









复现论文:Adversarial Learning for Semi-supervised Semantic Segmentation
GitHub: AdvSemiSeg-pytorch
ubuntu配置环境:
- ubuntu 16.04
- python 3.6
- pytorch 0.4
- GTX1080Ti + CUDA 8.0
win10配置环境:
- win10
- python 3.7.1
- pytorch 1.2.0
- RTX2080Ti + CUDA 10.2
源码环境说明:
作者的源码是基于pytorch-0.2+python2.7+TitanX GPU,由于python3与python2有区别,运行源码的时候有几处要修改的地方。并且代码运行时候需要GPU显存不少于11G。
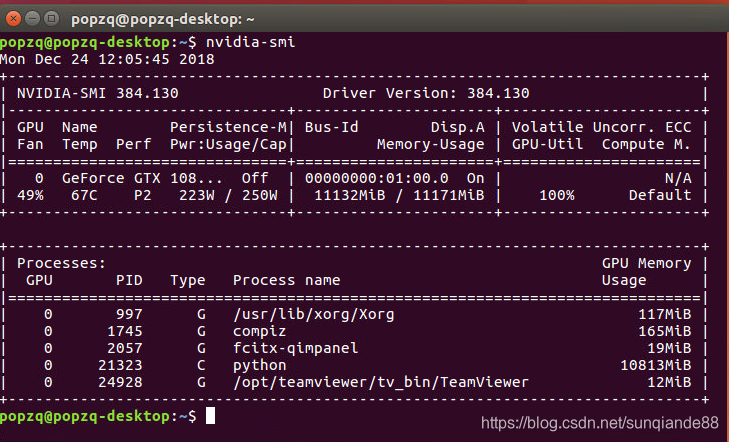

代码调试流程:
1.下载作者的源码(python2),或者我修改好的(python3)
git clone https://github.com/hfslyc/AdvSemiSeg.git
python3版本:https://pan.baidu.com/s/1YHn6c9PfdMqLaUZp7ymMqA (提取码 vads)
2.下载数据集,和预训练模型(VOC2012+SBD),将预训练模型resnet101COCO-41f33a49.pth放入pretrain文件夹中
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
http://vllab1.ucmerced.edu/~whung/adv-semi-seg/SegmentationClassAug.zip
http://vllab1.ucmerced.edu/~whung/adv-semi-seg/resnet101COCO-41f33a49.pth
3.数据集解压,整合成如下目录格式:
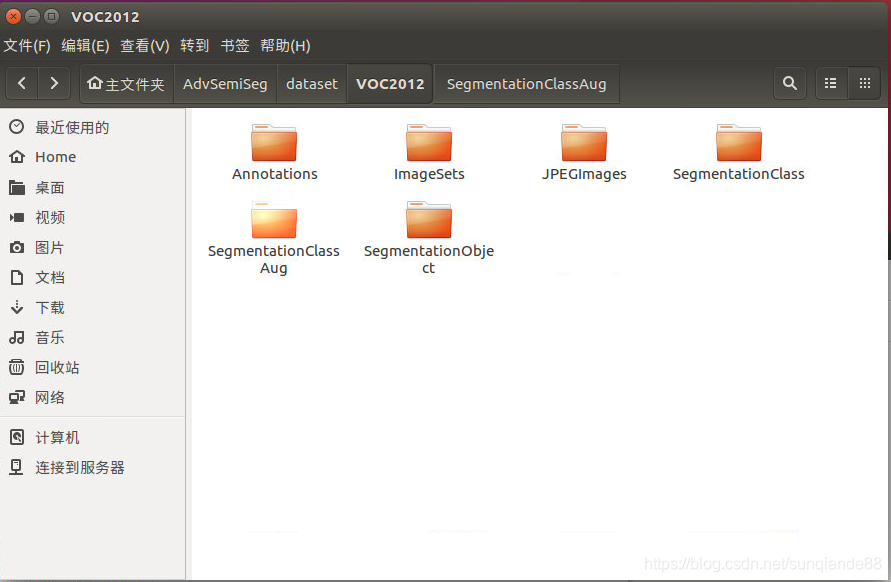

