







论文阅读
ResNet
已知神经网络总是趋向于较深的网络发展,在ImageNet数据集中作者提出的ResNet评估了比VGG更深8倍的152层残差网络,复杂度仍然比VGG更低。
在深度的卷积神经网络中我们也知道最主要引起的就是梯度消失/爆炸、退化问题(degradation problem)。作者认为在有限的时间内无法在传统卷积网络中找到一个有效方法解决这个不是由过拟合引起的退化问题。所以作者通过恒等映射(Identity Mapping)进行改进卷积网络,提出了残差学习(Residual Learning)的概念,表达形式为 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,我们能发现经过一个卷积层,聪明的神经网络可以关停某些卷积层使得 F ( x ) ≈ 0 F(x)\approx0 F(x)≈0,这样 H ( x ) ≈ x H(x)\approx x H(x)≈x,并且作者提出加入残差的网络比一般的卷积网络更容易趋近于0。
Residual结构
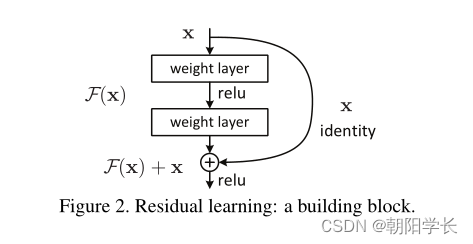
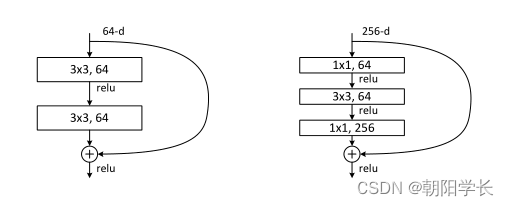
对于18/34 layer的网络使用上方左侧的残差结构,对于50/101/152 layer的网络使用上方右侧的残差结构。作者认为使用 1 ∗ 1 1*1 1∗1的卷积网络进行升降维只在足够深的网络中才能起到足够的作用,在18/34 layer的网络中作用微乎其微。
batch normalization (BN)
BN的目的是为了在一个batch中对应的整个训练集样本的feature map满足均值为0,方差为1的分布规律。参考文章

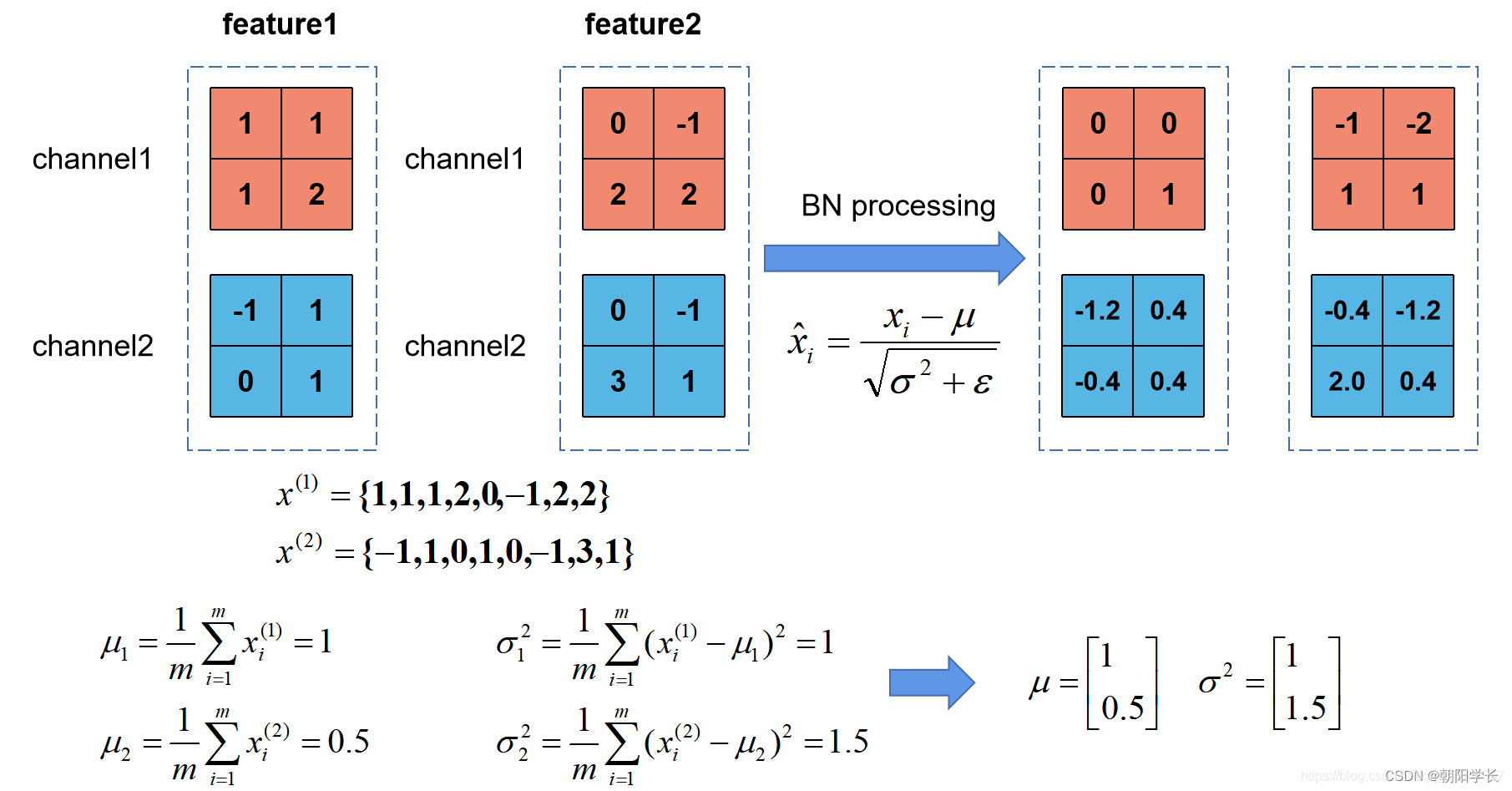
pytorch中使用BN需要注意的问题
- 训练时traning参数需要为True,测试集中应该将traning参数设置为False。在pytorch中可以通过创建模型的model.train()和model.eval()方法控制。
- batch size尽可能的设置大一点,设置的越大所求的均值和反差越接近于整个训练集的均值和方差。
- 建议把BN层放在Conv和激活层之间,并且不需要设置偏置量bias,因为bias是无效的。
迁移学习
迁移学习是使用已经训练好的网络超参数,这样数据集较小的训练集也能快速得到较好的训练效果(需要注意对方预处理的方式)。
常见方式有3种:载入权重后训练所有参数;载入权重后只训练最后几层参数;载入权重后添加全连接层。
基于pytorch搭建ResNet
import torch.nn as nn
import torch
# resnet18/34采用的残差结构
class BasicBlock(nn.Module):
expansion = 1 # 卷积层中第一个和第三个卷积核倍数关系
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
# 前向传播
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x += identity
x = self.relu(x)
return x
# resnet50/101/152采用的残差结构
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=1,
stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3,
stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x += identity
x = self.relu(x)
return x
class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion)
)
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth 预训练模型
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
ResNeXt
ResNeXt提出了“基数”(转换集的大小),认为“基数”是除了深度和宽度维度之外的一个重要因素。在ImageNet-1K数据集上,我们根据经验表明,即使在保持复杂性的限制条件下,增加基数也能够提高分类精度。此外,当我们增加容量时,增加基数比深入或扩大更有效。
