







由于在看DRL论文中,很多公式都很难理解。因此最近在学习DRL的基本内容。
再此说明,非常推荐B站 “王树森 老师的DRL 强化学习” 本文的图表及内容,都是基于王老师课程的后自行理解整理出的内容。
目录
D. Action Value Network(Critic)
F. Update Action Value network q using TD(Critic)
G.Update policy network Π using policy gradient(Actor)
A. 书接上回
在上篇文章中谈到了如何计算QΠ
共分为两种方法
1、Reinforce 算法

但是其缺点是需要知道最后一轮的奖励,需要游戏玩完才能更新Policy网络
2、用神经网络近似Action-Value network QΠ
因此这样就有两个神经网络
1、Policy函数
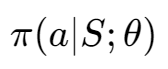
2、Action-Value函数
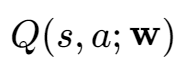
其中Value-Based 是
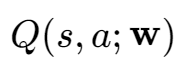
Policy-Based是
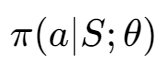
因此本文所介绍的Actor-Critic网络是基于Policy和Value-Based之间的网络
B. State-Value Function

因此State-Value Function共分为两个模块
1、Policy Network(Actor)
2、Ation_Value Network(Policy)
C. Policy NetWork(Actor)
控制Agent执行什么运动
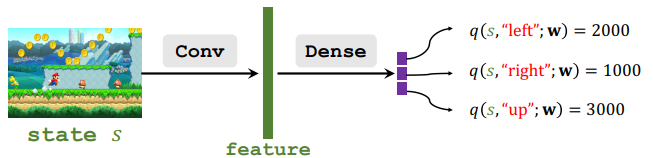
D. Action Value Network(Critic)
评价动作的好坏
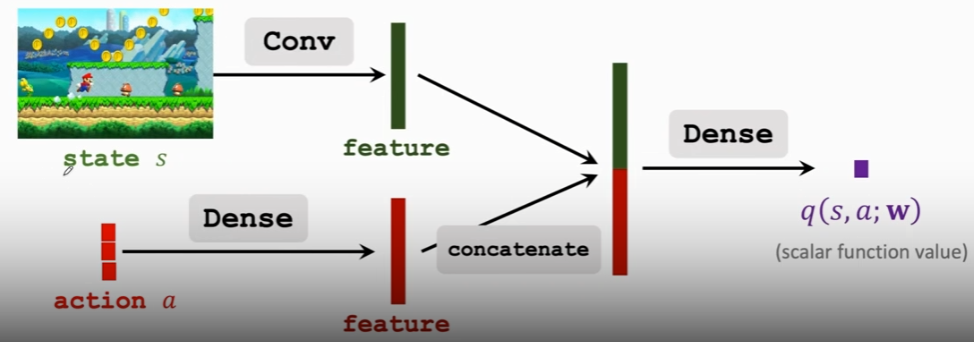
E.Train the Neural Networks

一、更新Neural Network的流程

F. Update Action Value network q using TD(Critic)

G.Update policy network Π using policy gradient(Actor)
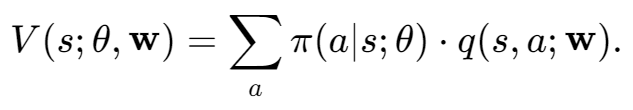
Policy gradient 是对State-Value Func V进行求导

具体的推导公式
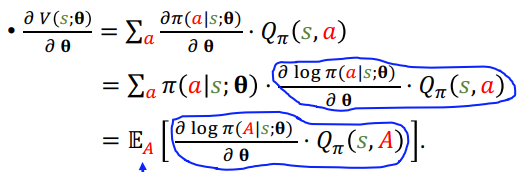
H.总结 Actor-Critic Method
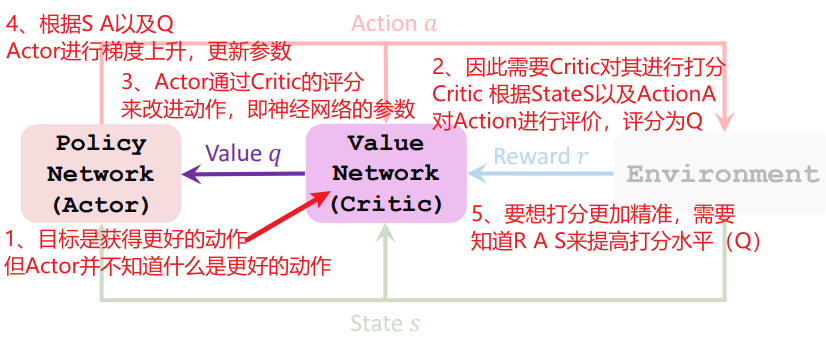

一点对上述总结的补充
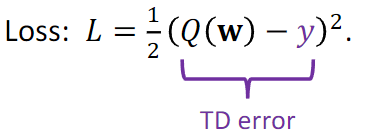

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











