






本文介绍一些CUDA C/C++编程过程中的一些小工具~,无痛给自己cuda代码配置上
目录
1. 查看cuda代码运行时间,定位优化问题。
1.1 NVPROF
2. 错误检测
3.事件,用于标记,可以测算核函数运行时间
4.unified memory 简化流程,不用显示传输数据
1. 查看cuda代码运行时间,定位优化问题。
1.1 NVPROF
nvprof a.exe
nvprof --print-gpu-trace a.exe
nvprof --print-api-trace a.exe
To do :
nvprof 结合nvvp或者nsight进行可视化分析

2. 错误检测
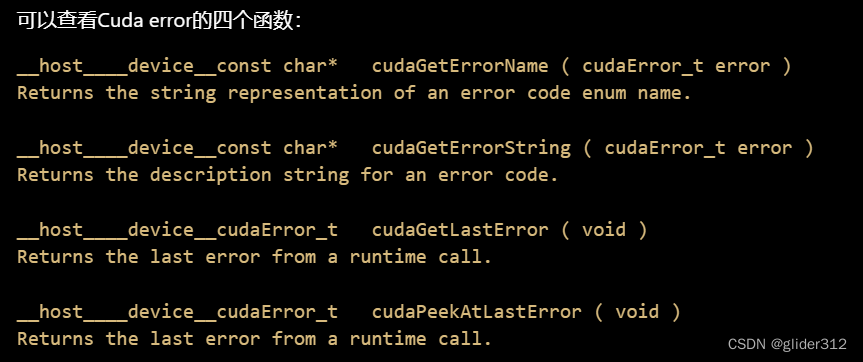
选择第二种,封装到error.cuh中:
#pragma once
#include <stdio.h>
#define CHECK(call) \
do \
{ \
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{ \
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
然后需要做三件事:
- 在.cu文件中 #include “error.cuh”
- 在.cu文件中,将所有涉及CUDA的操作用CHECK()函数封装,实例如下:
- 编译时加上error.cuh
注释中用!!!check标明了调用check的地方
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
//!!!check
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
//!!!check
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
//!!!check
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
CHECK(cudaGetLastError());
//!!!check
CHECK(cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
//!!!check
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
return 0;
}
3. 事件
作为一个标记,比较常用的用法是可以用来测算核函数运行的时间。步骤如下:
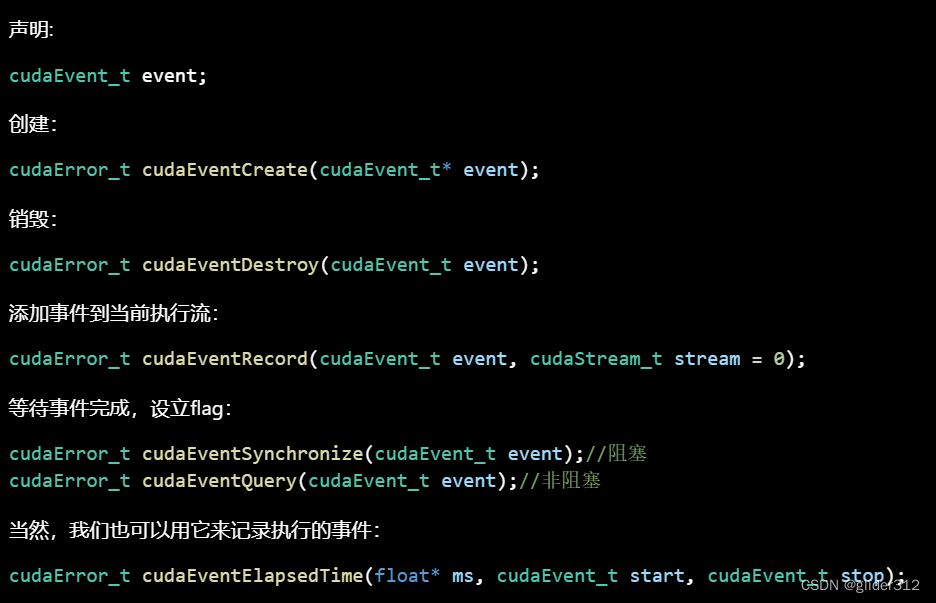
实例如下,注释中用!!!开头标明了流程:
note:显然事件的函数都是操作CUDA的,所以都可以用CHECK函数包装(cudaEventQuery除外)
int main(int argc, char const *argv[])
{
int m=100;
int n=100;
int k=100;
int *h_a, *h_b, *h_c, *h_cc;
CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
// !!! step 1 声明
cudaEvent_t start, stop;
// !!! step2 创建一个start 一个stop事件
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
int *d_a, *d_b, *d_c;
CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
//!!! 添加事件到执行流,可以理解start事件为标注一下此处
CHECK(cudaEventRecord(start));
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
//!!! 用stop标记此处
CHECK(cudaEventRecord(stop));
//!!! 同步
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
// !!!计算start事件和stop事件之间的时间间隔,即cuda核函数的运行时间。
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
//!!! 销毁事件
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
CHECK(cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cc, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
CHECK(cudaFree(d_a));
CHECK(cudaFree(d_b));
CHECK(cudaFree(d_c));
CHECK(cudaFreeHost(h_a));
CHECK(cudaFreeHost(h_b));
CHECK(cudaFreeHost(h_c));
return 0;
}
4.unified memory
数据要在cpu和gpu之间反复传输累不累呀~
用unified memory可以做到,一次定义,cpu和gpu都可调用!
具体步骤:
- 将想要同时cpu和gpu使用的变量用__managed__进行定义
- 删除对cuda中变量内存分配空间函数cudaMallocHost
- 删除原本cpu中内存分配空间函数cudaMalloc
- 删除cpu向gpu传输数据函数cudaMemcpy。请注意!在jetson系列中CPU和GPU集成在一个芯片,所以这种情况下,确实删除了拷贝过程。但是,在其他更多的硬件产品,CPU和GPU不在同一芯片上时,删除了传输函数不代表不传输,只不过unified memory会内部隐式的调用数据传输,我们只是把显式的数据传输给删除掉了。
- 删除gpu向cpu传输数据函数 cudaMemcpy。请和上面一样注意
- 删除cudaFree和cudaFreeHost函数。
实例如下:
int main(int argc, char const *argv[])
{
int m=30;
int n=96;
int k=160;
// int *h_a, *h_b, *h_c, *h_cc;
//CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n));
// CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k));
//CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k));
// CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k));
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
h_a[i * n + j] = rand() % 1024;
}
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < k; ++j) {
h_b[i * k + j] = rand() % 1024;
}
}
//int *d_a, *d_b, *d_c;
//CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n));
// CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k));
// CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k));
// copy matrix A and B from host to device memory
//CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice));
//CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));
unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE;
unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 dimGrid(grid_cols, grid_rows);
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
CHECK(cudaEventRecord(start));
//CHECK(cudaEventQuery(start));
//gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k);
gpu_shared_mult_try2<<<dimGrid, dimBlock>>>(h_a, h_b, h_gpu, m, n, k);
CHECK(cudaGetLastError());
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
//CHECK(cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost));
//cudaThreadSynchronize();
cpu_matrix_mult(h_a, h_b, h_cpu, m, n, k);
int ok = 1;
for (int i = 0; i < m; ++i)
{
for (int j = 0; j < k; ++j)
{
if(fabs(h_cpu[i*k + j] - h_gpu[i*k + j])>(1.0e-10))
{
ok = 0;
}
}
}
if(ok)
{
printf("Pass!!!\n");
}
else
{
printf("Error!!!\n");
}
// free memory
// CHECK(cudaFree(d_a));
// CHECK(cudaFree(d_b));
// CHECK(cudaFree(d_c));
//CHECK(cudaFreeHost(h_a));
//CHECK(cudaFreeHost(h_b));
//CHECK(cudaFreeHost(h_cpu));
//CHECK(cudaFreeHost(h_gpu));
return 0;
}















 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