ResNeXt在ResNet的基础上修改了主干卷积结构,采用分组卷积的形式替换了原有的卷积结构,在计算量相同的情况下,ResNeXt的错误率更低。
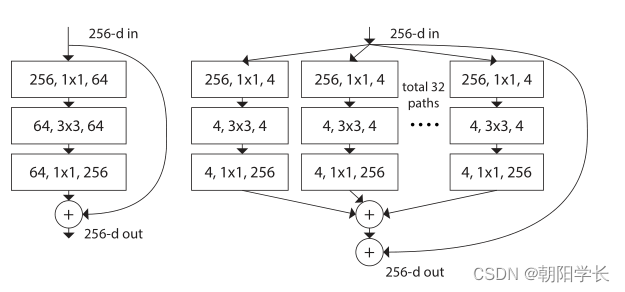
通过分组卷积的方式降低了参数量,并且当输入与输出维度相同时,等价于对输入的特征矩阵每个channel分配了一个channel=1的卷积核进行计算。
等价的三种计算形式。
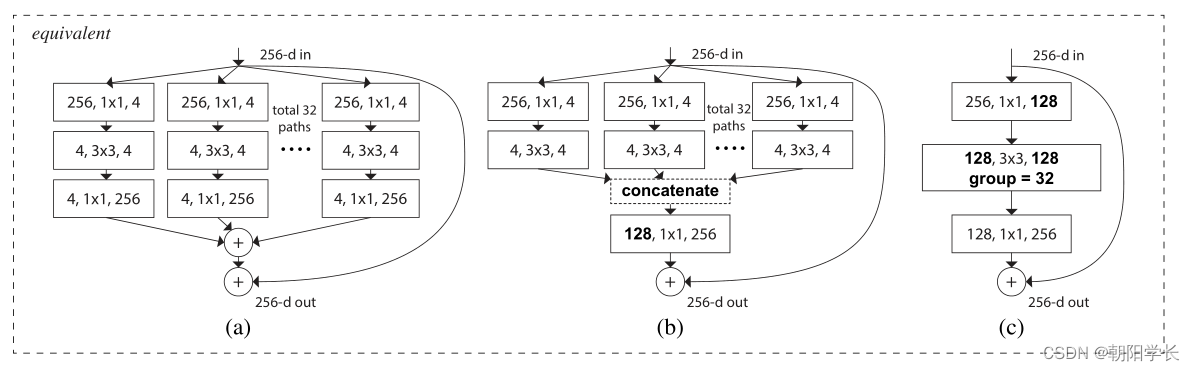
并且作者提出,只有当block层数大于等于3的时候,构建分组卷积的block才有意义,因此这种改进对浅层的ResNet作用不大。
基于pytorch搭建ResNeXt
import torch.nn as nn
import torch
# resnet18/34采用的残差结构
class BasicBlock(nn.Module):
expansion = 1 # 卷积层中第一个和第三个卷积核倍数关系
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
# 前向传播
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x += identity
x = self.relu(x)
return x
# resnet50/101/152采用的残差结构
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
# ResNext add
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width, kernel_size=1,
stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, kernel_size=3,
stride=stride, bias=False, padding=1, groups=groups)
self.bn2 = nn.BatchNorm2d(width)
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x += identity
x = self.relu(x)
return x
class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True,
groups=1, width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion)
)
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride,
groups=self.groups, width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel,
groups=self.groups, width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
猫狗大战
文件准备阶段
# 下载文件
!wget -nc https://static.leiphone.com/cat_dog.rar
#解压zip文件
#!unzip cat_dog.rar
# 解压rar文件
!pip install pyunpack
!pip install patool
from pyunpack import Archive
Archive('/content/cat_dog.rar').extractall('/content/drive/MyDrive/LiuSheng/cat_dog')
加载需要的库以及驱动
import numpy as np
import os
import torch
import torchvision
from torchvision import models,transforms,datasets
from torch.utils.data import Dataset,DataLoader
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from google.colab import drive
