









智能语音教程
基础简介
EAIDK的连接
- 本教程应用平台为EAIDK,即嵌入式人工智能开发套件,是专为AI开发者精心打造,面向边缘计算的人工智能开发套件,其主芯片采用ARM SOC的RK3399,操作系统为Linux Fedora 28和Android 8.1,本教程基于Linux Fedora 28系统。
系统登录
- EAIDK预装Fedora 28以及轻量级桌面系统LXDE。默认登录账号为openailab,密码为openailab。
网络连接
- 可用WiFi进行连接,左键点击右下角网络连接图标,点击需要连接的WiFi,输入密码,点击connect按钮,即可进行连接。更多有关EAIDK平台的资料可以到官方网站进行下载www.eaidk.com.
Linux常用命令简介
- Linux环境下读写文件、软件安装、程序编译等一系列操作都要通过命令进行实现,常用的命令如表所示。
| Linux命令 | 描述 |
|---|---|
| cd /home | 进入’/home’目录 |
| cd … | 返回上一级目录 |
| pwd | 显示工作路径 |
| ls | 查看目录中的文件 |
| Ls -l | 显示文件和目录的详细资料 |
| mkdir dir1 | 创建一个叫做 ‘dir1’ 的目录 |
| rm -f file1 | 删除一个叫做 ‘file1’ 的文件 |
| rm -rf dir1 | 删除一个叫做 ‘dir1’ 的目录并同时删除其内容 |
| cp file1 file2 | 复制一个文件 |
| tar –zxvf archive.tar.gz | 查询驱动是否支持该命令 解压archieve.tar.gz |
| cat file1 | 从第一个字节开始正向查看文件的内容 |
| yum install package_name | 安装/更新一个 deb 包 |
| find / -name file1 | 从 ‘/’ 开始进入根文件系统搜索文件和目录 |
| vim file | 标准编辑器:打开文件,若文件不存在则会创建 |
| make | 进行编译 |
| make clean | 清除编译结果 |
Vim编辑器使用简介:
- vim编辑器是所有Unix及Linux系统下标准的编辑器,他就相当于windows系统中的记事本一样,它的强大不逊色于任何最新的文本编辑器。他是我们使用Linux系统不能缺少的工具。由于对Unix及linux系统的任何版本,vim编辑器是完全相同的。
- vim 具有程序编辑的能力,可以以字体颜色辨别语法的正确性,方便程序设计;vim会依据文件扩展名或者是文件内的开头信息, 判断该文件的内容而自动的执行该程序的语法判断式,再以颜色来显示程序代码与一般信息;vim里面加入了很多额外的功能,例如支持正则表达式的搜索、多文件编辑、块复制等等。 这对于我们在Linux上进行一些配置文件的修改工作时是很棒的功能。
- vim编辑器有三种工作模式,即:1)命令模式——刚刚启动时即处于命令模式;2)输入模式——可以输入文本,在命令模式下,按i即可以进入输入模式,在输入模式下按下Esc即进入命令模式;3)底线命令模式——在命令模式下按下:(英文冒号)就进入了底线命令模式。
vim编辑器的常用底线命令有:
| flags | 作用 |
|---|---|
| w | 保存文件 |
| q | 退出程序 |
| wq | 保存文件并退出 |
| q! | 强制退出(不保存) |
| %s | 替换 |
| n | 查找 |
EAIDK-610上实现功能
在EAIDK-610上实现实时录音播放功能
