







参考:【图像分割】Segment Anything(Meta AI)论文解读-CSDN博客
背景
- 提示分割任务:在给定任何分割提示下返回一个有效的分割掩码
- 目标:开发一个可提示的图像分割的基础模型,在一个广泛的数据集上预训练,解决新数据分布上的一系列下游分割问题
- 输入:提示+图片
- 输出:mask
模型
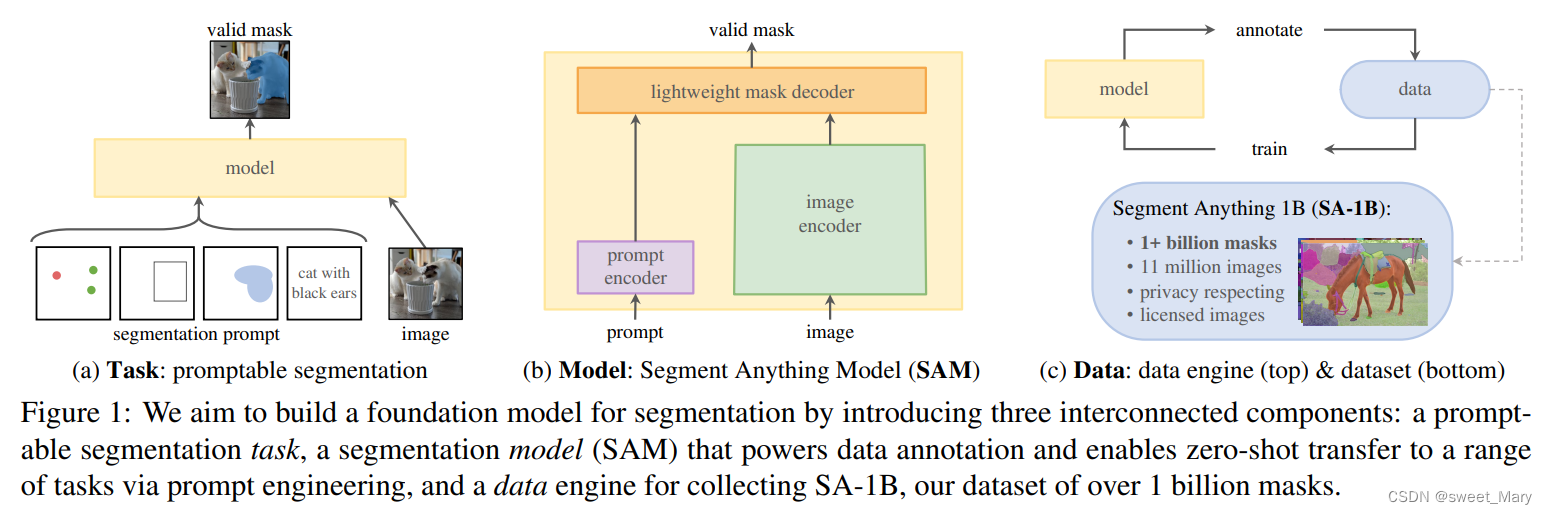
- prompt可以是一组前景/背景点、一个粗糙的框或掩码、自由形式的文本(上图中的Task)
- 三个约束条件:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个轻量级掩码解码器中来预测分割掩码。(上图中的Model)
- 数据加强:分三个阶段:在第一阶段,SAM(Segment everything model)协助注释器对掩码进行注释,类似于经典的交互式分割设置【train】。在第二阶段,SAM可以通过提示可能的对象位置来为对象子集自动生成掩码,注释器专注于对其余对象的注释,帮助增加掩码的多样性【annotate】。在最后一个阶段,我们用一个规则的前景点网格提示SAM,平均每张图像产生100个高质量的掩模。(上图中的Data)

- 图像编码器:预训练的视觉变换器 (ViT)
- 提示编码器
- 两组提示:稀疏的(点、方框、文本)和密集的(mask)
- 点和方框:位置编码与每种提示类型的学习嵌入相加
- 文本:用 CLIP的现成文本编码器来表示自由格式文本
- mask:使用卷积进行嵌入,并与图像嵌入进行元素求和
- 两组提示:稀疏的(点、方框、文本)和密集的(mask)
- 掩码解码器
- 有效地将图像嵌入、提示嵌入和输出token映射到掩码。该设计的灵感来自于DETR,采用了对(带有动态掩模预测头的)Transformer decoder模块的修改。















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