drive.mount('/content/drive')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
dataloader
# train_dir = '/cat_dog/train/'
# data_dir = '/content/drive/MyDrive/Colab Notebooks/cat_dog/'
data_dir = '/content/drive/MyDrive/LiuSheng/cat_dog/cat_dog/'
train_dir = data_dir+'train/'
test_dir = data_dir+'test/'
val_dir = data_dir+'val/'
train_imgs = os.listdir(train_dir)
train_labels = []
normalize = transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
transform = transforms.Compose([transforms.Resize([32,32]),transforms.ToTensor(),normalize])
class CatDogDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.imgs = os.listdir(self.root)
self.labels = []
for img in self.imgs:
if img.split('_')[0]=='cat':
self.labels.append(0)
if img.split('_')[0]=='dog':
self.labels.append(1)
def __len__(self):
return len(self.imgs)
def __getitem__(self, index):
label = self.labels[index]
img_dir = self.root + str(self.imgs[index])
img = Image.open(img_dir)
if self.transform is not None:
img = self.transform(img)
return img,torch.from_numpy(np.array(label)) # 返回数据+标签
LeNet实现部分
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 32*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
网络参数,resnet34使用的官方网络
num_workers = 2
batch_size = 32
# lenet
#net = LeNet5()
# resnet34
net = models.resnet34(pretrained=True)
net.fc = nn.Linear(512,2,bias=True)
net = net.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(),lr=0.001)
train_data = CatDogDataset(train_dir,transform=transform)
print(train_data.__len__()) # 20000
train_dataloader = DataLoader(dataset=train_data,shuffle=True,num_workers=num_workers,batch_size=batch_size,pin_memory=True)
val_data = CatDogDataset(val_dir,transform=transform)
val_dataloader = DataLoader(dataset=val_data,shuffle=True,num_workers=num_workers,batch_size=batch_size,pin_memory=True)
训练代码
net.train() # BN参数
for epoch in range(15): # 重复多轮训练
for i,(img,label) in enumerate(train_dataloader):