- ALSA(Video for Linux two)为linux下音频设备程序提供了一套接口规范。包括一套数据结构和底层ALSA驱动接口。只能在linux下使用。它使程序有发现设备和操作设备的能力。它主要是用一系列的回调函数来实现这些功能。例如设置语音信号处理的采样率、长度、量化间隔等等。当然也可以用于其他多媒体的开发,如音频等。
- 在Linux下,所有外设都被看成一种特殊的文件,称为“设备文件”,可以像访问普通文件一样对其进行读写。一般来说,采用ALSA驱动的语音信号设备文件是kernel/sound。ALSA支持两种方式来采集声音:内存映射方式(mmap)和直接读取方式(read)。
- ALSA规范中不仅定义了通用API元素(Common API Elements),语音的格式(I),输入/输出方法(Input/Output),还定义了Linux内核驱动处理音频信息的一系列接口(Interfaces)。
ALSA音频采集原理
- ALSA支持内存映射方式(mmap)和直接读取方式(read)来采集数据,前者一般用于连续音频数据的采集,后者常用于静态图片数据的采集,本文重点讨论内存映射方式的音频采集。
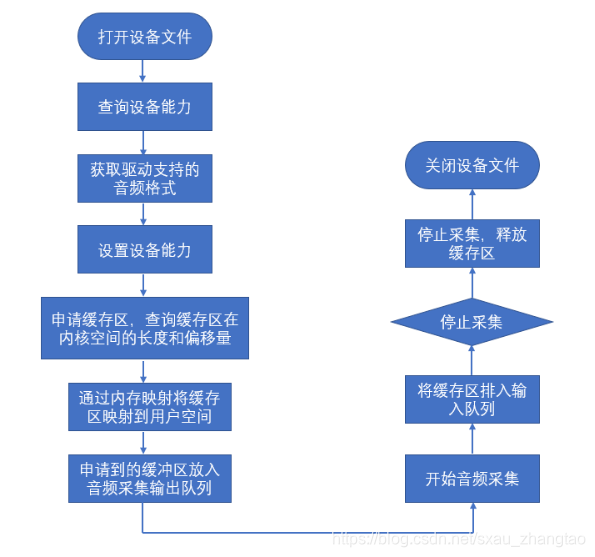
- 应用程序通过ALSA接口采集音频数据分为五个步骤:
①打开音频设备文件,进行音频采集的参数初始化,通过ALSA接口设置音频的采集窗口、采集的点阵大小和格式;
②其次,申请若干音频采集的帧缓冲区,并将这些帧缓冲区从内核空间映射到用户空间,便于应用程序读取/处理音频数据;
③将申请到的帧缓冲区在音频采集输入队列排队,并启动音频采集;
④驱动开始音频数据的采集,应用程序从音频采集输出队列取出帧缓冲区,处理完后,将帧缓冲区重新放入音频采集输入队列,循环往复采集连续的音频数据;
⑤停止音频采集。
在EAIDK-610上实现语音编解码
- 语音编码目的是为了减少传输码率或存储量,以提高传输或存储的效率。经过编码之后,同样的信道容量能传输更多路的信号,存储只需要较小容量的存储器。因而这类编码又称为压缩编码。压缩编码需要在保持可懂度与音质、降低数码率和降低编码过程的计算代价三方面折衷。语音编码大致分为四种方式:时域波形编码、变换域编码、参数编码和混合编码。
时域波形编码
- 时域波形编码只针对语音波形进行编码,不基于任何声学模型。这种方法在降低量化语音样本比特数的同时,又能够保持相对良好的语音质量。波形编码主要有脉冲编码调制(PCM)、自适应增量调制(ADM)、自适应差分脉冲调制(ADPCM)和自适应预测编码(APC)等。
- PCM编码技术的代表标准是国际电信联盟制定的G.711,该标准分为A律和u律两种版本,其中北美和日本主要采用u律,世界其他地区基本都采用A律。
- DM编码技术的代表标准是杜比的AC-1,采用的自适应增量编码调制(ADM),码率512kbps,主要用于卫星电视盒调频广播通信。
APC编码技术的代表标准是G.721,码率只有32kbps,相对于ADM技术的AC-1大大降低了传输带宽。 - ADPCM编码技术的代表标准是G.722,使用64kbps的码率,实现了7KHz的声音信号编码,将语音信号由电话质量提高到了调幅广播的质量。
变换域编码
- 变换域编码也不基于声学模型,主要有子带编码(SBC)和自适应变换编码(ATC)。SBC利用带通滤波器将语音频带分成若干子带,并分别进行采样、编码,编码方式可以用ADPCM或者ADM,SBC码率可以达到9.6kbps。可变SBC可使子带随共振峰变化,从而进一步提升编码效率。ATC则是先在时间维度上对语音信号进行分段,每段信号一般有64~512个采样点,再将每段时域信号正交变换到频域,得到相应的各组频域系数,然后分别对每一组系数的每个分量进行单独量化、编码和传输。
