






在3.1.9章节中我们已经详细讲述了Client在需要上传文件时,需要进行的操作以及相关实现模块,这一章节我们着重讲述datanode一侧支持数据传输的重要模块。
DataXceiverServer:
datanode在启动以后会首先初始化一个DataXceiverServer对象实例,这个对象是实现了Runnable接口的对象,它附着于一个特定线程监听在特定端口。
public void run()
{
while (datanode.shouldRun)
{
try
{
Socket s = ss.accept();
s.setTcpNoDelay(true);
new Daemon(datanode.threadGroup,
new DataXceiver(s, datanode, this)).start();
...
}}}
以上代码就是该线程对象的主要运行实体,他仅仅是监听端口处理连接请求,建立好连接以后,就会创建另一个线程处理该链接的请求,这个线程的运行实体为DataXceiver的实例对象,下面我们重点看一下DataXceiver的实现。
DataXceiver也是实现了Runnable接口的类,主要逻辑在run()方法中。
public void run()
{
DataInputStream in=null;
try {
in = new DataInputStream(
new BufferedInputStream(NetUtils.getInputStream(s),
SMALL_BUFFER_SIZE));
//首先读取协议版本号,并进行判断
short version = in.readShort();
if ( version != DataTransferProtocol.DATA_TRANSFER_VERSION ) {
throw new IOException( "Version Mismatch" );
}
boolean local =
s.getInetAddress().equals(s.getLocalAddress());
//读取操作码,追加文件时对应的是OP_WRITE_BLOCK
byte op = in.readByte();
...
}
//通过用户传过来的操作码,进行相应的操作
long startTime = DataNode.now();
switch ( op )
{
case DataTransferProtocol.OP_READ_BLOCK:
readBlock( in );
datanode.myMetrics.readBlockOp.inc(DataNode.now() - startTime);
if (local)
datanode.myMetrics.readsFromLocalClient.inc();
else
datanode.myMetrics.readsFromRemoteClient.inc();
break;
case DataTransferProtocol.OP_WRITE_BLOCK:
writeBlock( in );
datanode.myMetrics.writeBlockOp.inc(DataNode.now() - startTime);
...//省略
default:
throw new IOException("Unknown opcode " + op + " in data stream");
}
}
...
前面我们一直在讨论文件写入的实现,我们就首先看一下writeBlock( in );其中主要涉及到文件block传输协议关键字段的读取,完成数据传输链路的建立以及block数据块儿的传输。
private void writeBlock(DataInputStream in) throws IOException
{
DatanodeInfo srcDataNode = null;
//读取client传过来的blockID和时间戳,构造一个block。
Block block = new Block(in.readLong(),
dataXceiverServer.estimateBlockSize, in.readLong());
//数据传输链路中有多少台机器
int pipelineSize = in.readInt();
//是否是一次数据BLOCK恢复操作
boolean isRecovery = in.readBoolean();
//客户端名称
String client = Text.readString(in);
//客户端是否是集群中一台datanode机器
boolean hasSrcDataNode = in.readBoolean();
//如果客户端是集群中一台datanode机器,得到datanodeinfo信息
if (hasSrcDataNode)
{
srcDataNode = new DatanodeInfo();
srcDataNode.readFields(in);
}
//表示数据链中后续节点个数(每过一个节点,这个字段就减少一)
int numTargets = in.readInt();
...