img = img.to(device)
labels = label.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播+反向传播+优化
outputs = net(img)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
#if i % 1 == 0:
#print('this is ', i)
# 输出统计信息
print('Epoch: %d loss: %.3f' %(epoch+1,loss.item()))
print('Finished Training')
产出结果csv文件
import pandas as pd
test_imgs = os.listdir(test_dir)
id_list = []
label_list = []
net.eval()
for img in test_imgs:
id = img.split('.')[0]
img = Image.open(test_dir+img)
img = transform(img).to(device)
img = img.unsqueeze(0)
label = net(img)
label = 0 if label[0][0]>label[0][1] else 1
id_list.append(id)
label_list.append(label)
dataframe = pd.DataFrame(
{'id': id_list, 'cat_dog': label_list})
#dataframe.to_csv(r"LeNet-result.csv", sep=',')
dataframe.to_csv(r"ResNet-result.csv", sep=',')
提交评分结果,可以看到在相同优化参数以及epoch数量时,ResNet效果比LeNet5好。
思考题
Residual learning 的基本原理?
block的输出为 H ( x ) H(x) H(x),主分支卷积的输出为 F ( x ) F(x) F(x),Shortcut的输出为 x x x,表达形式上 H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x,这种结构通过作者提出的恒等映射有效缓解了网络的退化问题。并且进行求导计算后 H ′ ( x ) = F ′ ( x ) + 1 H'(x)=F'(x)+1 H′(x)=F′(x)+1,这样的形式带上常数1,有效缓解了梯度消失导数为0的问题。
Batch Normailization 的原理
BN是为了每张图片都能服从0均值1标准差的分布。但是当图片输如到神经网络后,每经过一次卷积,数据就不会再服从该分布,这种现象叫做ICS(Internal Covariate Shift,内部协变量偏移),该现象会使输入分布变化,导致模型的训练困难,对深度神经网络影响极大。

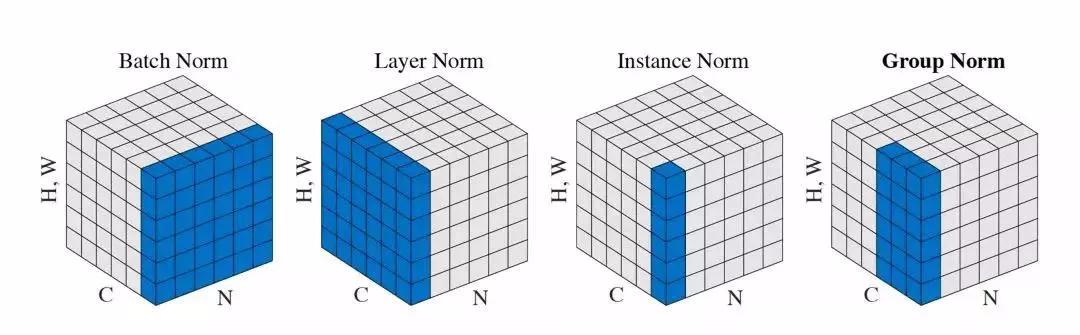
BN、LN、IN 的主要区别
我们将输入的 feature map shape 记为[N, C, H, W],其中N表示batch size,即N个样本;C表示通道数;H、W分别表示特征图的高度、宽度。这几个方法主要的区别就是在:
-
BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好。BN适用于固定深度的前向神经网络,如CNN,不适用于RNN;
-
LN在通道方向上,对C、H、W归一化,主要对RNN效果明显;
-
IN在图像像素上,对H、W做归一化,用在风格化迁移;
分组卷积为什么有效
为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
-
分组卷积在基本不改变或降低模型的复杂度的同时还减少了超参数的数量,从而提高了准确率。
-
分组数量也不能过多,分组数量影响着分组大小,会影响我们的的卷积层从多大的局部中提取特征,当分组大小太小的时候,提取到的特征越分散,这样的特质就越没有代表性,也违背了卷积神经网络中局部关联性的特征。当分组大小太大的时候,提取到的特征越和整体相关,这时候分组卷积也被退化为了普通卷积。















 201
201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









