










【图数据】股权网络穿透一千层需要多久?
Here’s the table of contents:
图数据关系路径穿透测试
本次测试运行在总体规模在11亿的数据集上,股权网络数据量超千万,测试方式为从某公司出发股权网络向上穿透100层和1000层,返回一条路径结果【LIMIT 1】。一百层穿透相当于101张MySQL的数据表做100的JOIN,一千层穿透相当于1001张MySQL的数据表做1000的JOIN,MySQL是无法实现这个查询的。
图数据库选型
图数据库为ONgDB【技术交流QQ群:1061594137】,部署方式为三节点因果集群部署,两个CORE节点和一个REPLICA节点。服务配置为64G内存8核CPU。
图数据模型说明
- 数据规模
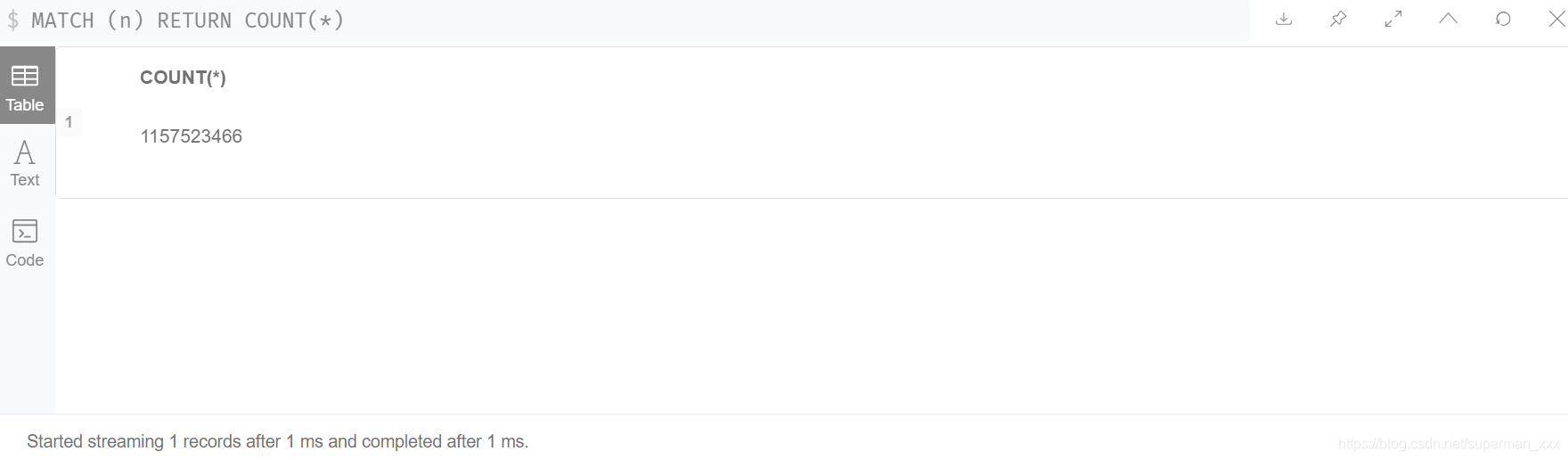
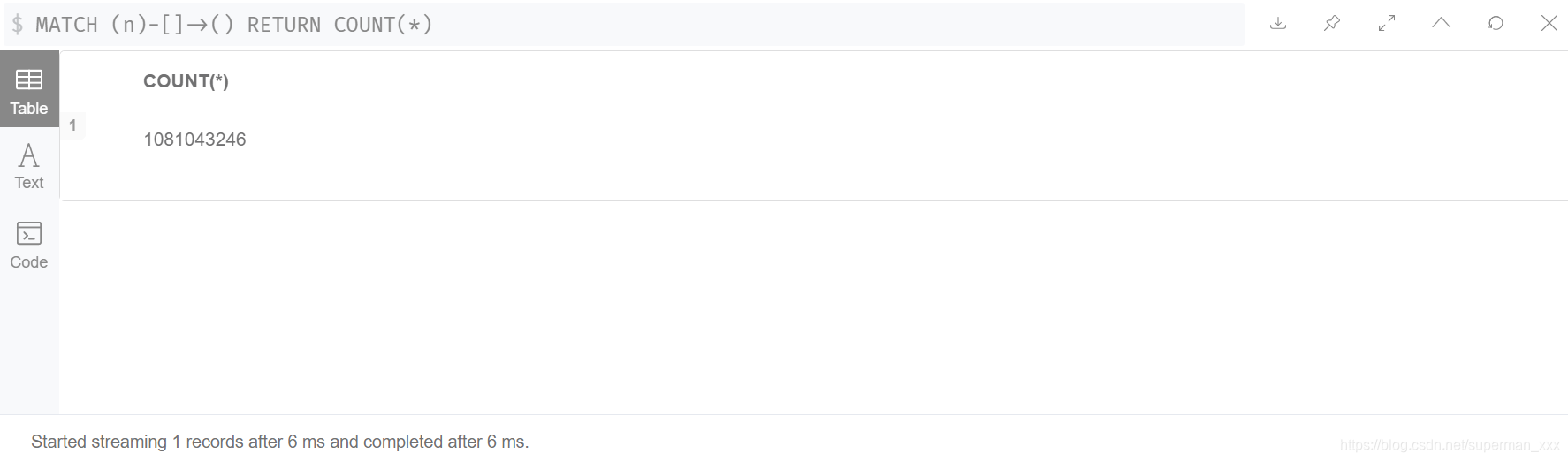
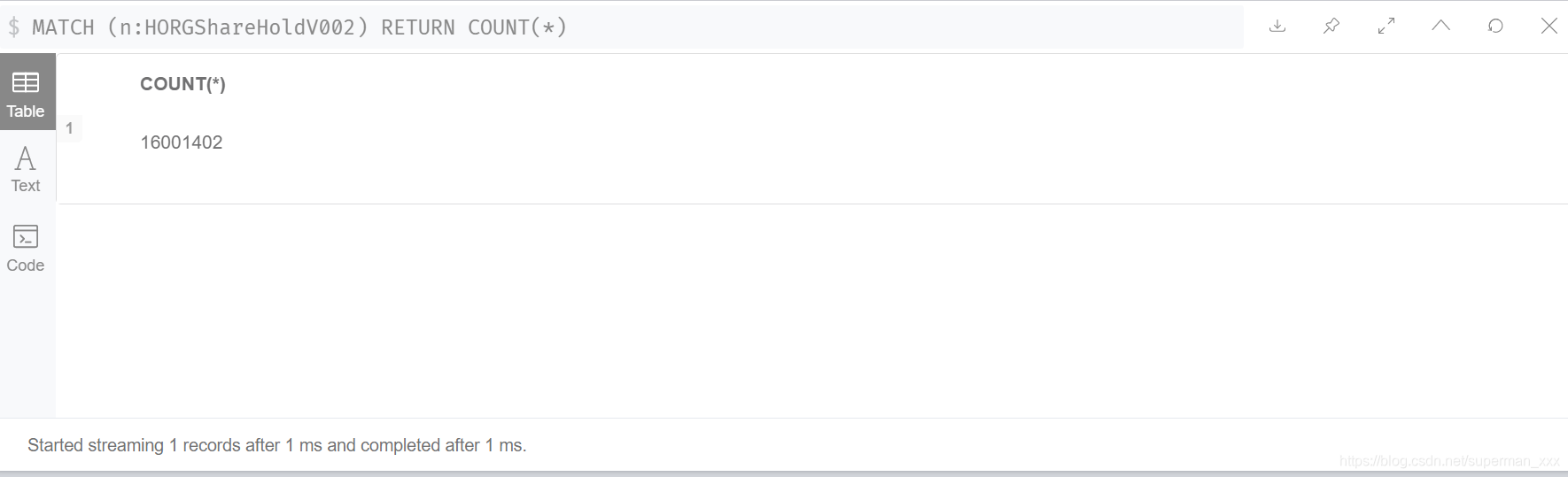
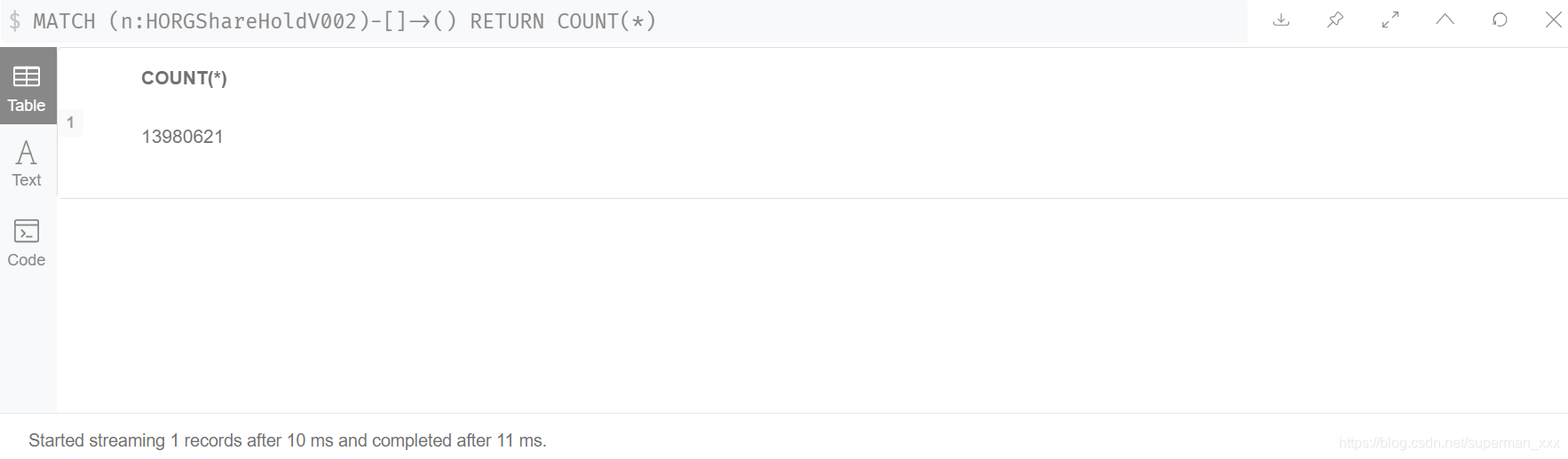
整个图库包含节点1157523466个【十一亿个节点】,1081043246条关系【十亿条关系】。股权网络建模为同构图,节点为16001402个【一千六百万】,关系为13980621万【一千四百万】。
- 数据建模方式
股权网络实体标签为