//读取后续节点的详细datanodeinfo信息
DatanodeInfo targets[] = new DatanodeInfo[numTargets];
for (int i = 0; i < targets.length; i++)
{
DatanodeInfo tmp = new DatanodeInfo();
tmp.readFields(in);
targets[i] = tmp;
}
//生成一个BlockReceiver实例接收客户端传输过来的文件数据内容。
blockReceiver = new BlockReceiver(block, in, s
.getRemoteSocketAddress().toString(), s
.getLocalSocketAddress().toString(), isRecovery, client,srcDataNode, datanode);
//下面就是根据上面返回的datanode列表,建立数据传输链路
mirrorOut.writeShort(DataTransferProtocol.DATA_TRANSFER_VERSION); mirrorOut.write(DataTransferProtocol.OP_WRITE_BLOCK);
mirrorOut.writeLong(block.getBlockId());
mirrorOut.writeLong(block.getGenerationStamp());
mirrorOut.writeInt(pipelineSize);
mirrorOut.writeBoolean(isRecovery);
Text.writeString(mirrorOut, client);
mirrorOut.writeBoolean(hasSrcDataNode);
if (hasSrcDataNode)
{ // pass src node information
srcDataNode.write(mirrorOut);
}
mirrorOut.writeInt(targets.length - 1);
for (int i = 1; i < targets.length; i++)
{
targets[i].write(mirrorOut);
}
blockReceiver.writeChecksumHeader(mirrorOut);
mirrorOut.flush();
//发送完建立数据传输链的请求后,等待下一个节点的应答,返回空字串表示链路建立成功。
链路建立成功以后,应答给前一个节点,然后就是等待前一个节点发过来的数据,主要的实现是下面的方法。
blockReceiver.receiveBlock(mirrorOut, mirrorIn, replyOut,
mirrorAddr, null, targets.length);
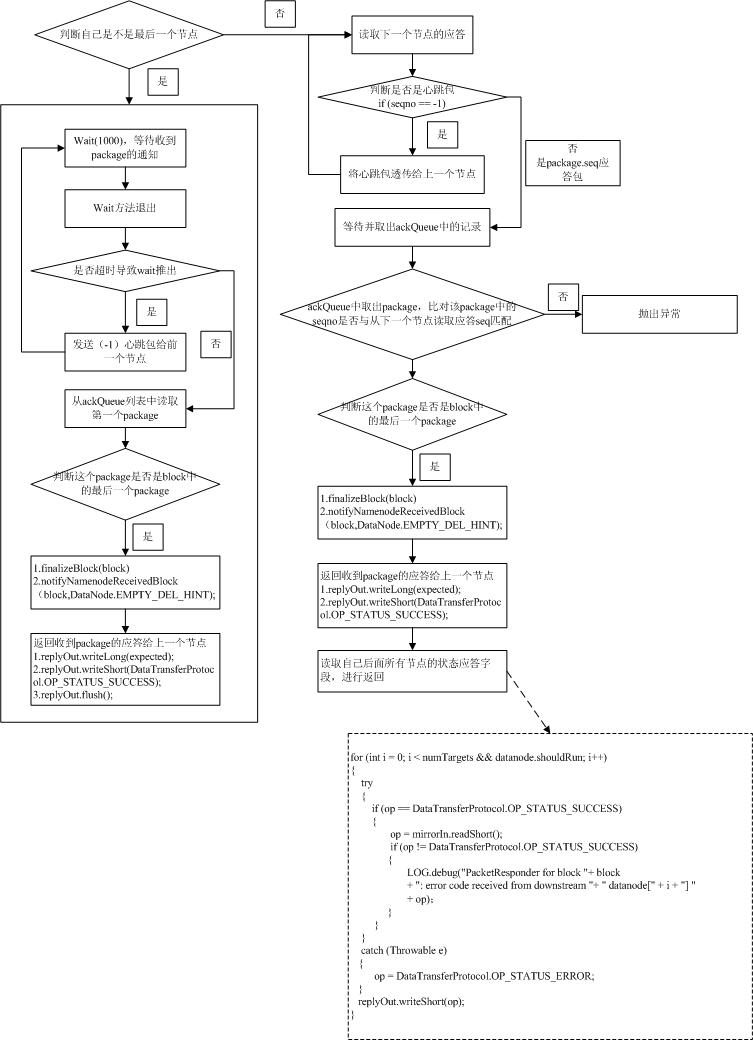
该方法中会初始化一个PacketResponder线程,这个线程的主要目的就是发送心跳包给上一个节点,同时接受下一个节点成功收到pachage后的应答,并发送应答信息给前一个节点,如果接受完一个完整的block,还有两个重要的操作要做:
1.datanode.data.finalizeBlock(block);(这部分我们后面再讲,主要是在datanode上完成block文件从tmp目录移动到正式的数据存放目录)
2.datanode.notifyNamenodeReceivedBlock(block,DataNode.EMPTY_DEL_HINT);(这个方法比较简单就是同时namenode自己收到一个block,namenode就可以在blockinfo中加入这个datanodeinfo的信息)
同时调用自身最重要的一个方法:receivePacket();
这个方法就是根据数据流传输协议,解析package数据包,将用户传来的数据追加到block文件中(当然还有很多数据校验的操作,block和本地文件会有一个映射关系,这部分我们后面介绍),这个方法中比较重要的方法就是readNextPacket(),主要是对ByteBuffer这个对象的灵活应用(详细可以参考代码)。
成功接收完成一个Package后就会做一个比较重要的操作就是:
((PacketResponder) responder.getRunnable()).enqueue(seqno,
lastPacketInBlock);
