









人工智能学习笔记(2):认识和安装Stable Diffusion
文章目录

Stable Diffusion是一种基于深度学习的生成模型,主要用于文本到图像的转换。Stable Diffusion 的厉害之处在于它可以在运行于大多数配备有合适 GPU 的个人计算机上,而且,它开源了项目代码和模型权重。这样一来,开发者就可以在它的基础上进行二次开发、做插件、做工具,这就有了如今结合 Stable Diffusion 流行起来的 Stable Diffusion WebUI、LoRA、ControlNet 等开源项目。这就相当于给 Stable Diffusion 的发展增加了大量的盟友,极大地丰富了它的功能和特性,也被广泛应用于艺术创作、媒体和广告行业。
Stable Diffusion的起源和发展历程
Stable Diffusion技术的基础可以追溯到1990年代初,由Perona和Malik提出的非线性扩散方程开始。这种方法通过改变传统线性扩散模型的处理方式,使得具有较小梯度的像素点扩散得更慢,从而更好地保留了图像的细节信息。这一理论的提出,标志着计算机视觉领域中对图像细节保护的重视,为后续Stable Diffusion技术的发展打下了坚实的基础。
虽然早期的研究主要集中在理论层面,但很快这些理论就被实际应用于图像处理中,尤其是在图像去噪、边缘增强等方面表现出色。这种从理论到实践的转变,不仅验证了非线性扩散模型的有效性,也推动了相关技术的进一步发展。
1992年,Chaudhuri和Tandon提出了自适应扩散方程,这是对原有非线性扩散模型的重要改进。通过根据图像特征自动调整扩散速度,这一方法极大地提高了模型处理不同类型图像时的灵活性和效率。
1995年,Weickert在研究中引入了结构张量的概念,用以更精确地计算图像中各像素的梯度。这一创新不仅优化了扩散结果,还为后续的双结构张量方法奠定了基础,进一步改善了图像处理的质量
2007年,Alvarez等人将时空稳定扩散技术引入到动态图像处理中,这标志着Stable Diffusion技术向视频处理等更广泛应用领域的扩展
Stable Diffusion的应用场景
Stable Diffusion 作为一款强大的 AI 绘画工具,可以用在哪些场景呢?
- 电商行业的应用
在电商行业,Stable Diffusion被用来处理大量的模特搭配服装的产品图片。这不仅帮助电商公司节省了准备图片的时间和成本,还能快速响应市场变化,实时更新产品展示。例如,通过Stable Diffusion技术,可以将平铺或白底的服装“穿”在AI模特身上,从而为消费者提供更直观的穿着效果,增强购物体验。 - 艺术与创作
Stable Diffusion为艺术家和创作者提供了强大的工具。用户只需用语言描述一个场景或角色,这个模型就能生成相应的高质量图像。这不仅加速了创作过程,还允许艺术家探索原本难以实现的视觉样式。同时,该技术还支持风格转换,能将图像转化为不同的艺术风格,如印象派、涂鸦等,为艺术作品赋予新的视觉感受。 - 图像修复与增强
在图像编辑领域,Stable Diffusion不仅可以修复低质量或受损的图像,使其变得更清晰和逼真,还能执行标准的图像编辑任务,如剪裁、调色和添加元素等。这一功能对于摄影师和图像编辑人员来说极具价值,帮助他们在工作中达到更高的专业水平。 - 虚拟世界与想象力增强
Stable Diffusion使用户能够输入一些文字描述,让AI生成超越现实的场景,这在虚拟世界创作中发挥着巨大作用。它不仅推动了游戏和虚拟现实中场景设计的多样化,也为电影和动画制作提供了无限的灵感来源。 - 教育与培训:
在教育领域,Stable Diffusion可以用于创建教学材料和可视化复杂的概念。教师和讲师可以利用这项技术生成具体的图像,以帮助学生更好地理解课程内容。 - 广告与市场营销:
Stable Diffusion在广告行业中的应用也非常广泛。它可以帮助创意团队快速生成符合市场需求的广告素材,无论是创造引人注目的视觉效果还是合成创新的广告形象,都能大幅提升广告的吸引力和效果。 - 辅助设计与创意启发:
设计师可以利用Stable Diffusion进行初步草图的生成和修改,这不仅加快了设计流程,还能在设计初期就发现潜在的创意问题。此外,AI的随机性输出有时候也能给设计师带来意想不到的灵感,从而推动创意的发展。 - 游戏设计
Stable Diffusion 可以辅助设计师设计游戏中的素材,如角色、场景、道具等。设计师只需要提供概念素材,Stable Diffusion 就可以生成多种不同风格的画面,然后设计师进行选择和修改即可,这样可以节省游戏素材设计的时间成本。
这里也只是列出了 Stable Diffusion 的一部分应用场景,随着相关技术的进步,Stable Diffusion 的应用场景还会越来越广泛,成为大家提高创造力和生产力的好帮手。当然,艺术创意和审美判断仍然需要人类的专业知识和审美眼光,只有人与机器更好地结合、互补,设计领域才可以发展得更好。
基本原理
Stable Diffusion由三个主要部分组成:文本编码器、UNet噪声预测网络和VAE(Variational Autoencoder)。整个处理流程开始于接收一个文本输入,然后使用CLIP模型对文本进行编码,获得文本嵌入。接着,系统从潜在空间生成噪声向量,这个噪声向量随后被用于生成最终的图像
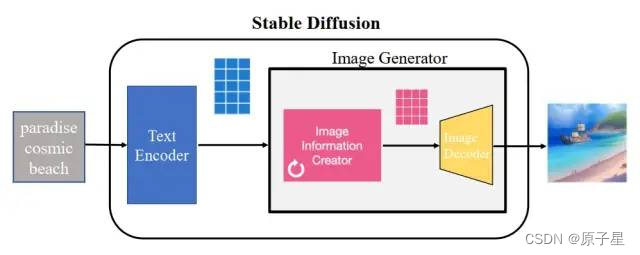
文本到图像的转换过程
用户首先提供一段描述性文本,这段文本会被送入到一个预训练的CLIP模型中。CLIP模型包括两个部分,一个用于处理文本的TextEncoder和一个用于处理图像的ImageEncoder。这两部分共同工作,将文本信息转换为可以与图像数据对应起来的向量形式。这种转换确保了生成的图像能够尽可能地反映出用户输入的文本描述的内容。
潜在空间中的噪声处理
在得到文本嵌入后,系统会生成一个初始的潜在空间向量,这一向量本质上是随机噪声。然后,这个噪声向量和文本嵌入一起被送入UNet模型。UNet模型在这里扮演的是降噪的角色,即通过多次迭代去预测并消除噪声向量中的噪声成分。每一步降噪都会使图像逐渐变得清晰,直至最终形成符合文本描述的图像。
VAE的作用与优化
在UNet模型处理之后,得到的降噪结果被送入VAE的解码器部分。VAE在这里的作用是将潜在空间的向量转换回像素空间,从而生成最终的用户可见的图像。VAE的使用不仅帮助模型在较低维度上高效地操作,还负责最终图像的生成质量。这一步是整个Stable Diffusion过程中的关键,因为它直接决定了输出图像的质量和细节丰富度。
部署和安装
硬件要求
操作系统:Windows10及以上
CPU:不做强制性要求
内存:至少8GB,推荐16GB及以上
显卡:必须是英伟达NVIDIA的独立显卡,至少4GB显存,推荐20系以后,8GB显存及以上(AMD显卡、核显只能用CPU跑)
硬盘:固态硬盘(由于模型文件普遍较大,推荐预留500GB-1TB硬盘空间)
安装过程
这里介绍下Windows环境下手动安装的过程:
- 下载安装Python的最新版本,安装时要注意勾选“Add Python to PATH”选项。
- 下载安装Git标准版,根据提示操作即可。
- 进入Windows控制台(运行cmd)输入
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git下载WebUI代码。 - 代码下载完成后,会有一个
stable-diffusion-webui文件夹,下载这个档案文件,并将文件放到stable-diffusion-webui\models\Stable-diffusion文件夹下。 - 打开
stable-diffusion-wbui文件夹,运行webui-user.bat批处理文件。 - 打开浏览器,在地址栏中输入
http://127.0.0.1:7860即可开始使用Stable Diffusion。
















 559
559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