- SBC编码的典型代表标准是CCITT的G.722以及ISO的数字声音广播20kHz带宽声频编码标准。使用SBC编码的标准,在9.6kpbs的码率上能够得到中等的话音通信质量,在16~32kbps的码率上则能够得到高质量的重建话音。
ATC编码的典型代表标准是杜比的AC-2,对FFT变换系数进行编码,码率256kbps,应用于电脑声卡和ISDN网络。
参数编码
- 参数编码是基于声学模型的编码方法,通过分析并提取语音信号的特征参数,将这些能够合成语音信息的参数作为编码输出,传送给接收端,接收端通过参数还原语音。最常见的参数编码技术是线性预测编码。
- 参数编码的典型标准包括LPC-10以及其改进型LPC-10e。
混合编码
- 混合编码则结合了上述几种编码方式的优点,在保留参数模型技术精华的基础上,应用波形编码准则去优化激励信号,从而在4.8~9.6kbps的码率上获得了较高质量的重建语音。其代表技术是合成分析(A-B-S,Analysis-By-Synthesis)线性预测编码,采用知觉加权技术,在闭环搜索的基础上寻找主观意义上失真最小的激励矢量。得益于参数编码高压缩率的优势,成为了近年来的主流编码技术。
- 参数编码的典型标准包括G.723、G.728、G.729、EVRC、AMR等等,这些编码算法标准都能在9.6kbps甚至更低的码率上获得较高的话音质量,因此是2G、3G、4G移动通信系统中的主流编码标准。
自适应多码率(AMR)语音编码标准
-
自适应多码率(AMR,Adaptive Multi Rate)语音编码是由3GPP(3rd Generation Partnership Project)制定的应用于第三代移动通信W-CDMA系统中的语音编解码标准。它可以更加智能地解决信源和信道编码的速率分配问题,使得无线资源的配置和利用更加灵活和高效。它支持八种速率:12.2kbps、10.2kbps、7.95kbps、7.4kbps、6.7kbps、5.90kbps、5.15kbps和4.75kbps,另外,它还包括极低码率(1.8kbps)的背景噪声编码模式。
-
AMR语音编码采用的方案是代数码本激励线性预测(ACELP)技术,它是基于码本激励线性预测(CELP)的技术。AMR语音编码根据其实现功能大致可分为LPC分析、基音搜索、代数码本搜索三大部分。其中LPC分析完成的主要功能是获得10阶LPC滤波器的10个系数,并将他们转换为线谱对参数LSF,以及对LSF进行量化;基音搜索包括了开环基音分析和闭环基音分析两部分,以获得基音延迟和基音增益这两个参数;代数码本搜索则是为了获得代数码本索引和代数码本增益,还包括了对码本增益的量化。AMR的编码器的算法处理流程如图所示:
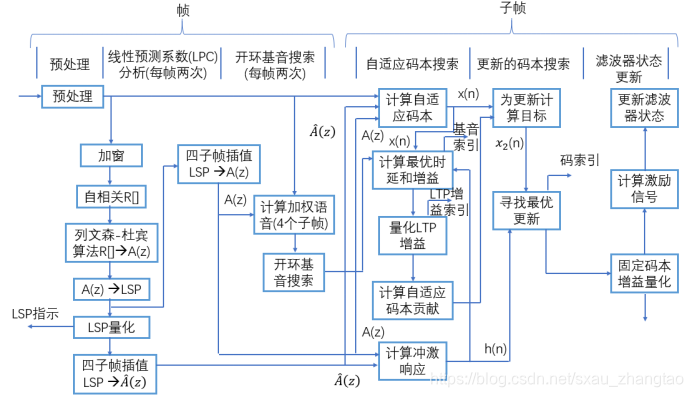
-
AMR语音编码器的功能包括九大部分:预处理、线性预测分析和量化、开环基音分析、脉冲响应的计算、目标响应的计算、自适应码本搜索和增益控制、代数码本的结构和搜索、自适应码本增益和固定码本增益的量化、滤波器状态更新。
-
AMR解码器的功能包括参数译码(LP系数、自适应码本矢量、自适应码本增益、固定码本矢量、固定码本增益)、语音合成和后置滤波,下图是AMR解码器的算法处理流程。
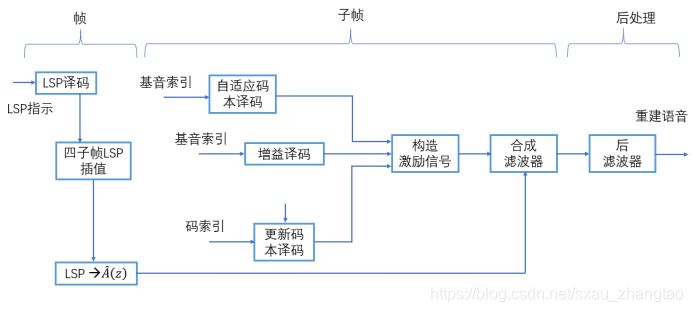
在EAIDK-610上实现NS自动降噪
- 噪音抑制是语音处理中的一个相当古老的话题,至少可以追溯到70年代。顾名思义,这个想法是采取嘈杂的信号,并尽可能多地消除噪音,同时对感兴趣的言论造成最小的失真。
