






此文章翻译至机器学习的一章讲义:
http://www.ics.uci.edu/~dramanan/teaching/ics273a_winter08/lectures/lecture14.pdf
损失函数。
我们能得到一般化的损失函数表达式,如下(14.1),在(14.1)中,我们注意到损失函数有两部分组成:损失项和规则项。我们将会在接下来的章节中介绍这两部分。
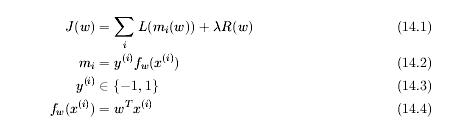
一、损失项
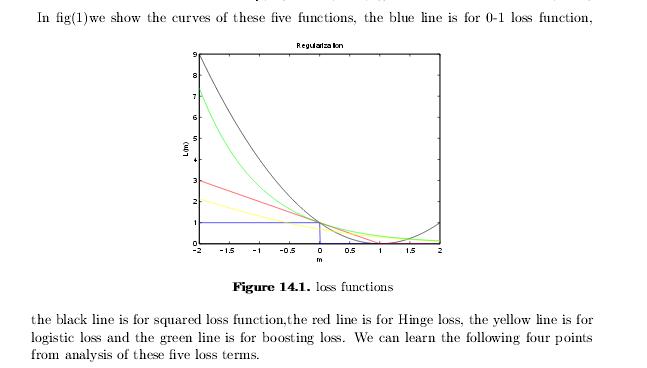
在这一节中,我们使用5个例子来讲述损失项。gold standard(ideal case)、hinge(软间隔SVM)、log(逻辑回归,交叉熵错误),squared loss(线性回归)、boosting。
1、首先来看看gold standard的损失函数。我们已经用它来评测我们的分类器了–我们通过计算他们产生的错误的个数。这也叫做“0-1”损失,或者L01
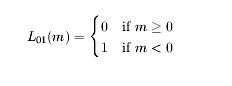
2、针对软间隔的SVM,我们使用Lhinge 来表示hinge loss。
3、再看看log loss。这和交叉熵损失函数是一样的,用来训练一个逻辑回归模型。
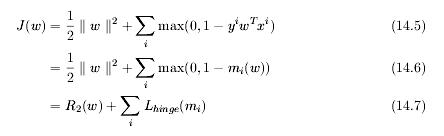
4、线性回归,有一个平方损失项。我们用L2来表示。我们从图1可以知道,平方项比gold stand要高很多,所以这是一个不很好的函数。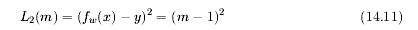
5、最后,看看boosting算法。它可以看做一个针对指数损失项的贪婪优化。
选择事项:
1、Lhinge,Llog在训练数据中,对于错误/噪声不敏感
2、所有的损失函数是L01的凸替换。这意味着我们仍然能使用我们通用的边界。
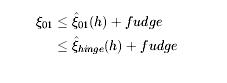
3、如果我们的目标不是在x_new, y_new上最小化0-1损失函数。但需要最大化概率P(y_new|x_new),我们可以使用Llog。但注意到最带花概率P(y_new|x_new)意味着我们要用没有边界的算是函数对我们的结果进行求分。换句话说,有可能我们会看到一个特殊的训练例子,而这个例子是很不好的。
4、有界损失和凸性相对。在一些场合中,直觉来看,损失应该是有界的–我们不会花费无线的代价用在某个错分了的例子熵。注意到有界的损失(L01)经常用来给测试数据的分类器评分。但是有界损失函数,也意味着非凸性–例如,L01(w)不是w的凸函数。这表明有界函数很难进行优化。而凸函数要容易得多。
二、规则项
这节中,我们将介绍集中有用的规则项lamda*R(w)

p=2时,得到平方根R2.在计算函数收敛时,很容易处理标准平方。p->0时,得到R0。R2很常见,应为它很容易能够应用到梯度下降中的优化J(w)。我们能看到加上一个“+lambda*w”项到梯度,根据损失和。。。。。。。
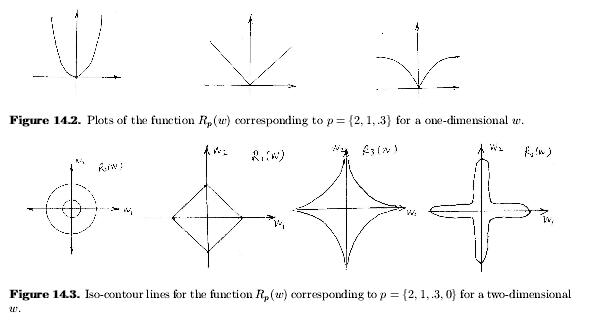
p取不同值时,对应的图像如下所示:















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