HORGShareHoldV002,关系为持股,持股的详情数据使用shareholding_detail字段存储时间序列字段【时间序列的数据建模可以参考集成ES实现】。
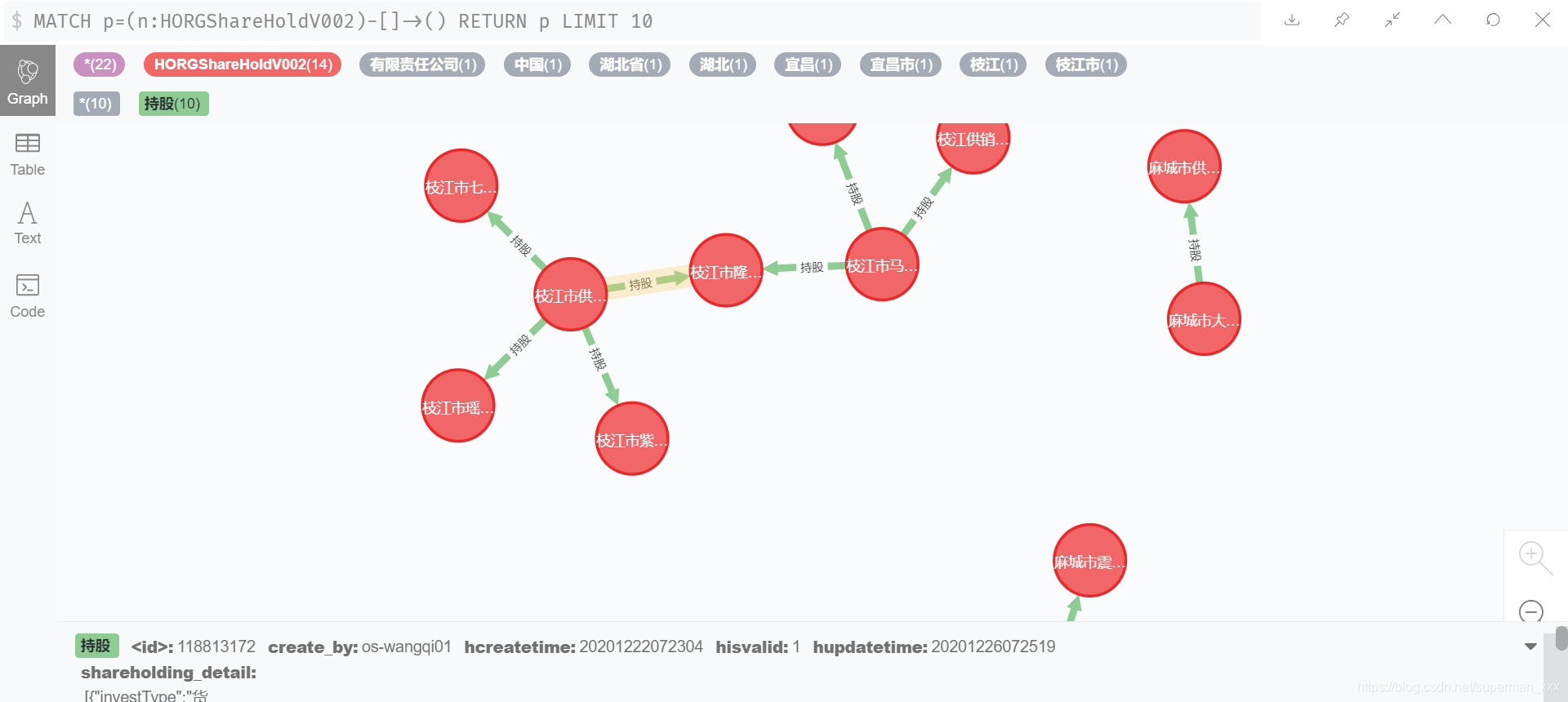
股权网络穿透一百层
穿透一百层查询语句
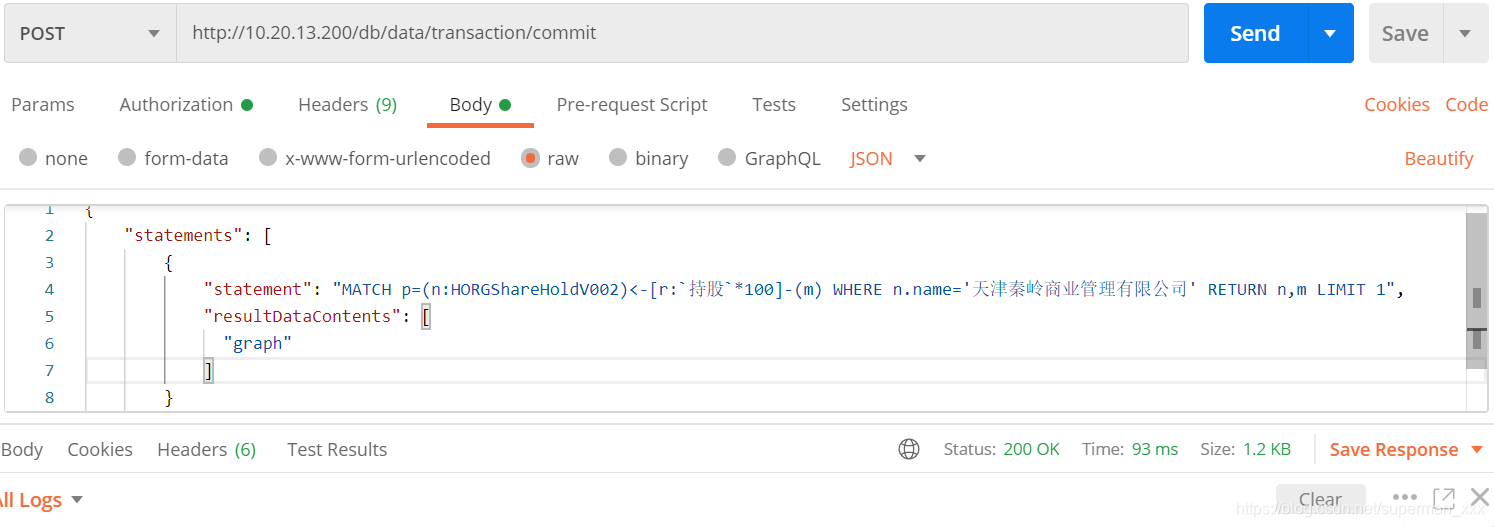
使用postman执行cypher查询
MATCH p=(n:HORGShareHoldV002)<-[r:`持股`*100]-(m) WHERE n.name='天津秦岭商业管理有限公司' RETURN p LIMIT 1
{
"statements": [
{