- 在语音信号处理领域,噪声对用户体验的恶化起着重要的影响。在实时语音通信领域,环境噪声的存在不仅影响着通话双方的主观感受,更重要是因为噪声的存在,可能会导致语音编解码算法效率的下降,进而导致通信带宽的增加和通信信道的拥堵,严重时还会导致数据丢包,最终引发连锁效应。在语音识别领域,因为噪声的存在,可能会严重影响语音识别的准确率。在消费电子领域,如音频播放器,噪声的存在可能会导致音质的下降。
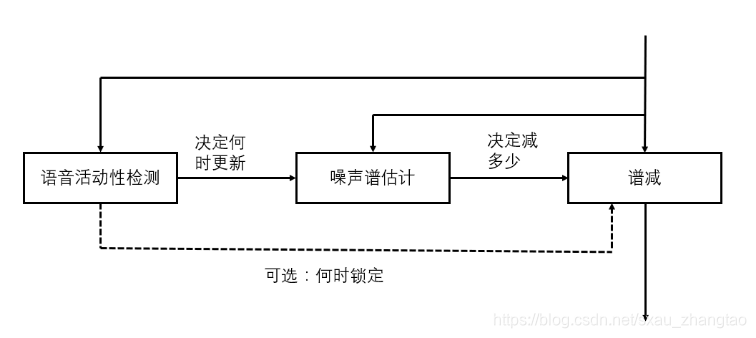
传统的噪声抑制算法
- 大致的工作流程就是语音活动检测(VAD)模块检测信号何时包含有效声音以及何时只是环境噪声。接下来噪声谱估计模块用于计算噪声的频谱特性(每个频率分量多少功率)。然后,把估计出的噪声功率谱从输入音频的功率谱中“减掉”(当然,实际中实现时往往不是直接减掉这么简单的处理)。
最小均方误差(LMS)算法
- 传统的噪声抑制方案往往效果差强人意,不仅仅无法消除快变噪声,还容易出现残留噪声严重影响听感体验的现象。后来,慢慢发展出了自适应噪声消除的技术。自适应噪声消除(ANC)技术已经成功地应用在语音增强、心电信号处理等领域。自适应噪声消除技术中应用最广泛的算法是最小均方误差(LMS)算法。
- LMS算法自适应滤波器具有结构简单、运算量小、易于硬件实现等优点。但是,LMS算法的缺点是收敛速度比较慢,而且收敛速度和权矢量噪声存在着矛盾——收敛速度加快的同时权噪声矢量也增加。
递归最小二乘 (RLS)算法
- 为了加快自适应滤波的收敛速度,后来出现了采用递归最小二乘 (RLS)算法的自适应滤波器进行噪声消除。
- RLS算法的优点是收敛速度快,其收敛性能与输入信号的频谱特性无关,但其缺点是计算复杂度很高,对于N 阶的滤波器,RLS算法的计算量为 o(N )。为了对非平稳信号进行跟踪,RLS算法引入了指数加权遗忘因子。该遗忘因子的引入,使得RLS算法能够对非平稳信号进行跟踪。
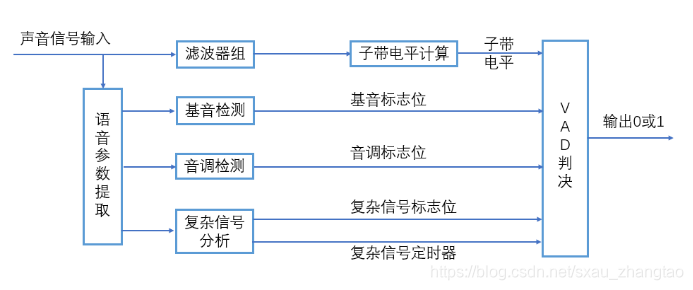
在EAIDK-610上实现VAD检测
- 音遍布在我们的日常生活中,是一种无所不在、无所不有的自然现象。在语音编码、人机语音交互、语音识别等应用领域都需要对声音的类型进行区分,语音活动检测(Voice Activity Detection,VAD)又称语音端点检测,语音边界检测,是对声音类型进行区分的通用手段,在多个应用领域都起着不可或缺的作用。
应用领域及作用
- 语音编码:在无线通信、VOIP等产品中,因为信道传输带宽有限,往往需要对话音进行高质量的编码,而对于环境噪声则可使用较低的质量进行编码。前者对应于高码率编码算法,后者则对应于低码率编码算法。
- 人机语音交互:近年来随着以智能音箱为代表的智能硬件产品的日益普及,人机语音交互也逐步成为消费类电子、家电、智能家居、机器人等产品的主流交互方式,在语音交互的过程中,为了保证较高的唤醒、语音识别效果,往往需要进行声音活动性检测,即VAD,将声音区分出话音和非话音。
- 语音识别:因为主流的语音识别模型均是基于机器学习的方法训练出来的,训练时为了保证效率,往往都会采用有监督(标注),这就需要预先标注出属于语音的部分,一种高效的手段就是通过VAD自动地把语音段标注出来。
VAD技术的算法原理
- 通过计算连续几帧的部分语音编码参数(即VAD参数的计算),来决定是否有话音存在。目前主流的方法大多使用语音信号能量和门限电平进行比较或者在多个子带进行语音信号能量和门限电平进行比较,更精细的做法还有使用语音帧能量、部分残差能量、线性预测增益、基音周期参数、语音谱测度和信噪比等参数。

















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









