







神经网络算法原理
4.2.1概述人工神经网络的研究与计算机的研究几乎是同步发展的。
1943年心理学家McCulloch和数学家Pitts合作提出了形式神经元的数学模型,20世纪50年代末,Rosenblatt提出了感知器模型,1982年,Hopfiled引入了能量函数的概念提出了神经网络的一种数学模型,1986年,Rumelhart及LeCun等学者提出了多层感知器的反向传播算法等。
神经网络技术在众多研究者的努力下,理论上日趋完善,算法种类不断增加。目前,有关神经网络的理论研究成果很多,出版了不少有关基础理论的著作,并且现在仍是全球非线性科学研究的热点之一。
神经网络是一种通过模拟人的大脑神经结构去实现人脑智能活动功能的信息处理系统,它具有人脑的基本功能,但又不是人脑的真实写照。它是人脑的一种抽象、简化和模拟模型,故称之为人工神经网络(边肇祺,2000)。
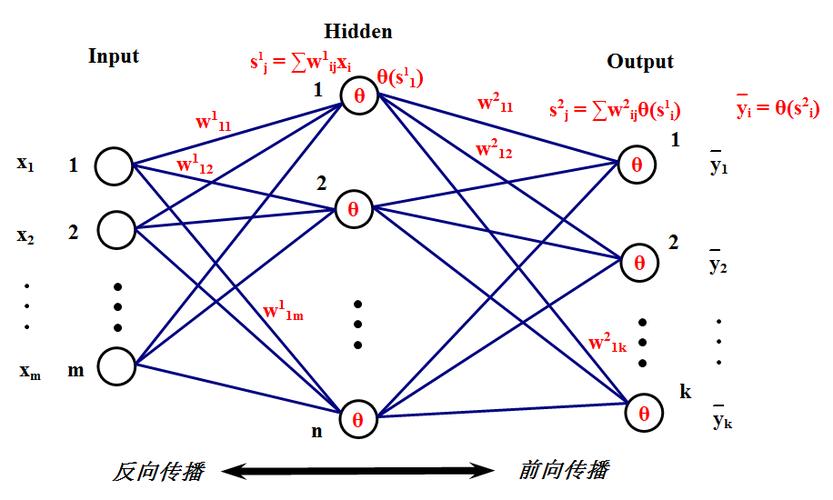
人工神经元是神经网络的节点,是神经网络的最重要组成部分之一。目前,有关神经元的模型种类繁多,最常用最简单的模型是由阈值函数、Sigmoid函数构成的模型(图4-3)。
图4-3人工神经元与两种常见的输出函数神经网络学习及识别方法最初是借鉴人脑神经元的学习识别过程提出的。
输入参数好比神经元接收信号,通过一定的权值(相当于刺激神经兴奋的强度)与神经元相连,这一过程有些类似于多元线性回归,但模拟的非线性特征是通过下一步骤体现的,即通过设定一阈值(神经元兴奋极限)来确定神经元的兴奋模式,经输出运算得到输出结果。
经过大量样本进入网络系统学习训练之后,连接输入信号与神经元之间的权值达到稳定并可最大限度地符合已经经过训练的学习样本。
在被确认网络结构的合理性和学习效果的高精度之后,将待预测样本输入参数代入网络,达到参数预测的目的。
4.2.2反向传播算法(BP法)发展到目前为止,神经网络模型不下十几种,如前馈神经网络、感知器、Hopfiled网络、径向基函数网络、反向传播算法(BP法)等,但在储层参数反演方面,目前比较成熟比较流行的网络类型是误差反向传播神经网络(BP-ANN)。
BP网络是在前馈神经网络的基础上发展起来的,始终有一个输入层(它包含的节点对应于每个输入变量)和一个输出层(它包含的节点对应于每个输出值),以及至少有一个具有任意节点数的隐含层(又称中间层)。
在BP-ANN中,相邻层的节点通过一个任意初始权值全部相连,但同一层内各节点间互不相连。
对于BP-ANN,隐含层和输出层节点的基函数必须是连续的、单调递增的,当输入趋于正或负无穷大时,它应该接近于某一固定值,也就是说,基函数为“S”型(Kosko,1992)。
BP-ANN的训练是一个监督学习过程,涉及两个数据集,即训练数据集和监督数据集。
给网络的输入层提供一组输入信息,使其通过网络而在输出层上产生逼近期望输出的过程,称之为网络的学习,或称对网络进行训练,实现这一步骤的方法则称为学习算法。
BP网络的学习过程包括两个阶段:第一个阶段是正向过程,将输入变量通过输入层经隐层逐层计算各单元的输出值;第二阶段是反向传播过程,由输出误差逐层向前算出隐层各单元的误差,并用此误差修正前层权值。
误差信息通过网络反向传播,遵循误差逐步降低的原则来调整权值,直到达到满意的输出为止。
网络经过学习以后,一组合适的、稳定的权值连接权被固定下来,将待预测样本作为输入层参数,网络经过向前传播便可以得到输出结果,这就是网络的预测。
反向传播算法主要步骤如下:首先选定权系数初始值,然后重复下述过程直至收敛(对各样本依次计算)。
(1)从前向后各层计算各单元Oj储层特征研究与预测(2)对输出层计算δj储层特征研究与预测(3)从后向前计算各隐层δj储层特征研究与预测(4)计算并保存各权值修正量储层特征研究与预测(5)修正权值储层特征研究与预测以上算法是对每个样本作权值修正,也可以对各个样本计算δj后求和,按总误差修正权值。
谷歌人工智能写作项目:小发猫

神经网络BP模型
一、BP模型概述误差逆传播(ErrorBack-Propagation)神经网络模型简称为BP(Back-Propagation)网络模型rfid。
PallWerbas博士于1974年在他的博士论文中提出了误差逆传播学习算法。完整提出并被广泛接受误差逆传播学习算法的是以Rumelhart和McCelland为首的科学家小组。
他们在1986年出版“ParallelDistributedProcessing,ExplorationsintheMicrostructureofCognition”(《并行分布信息处理》)一书中,对误差逆传播学习算法进行了详尽的分析与介绍,并对这一算法的潜在能力进行了深入探讨。