"statement": "MATCH p=(n:HORGShareHoldV002)<-[r:`持股`*100]-(m) WHERE n.name='天津秦岭商业管理有限公司' RETURN p LIMIT 1",
"resultDataContents": [
"graph"
]
}
]
}
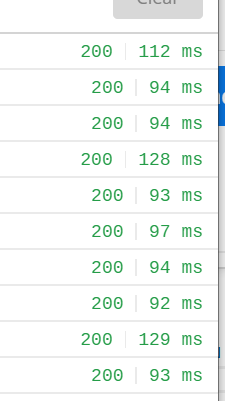
穿透一百层10次测试执行结果
股权网络穿透一千层
穿透一千层查询语句
使用postman执行cypher查询
MATCH p=(n:HORGShareHoldV002)<-[r:`持股`*1000]-(m) WHERE n.name='天津秦岭商业管理有限公司' RETURN p LIMIT 1
{
"statements": [
{
"statement": "MATCH p=(n:HORGShareHoldV002)<-[r:`持股`*1000]-(m) WHERE n.name='天津秦岭商业管理有限公司' RETURN n,m LIMIT 1",
"resultDataContents": [
"graph"
]
}
]
}
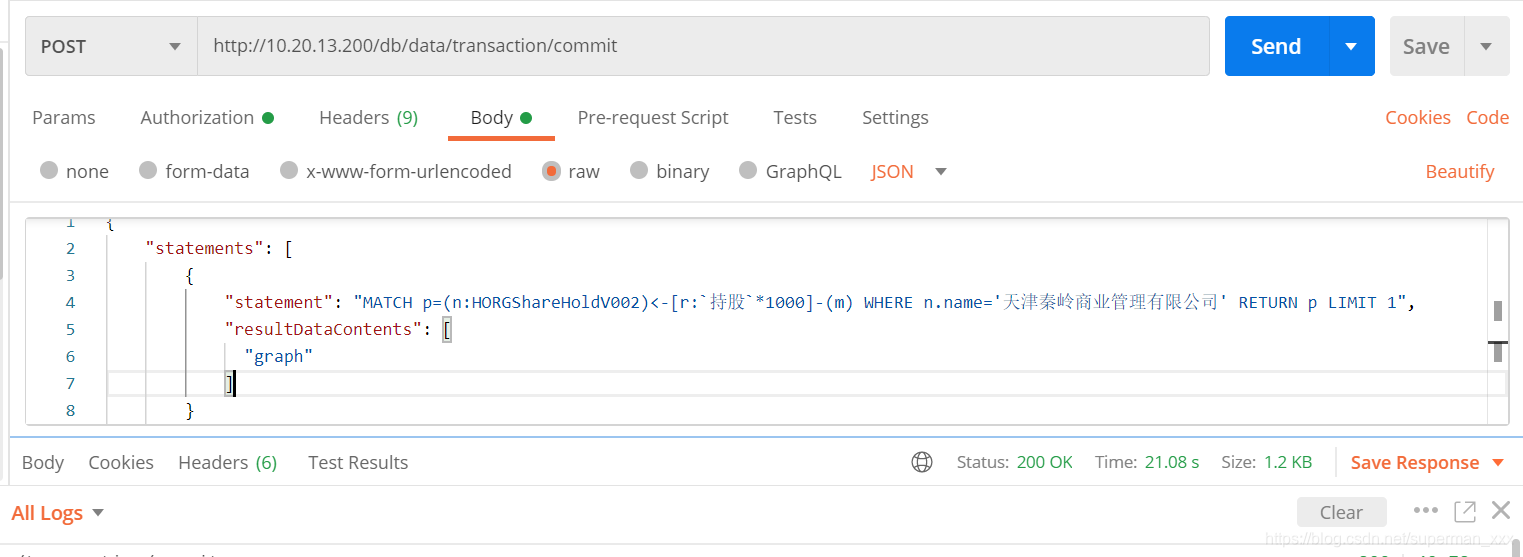
穿透一千层10次测试执行结果
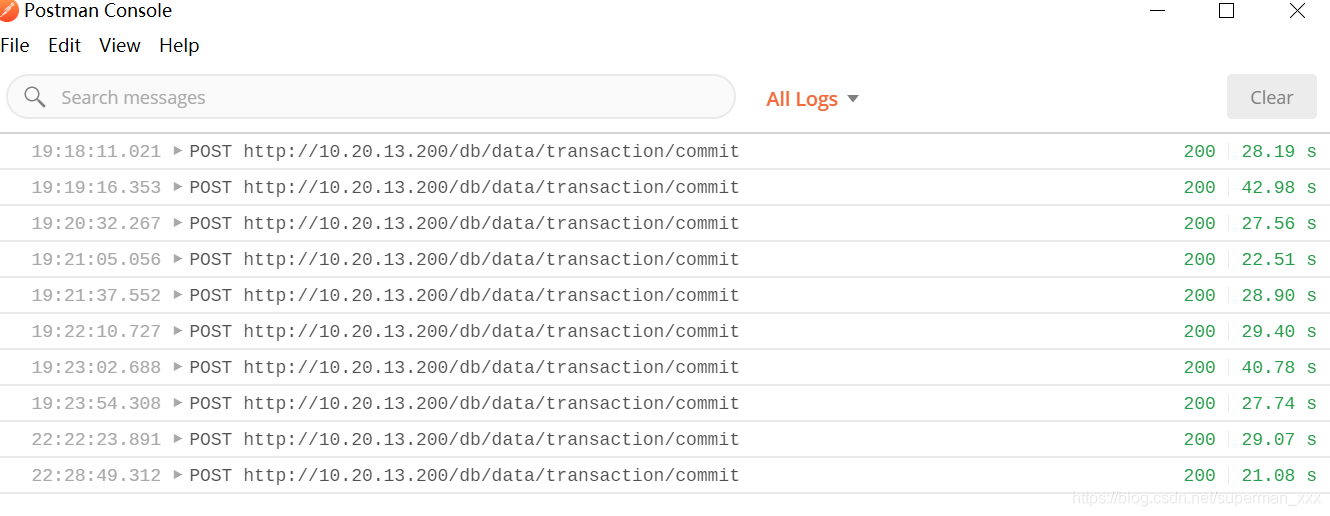
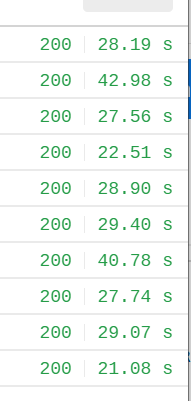
测试结果统计
图数据库路径穿透理论上算法时间复杂度为O(1),ONgDB【Neo4j】的路径穿透性能会比Nebula Graph等分布式图数据库性能更好【没有在分布式图数据库上做测试但是从数据库架构上可以做基本判断】,是因为分布式系统最大的性能消耗在于网络通信上,如果是跑人工智能相关的算法模型,集中式的图数据架构性能会更好【对于巨量的图数据模型可以考虑集成ES存储时间序列指标,解决数据体量的问题】。
- 穿透一百层
平均耗时:102毫秒
最小耗时:92毫秒
最大耗时:129毫秒
- 穿透一千层
平均耗时:29.3秒
最小耗时:21.08秒
最大耗时:42.98秒


















 2745
2745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











