装饰器:
@available_if(_estimator_has('wrapped_estimator_'))
def score(self, X, y=None, *args, **kwargs):
return self.wrapped_estimator_.score(X, y, *args, **kwargs)
@available_if(_estimator_has('wrapped_estimator_'))
def predict(self, X):
return self.wrapped_estimator_.predict(X)
@available_if(_estimator_has('wrapped_estimator_'))
def predict_proba(self, X):
return self.wrapped_estimator_.predict_proba(X)
@available_if(_estimator_has('wrapped_estimator_'))
def predict_log_proba(self, X):
return self.wrapped_estimator_.predict_log_proba(X)
@available_if(_estimator_has('wrapped_estimator_'))
def decision_function(self, X):
return self.wrapped_estimator_.decision_function(X)此时会发现装饰器中的 _estimator_has 函数未被定义,此时只需在上述代码的前面定义如下函数(注意缩进):
def _estimator_has(attr):
def check(self):
return hasattr(self.estimator, attr)
return check然后保存该模块即可。
接下来让我们尝试验证改动是否有效。执行下述代码:
import eli5
from eli5.sklearn import PermutationImportance # 排列重要性
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100,bootstrap=True,max_features='sqrt') # bootstrap
# fit data
model.fit(X_train,y_train)
perm = PermutationImportance(model,random_state=10).fit(X_test,y_test)
eli5.show_weights(perm,feature_names=X_test.columns.tolist())
成功输出相关的特征重要性,导入成功!
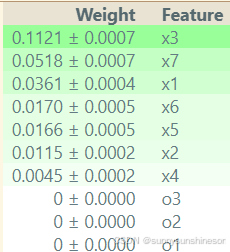
通过上述输出对比论文结果,对比一致说明改动有效,不过eli5项目已经基本上没人维护了,差不多已经凉了哈哈哈,如果觉得麻烦也可以放弃使用eli5转而去使用shap库也是可以的。
第一次写Blog,有不好的地方欢迎各位评论区指正,祝愿大家前程似锦!

















 2853
2853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