BP网络是一种具有3层或3层以上的阶层型神经网络。上、下层之间各神经元实现全连接,即下层的每一个神经元与上层的每一个神经元都实现权连接,而每一层各神经元之间无连接。
网络按有教师示教的方式进行学习,当一对学习模式提供给网络后,神经元的激活值从输入层经各隐含层向输出层传播,在输出层的各神经元获得网络的输入响应。
在这之后,按减小期望输出与实际输出的误差的方向,从输入层经各隐含层逐层修正各连接权,最后回到输入层,故得名“误差逆传播学习算法”。
随着这种误差逆传播修正的不断进行,网络对输入模式响应的正确率也不断提高。
BP网络主要应用于以下几个方面:1)函数逼近:用输入模式与相应的期望输出模式学习一个网络逼近一个函数;2)模式识别:用一个特定的期望输出模式将它与输入模式联系起来;3)分类:把输入模式以所定义的合适方式进行分类;4)数据压缩:减少输出矢量的维数以便于传输或存储。
在人工神经网络的实际应用中,80%~90%的人工神经网络模型采用BP网络或它的变化形式,它也是前向网络的核心部分,体现了人工神经网络最精华的部分。
二、BP模型原理下面以三层BP网络为例,说明学习和应用的原理。
1.数据定义P对学习模式(xp,dp),p=1,2,…,P;输入模式矩阵X[N][P]=(x1,x2,…,xP);目标模式矩阵d[M][P]=(d1,d2,…,dP)。
三层BP网络结构输入层神经元节点数S0=N,i=1,2,…,S0;隐含层神经元节点数S1,j=1,2,…,S1;神经元激活函数f1[S1];权值矩阵W1[S1][S0];偏差向量b1[S1]。
输出层神经元节点数S2=M,k=1,2,…,S2;神经元激活函数f2[S2];权值矩阵W2[S2][S1];偏差向量b2[S2]。
学习参数目标误差ϵ;初始权更新值Δ0;最大权更新值Δmax;权更新值增大倍数η+;权更新值减小倍数η-。
2.误差函数定义对第p个输入模式的误差的计算公式为中国矿产资源评价新技术与评价新模型y2kp为BP网的计算输出。
3.BP网络学习公式推导BP网络学习公式推导的指导思想是,对网络的权值W、偏差b修正,使误差函数沿负梯度方向下降,直到网络输出误差精度达到目标精度要求,学习结束。
各层输出计算公式输入层y0i=xi,i=1,2,…,S0;隐含层中国矿产资源评价新技术与评价新模型y1j=f1(z1j),j=1,2,…,S1;输出层中国矿产资源评价新技术与评价新模型y2k=f2(z2k),k=1,2,…,S2。
输出节点的误差公式中国矿产资源评价新技术与评价新模型对输出层节点的梯度公式推导中国矿产资源评价新技术与评价新模型E是多个y2m的函数,但只有一个y2k与wkj有关,各y2m间相互独立。
其中中国矿产资源评价新技术与评价新模型则中国矿产资源评价新技术与评价新模型设输出层节点误差为δ2k=(dk-y2k)·f2′(z2k),则中国矿产资源评价新技术与评价新模型同理可得中国矿产资源评价新技术与评价新模型对隐含层节点的梯度公式推导中国矿产资源评价新技术与评价新模型E是多个y2k的函数,针对某一个w1ji,对应一个y1j,它与所有的y2k有关。
因此,上式只存在对k的求和,其中中国矿产资源评价新技术与评价新模型则中国矿产资源评价新技术与评价新模型设隐含层节点误差为中国矿产资源评价新技术与评价新模型则中国矿产资源评价新技术与评价新模型同理可得中国矿产资源评价新技术与评价新模型4.采用弹性BP算法(RPROP)计算权值W、偏差b的修正值ΔW,Δb1993年德国MartinRiedmiller和HeinrichBraun在他们的论文“ADirectAdaptiveMethodforFasterBackpropagationLearning:TheRPROPAlgorithm”中,提出ResilientBackpropagation算法——弹性BP算法(RPROP)。
这种方法试图消除梯度的大小对权步的有害影响,因此,只有梯度的符号被认为表示权更新的方向。
权改变的大小仅仅由权专门的“更新值”确定中国矿产资源评价新技术与评价新模型其中表示在模式集的所有模式(批学习)上求和的梯度信息,(t)表示t时刻或第t次学习。
权更新遵循规则:如果导数是正(增加误差),这个权由它的更新值减少。如果导数是负,更新值增加。中国矿产资源评价新技术与评价新模型RPROP算法是根据局部梯度信息实现权步的直接修改。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