AdvSemiSeg/dataset/VOC2012/JPEGImages
/SegmentationClassAug
4.修改成自己的路径,在train.py中:
DATA_DIRECTORY = '/home/popzq/AdvSemiSeg/dataset/VOC2012' //数据集路径
DATA_LIST_PATH = '/home/popzq/AdvSemiSeg/dataset/voc_list/train_aug.txt' //数据集txt文件路径
SNAPSHOT_DIR = '/home/popzq/AdvSemiSeg/snapshots/' //模型保存的路径
RESTORE_FROM = '/home/popzq/AdvSemiSeg/pretrain/resnet101COCO-41f33a49.pth' //预训练模型的路径
5.训练
如果数据路径都设置对了的话,用终端进入项目路径,输入
python train.py
(我的代码运行的是对抗全监督模型,将所有的数据用于监督学习,总共迭代10万次,每5000次保存一次模型)。如果需要半监督学习方式,需要修改train.py中的以下几个参数,具体设置多少,建议看论文。
PARTIAL_DATA //如设置0.3,则代表数据集中30%的数据将会没有标签,用于半监督学习
LAMBDA_SEMI //半监督超参数
LAMBDA_SEMI_ADV //半监督对抗学习超参数
SEMI_START_ADV //迭代多少次后,开始半监督学习
BATCH_SIZE = 9 //如果出现显卡内存溢出,请缩小合适的BATCH_SIZE
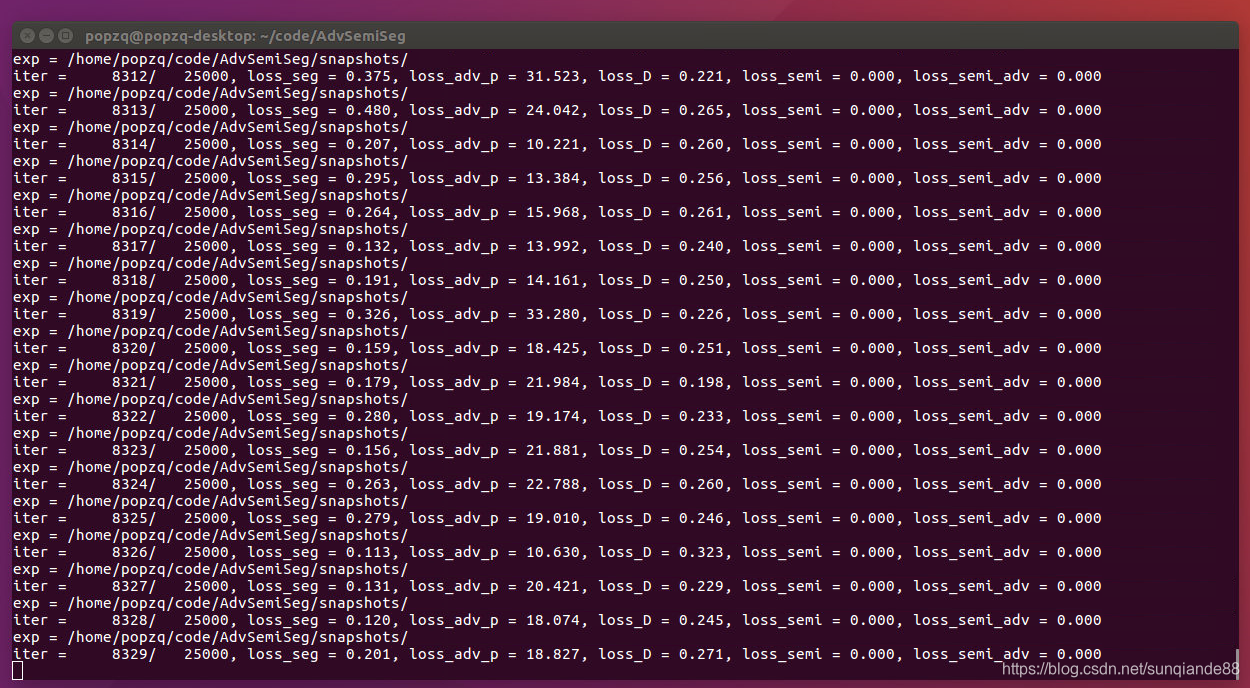

测试实验结果
snapshots会保存实验模型。

在项目根目录的控制台输入如下命令,测试下迭代20000次的模型,稍等片刻,便会看到结果。
python evaluate_voc.py --restore-from snapshots/VOC_20000.pth --save-dir results>>log_file.txt


















 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











