







 这篇博客介绍了神经网络在手写数字分类中的应用,包括网络结构的解析,如输入层、隐藏层和输出层的功能。作者指出,虽然输入和输出层设计相对直观,但隐藏层的设计更依赖于启发式方法。网络通常采用前馈结构,避免反馈循环。此外,还探讨了递归神经网络的概念,但主要焦点放在前馈网络上。文章以一个三层神经网络为例,解释了如何识别单个手写数字,并讨论了为何使用10个输出神经元而非更少的原因。
这篇博客介绍了神经网络在手写数字分类中的应用,包括网络结构的解析,如输入层、隐藏层和输出层的功能。作者指出,虽然输入和输出层设计相对直观,但隐藏层的设计更依赖于启发式方法。网络通常采用前馈结构,避免反馈循环。此外,还探讨了递归神经网络的概念,但主要焦点放在前馈网络上。文章以一个三层神经网络为例,解释了如何识别单个手写数字,并讨论了为何使用10个输出神经元而非更少的原因。
接下来,我将介绍一种神经网络,它可以很好地对手写数字进行分类。为了做好准备,我们可以用一些术语来命名网络的不同部分。假设我们有网络:
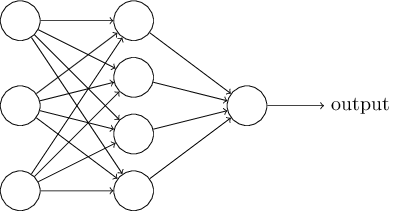
如前所述,该网络中最左边的层称为输入层,层内的神经元称为输入神经元。最右边的或输出层包含输出神经元,或者,在本例中,包含单个输出神经元。中间层称为隐藏层,因为这一层中的神经元既不是输入也不是输出。“隐藏”这个词听起来可能有点神秘——我第一次听到这个词的时候,我认为它一定有一些深刻的哲学或数学意义——但它实际上只意味着“不是输入或输出”。上面的网络只有一个隐藏层,但有些网络有多个隐藏层。例如,以下四层网络有两个隐藏层:
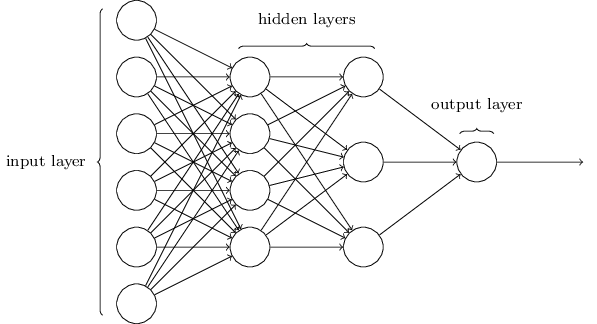
有些令人困惑的是,由于历史原因,这种多层网络有时被称为多层感知器或MLP,尽管它是由sigmoid神经元组成的,而不是感知器。我不打算在这本文中使用MLP术语,因为我认为它令人困惑,但我想警告你它的存在。
网络中输入和输出层的设计通常很简单。例如,假设我们试图确定手写图像是否描述了“9”。设计网络的一种自然方法是将图像像素的强度编码到输入神经元中。如果图像是64乘64的灰度图像,那么4096=64×64个输入神经元,强度在0到1之间适当缩放。输出层将只包含一个神经元,输出值小于0.5表示“输入图像不是9”,大于0.5表示“输入图像是9”。
虽然神经网络的输入层和输出层的设计通常很简单,但是隐藏层的设计却很有艺术性。特别是,用一些简单的经验法则来总结隐藏层的设计过程是不可能的。取而代之的是,神经网络研究人员开发了许多针对隐藏层的启发式设计方法,帮助人们从网络中获得想要的行为。例如,这种启发式算法可以用来帮助确定如何权衡隐藏层的数量和训练网络所需的时间。我们将在本书后面遇到几个这样的设计启发。
到目前为止,我们一直在讨论将一层的输出作为下一层的输入的神经网络。这种网络称为前馈神经网络。这意味着网络中没有循环——信息总是被转发,从不被反馈。如果我们有循环,我们最终会遇到σ 函数依赖于输出。这很难理解,所以我们不允许这样的循环。
然而,还有其他的人工神经网络模型,其中的反馈回路是可能的。这些模型被称为递归神经网络。这些模型中的想法是让神经元在静止前,在有限的时间内激发。这种放电可以刺激其他神经元,这些神经元可能会在一段时间后,也会在有限的时间内激发。这会导致更多的神经元放电,所以随着时间的推移,我们会得到一连串的神经元放电。在这样的模型中,循环不会引起问题,因为神经元的输出只会在稍后的某个时间影响其输入,而不是瞬间。
递归神经网络的影响比前馈网络小,部分原因是递归网络的学习算法(至少到目前为止)不太强大。但经常出现的网络仍然非常有趣。它们在精神上比前馈网络更接近我们大脑的工作方式。递归网络有可能解决一些重要的问题,而这些问题只能通过前馈网络来解决。然而,为了限制我们的范围,在这文中,我们将集中在更广泛使用的前馈网络。
简单的神经网络分类手写数字
定义了神经网络之后,让我们回到手写识别。我们可以将手写体数字识别问题分为两个子问题。首先,我们需要一种方法,将包含许多数字的图像分解为一系列独立的图像,每个图像包含一个数字。例如,我们想要分割如下图像:

把以上图片分割成:

我们人类很容易解决这个分割问题,但是计算机程序要正确地分割图像是一个挑战。一旦图像被分割,程序就需要对每个数字进行分类。例如,我们希望程序能识别上面的第一个数字,
 把它识别成5。
把它识别成5。
我们将着重编写一个程序来解决第二个问题,即对单个数字进行分类。我们这样做是因为一旦你有了一个很好的分类方法,分割问题就不那么难解决了。有许多方法可以解决分割问题。一种方法是尝试多种不同的图像分割方法,使用单独的数字分类器对每次尝试的分割进行评分。如果单个数字分类器对其在所有数据段中的分类都有信心,则试分割得到高分;如果分类器在一个或多个数据段中遇到很多问题,则试分割得到低分。其思想是,如果分类器在某个地方遇到了问题,那么它可能会遇到问题,因为分段选择不正确。这一思想和其他变体可以很好地解决分割问题。因此,我们不必担心分割问题,我们将集中精力开发一种神经网络,它可以解决更有趣和更困难的问题,即识别单个手写数字。为了识别单个数字,我们将使用三层神经网络:
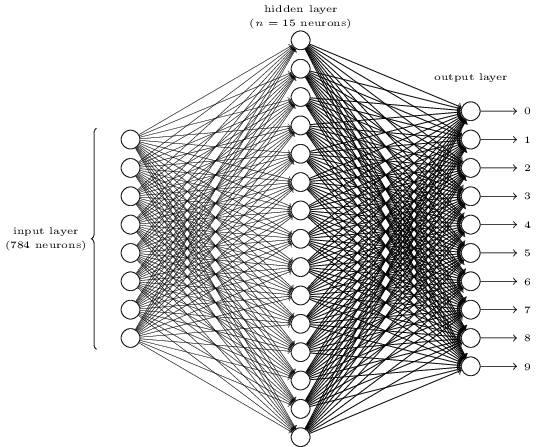
网络的输入层包含对输入像素值进行编码的神经元。正如下一节所讨论的,我们的网络训练数据将由许多28×28像素的扫描手写数字图像组成,因此输入层包含784=28×28个神经元。为了简单起见,我省略了上图中大部分784个输入神经元。输入像素为灰度,0.0表示白色,1.0表示黑色,中间值表示逐渐变暗的灰色。
网络的第二层是隐藏层。我们用n来表示这个隐藏层中的神经元数量,我们将用不同的n值来进行实验。这个例子显示了一个小的隐藏层,只包含n=15个神经元。
网络的输出层包含10个神经元。如果第一个神经元激发,即有一个输出≈1,则表示网络认为数字是0。如果第二个神经元触发,则表示网络认为数字是1。依此类推。更精确一点,我们将输出神经元从0到9进行编号,找出哪个神经元的激活值最高。如果这个神经元是,比方说,神经元编号6,那么我们的网络会猜测输入的数字是6,其他输出神经元也是如此。
你可能想知道为什么我们用10个输出神经元。毕竟,网络的目标是告诉我们哪个数字(0,1,2,…,9)对应于输入图像。一种看似自然的方法是只使用4个输出神经元,根据神经元的输出是接近0还是接近1,将每个神经元视为一个二进制值。4个神经元足以对答案进行编码,因为24=16比输入数字的10个可能值要多。为什么我们的网络要用10个神经元来代替呢?这不是效率低下吗?最终的证明是经验性的:我们可以尝试两种网络设计,结果表明,对于这个特殊的问题,有10个输出神经元的网络比有4个输出神经元的网络更好地学习数字识别。但这让我们想知道为什么使用10个输出神经元效果更好。有没有什么启发性的方法可以提前告诉我们应该使用10输出编码而不是4输出编码?
为了理解我们为什么要这样做,从第一原理来思考神经网络在做什么是有帮助的。首先考虑我们使用10个输出神经元的情况。让我们把注意力集中在第一个输出神经元上,它试图判断数字是否为0,它是通过权衡来自神经元隐藏层的证据来实现的。那些隐藏的神经元在做什么?好吧,为了论证起见,假设隐藏层中的第一个神经元检测到是否存在如下图像:

它可以通过对与图像重叠的输入像素进行重加权,而只对其他输入进行轻加权来实现这一点。以类似的方式,为了论证,我们假设隐藏层中的第二、第三和第四个神经元检测是否存在以下图像:

正如您可能已经猜到的,这四个图像一起构成了我们在前面显示的数字行中看到的0图像:

因此,如果这四个隐藏的神经元都在放电,那么我们就可以得出这个数字是0的结论。当然,这并不是我们可以用来得出这个图像是0的唯一证据——我们可以通过许多其他方式(比如,通过上述图像的翻译,或者轻微的扭曲)合法地得到0。但可以肯定的是,至少在这种情况下,我们会得出结论,输入是0。
假设神经网络是这样工作的,我们可以给出一个合理的解释,为什么最好是10个输出,而不是4个输出。如果我们有4个输出,那么第一个输出神经元将试图决定数字的最有效位是什么。要将最重要的一点与上面所示的简单形状联系起来是不容易的。很难想象有什么好的历史原因,数字的组成形状将与输出中的最高有效位密切相关。
尽管如此,这只是一个启发。没有人说三层神经网络必须按照我描述的方式运行,隐藏的神经元检测简单的组件形状。也许一个聪明的学习算法会找到一些权值分配,让我们只使用4个输出神经元。但是作为一种启发,我所描述的思维方式非常有效,并且可以在设计好的神经网络架构时节省大量时间。

















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









