









Multi-Resolution Graph Neural Network for Large-Scale Pointcloud Segmentation
Liuyue Xie, Tomotake Furuhata, Kenji Shimada
CMU
1 Introduction
1、为解决大量计算资源占用的问题,作者先将大尺度的点云转换为相似的点云簇。
2、点云具有无序性和特征不均匀的特性,这导致深度卷积神经网络的性能不太理想,为了解决这个问题,作者使用了图卷积神经网络,这样就利用了点云的无序性这一特性。
3、除了解决两个主要挑战外,我们提出的框架还具有双向多分辨率融合网络。该框架保留了来自多个卷积单元的丰富上下文信息。与单独来自最终卷积层的合成特征相比,来自不同分辨率的串联图特征提供了更丰富的特征表示。
2 Related Work
Voxel-based approach:
Point-based approach:
Graph-based approach:
3 Proposed Computational Framework
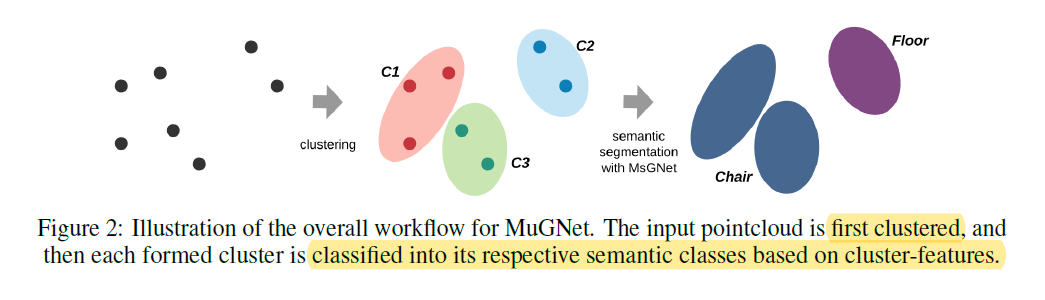
We propose MuGNet, a multiresolution graph neural network inspired by EfficientDet [25], to effectively translates large-scale pointclouds into directed connectivity graphs and efficiently segments the pointclouds from the formed graph with a bidirectional graph convolution network.
3.1 Clustering algorithm for graph formation
比较了无监督聚类和监督聚类
最后得出结论,无监督聚类会影响cluster的纯度,因此使用监督聚类,以提高cluster的纯度;监督聚类可以对S3DIS数据集2.6million点形成10^3个cluster。与对点云进行随机降采样相比,这种point到cluster的转换可以大幅度减少点云的size,同时会从原始点云中携带更丰富的上下文信息。


3.2 Cluster-feature Embedding
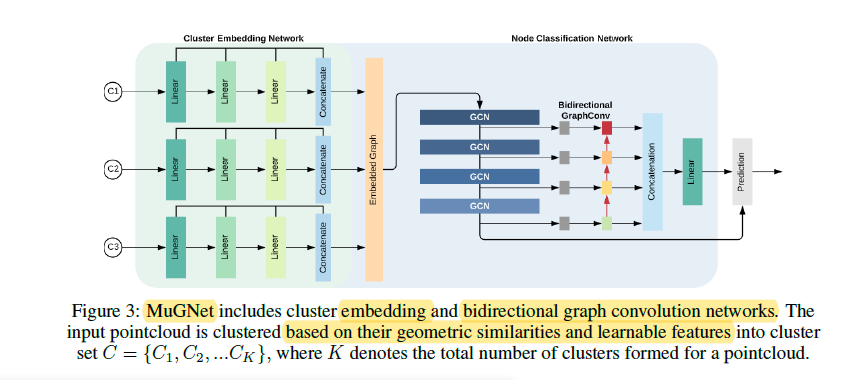
特征融合网络以三种不同的分辨率融合点云,然后三通道中的每一个通道都要经历一系列的二维卷积,将他们的特征连接起来。利用特征融合网络对cluster进行特征提取可以有效地识别局部特征和大的感受野中的具有代表性的特征。
3.3 Feature-fusion Backbone
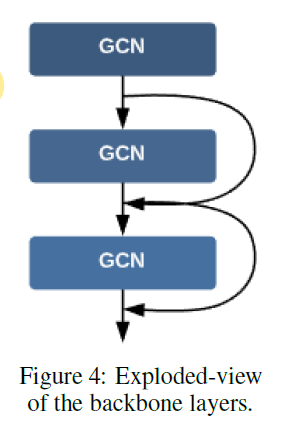
后几个GCN使用了残差网络: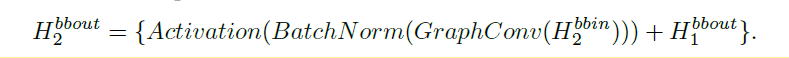
最后四个backbone网络的输出为:
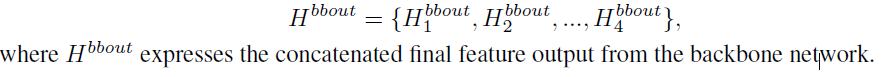
从残差输出的特征被并行地输入到双向图卷积网络,在backbone的最后,特征会被连接在一起以供cluster分类。
3.4 Bidirectioal-graph Convolution Network
设计了全新的金字塔操作,使每一个level生成同样数量的特征。
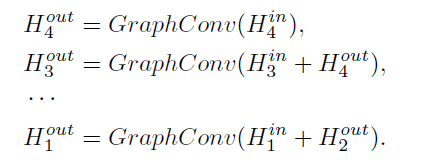
通过金字塔传播特征,会通过丰富聚合的特征信息来完善baseline的网络结构,但是仍然会受到单方向的信息传递。为了解决这个问题,作者提出bidirectional graph propagation network以由深到浅和由浅到深的两个方向来聚合特征;除了双向传递外,还为每个分辨率合并了一个从输入节点到输出节点的skip connection。这样特征信息被更密集的融合(more
densely fused),并且在一定程度上避免了梯度递减问题。
在将多个特征聚合为单个特征向量的时候,作者引入了一个权重矩阵,这样做的目的是为了让网络在训练的过程中自己学习到每一个分辨率特征的重要性。这种方法不仅避免了人类手动分配权重的偏见,并且与普通连接的内存占用相比更加优雅。
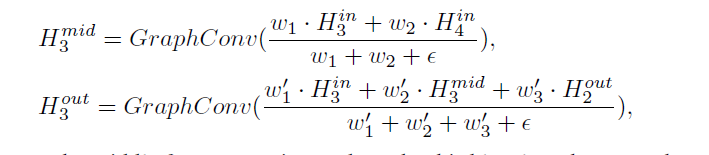
但是图神经网络会吸收特征,这会导致在深一点的网络层出现无效的特征融合。为了解决这个问题,作者将backbone网络和融合金字塔网络的特征一并传递给分割模块。
4 Results
4.1 Segmentation Results on S3DIS

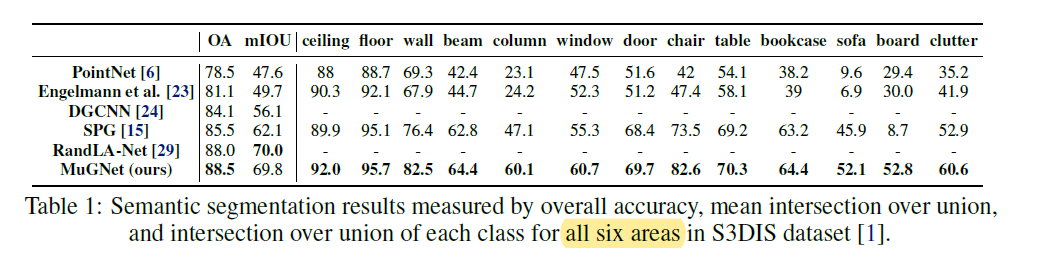
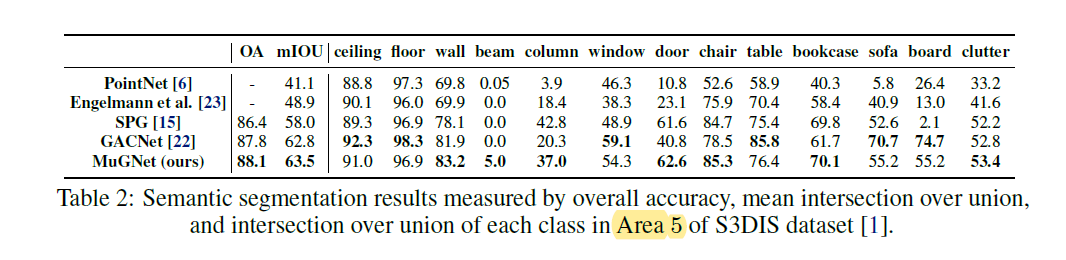
与其他方法的随机采样相比,作者的方法具有稳定性(It should be noted that our network has been validated to consistently arrive at the reported result for the five times that the network is trained.
In contrast, some of the baselines tend to produce inconsistent results due to their random sampling operations.)
大多数比较的基准网络都难以一次处理一次点云扫描。(They require drastic down-sampling and dividing of a large pointcloud room into small 1 x 1 x 1 blocks with sparse points)
作者的方案可以一次有效地处理多个房间(Our network, on the other hand, can effectively process multiple rooms in a single pass)
4.2 Segmentation Results on Virtual KITTI


4.3 Efficiency Analysis

单个RTX1080Ti GPU 可以推理45个房间(45 rooms (totaled 38726591 points );随着房间数量的增加,内存消耗的增长变得平缓。推理时间也仅仅以一个相对低的比率增长
增长趋势表明,随着要处理的扫描数量的增加,模型可以很好地扩展
4.4 Ablation Study
5 Conclusion
计算要求低:将点云转换为图表示,降低了计算要求,使用一个市面销售的GPU可以达到45个房间的扫描。
引入一个多分辨率cluster embedding network以高质量表示表示点云cluster;最后双向图卷积网络聚合了从不同分辨率得到的有用的特征。
















 882
882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