将接收到的package中的seqno构造一个package对象写入一个ackQueue队列,前面提到的PacketResponder线程从该队列中取出seqno应到给上一个节点。
下面我们看一下PacketResponder线程的主要流程:
下面我们共同讨论一下readBlock( in )方法的实现,这个方法主要应用于DFSClient读取block数据块的操作。从前面的协议字段详细描述表已经比较清晰地看出:客户端与datanode建立连接以后版本号验证通过,下面一个协议字段就是opCode,datanode通过这个操作码进行后面的操作,如果是OP_READ_BLOCK(81)表示DFSClient需要进行block数据块读取请求,我们详细分析一下这个方法。
private void readBlock(DataInputStream in) throws IOException
{
//根据协议解析blockid字段
long blockId = in.readLong();
//再解析时间戳字段构建出block对象
Block block = new Block(blockId, 0, in.readLong());
//读取block时的偏移量,有些时候从一个datanode读取block过程中,datanode当机,这个时候从另一个datanode继续读取该block就要有一个偏移量。
long startOffset = in.readLong();
//需要读取多少字节
long length = in.readLong();
String clientName = Text.readString(in);
OutputStream baseStream = NetUtils.getOutputStream(s,
datanode.socketWriteTimeout);
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(baseStream, SMALL_BUFFER_SIZE));
BlockSender blockSender = null;
try
{
try
{
//blockSender对象负责具体的block数据传送工作
blockSender = new BlockSender(block, startOffset, length, true, true, false, datanode, clientTraceFmt);
}
out.writeShort(DataTransferProtocol.OP_STATUS_SUCCESS);
//读取block数据按照协议规则写入out流对象中
long read = blockSender.sendBlock(out, baseStream, null);
...
}
}
我们看看blockSender在构造的过程中具体做了哪些操作。
{
this.blockLength = datanode.data.getLength(block);
...
try
{
if (!corruptChecksumOk ||
datanode.data.metaFileExists(block))
{
//从block的元数据文件中读取信息,主要是checksum类型以及每次做checksum的字节数
checksumIn=new DataInputStream(new
BufferedInputStream(datanode.data.getMetaDataInputStream(block) ,BUFFER_SIZE));
BlockMetadataHeader header = BlockMetadataHeader
.readHeader(checksumIn);
short version = header.getVersion();
...
checksum = header.getChecksum();
}
else
{
//如果没有读到元数据信息,使用缺省的checksum对象
checksum = DataChecksum.newDataChecksum(
DataChecksum.CHECKSUM_NULL, 16 * 1024);
}
...
checksumSize = checksum.getChecksumSize();
...
// 根据读取block的偏移位置确定偏移checksum数据流的位置
if (offset > 0)
{
long checksumSkip = (offset / bytesPerChecksum) * checksumSize;
if (checksumSkip > 0)
{
IOUtils.skipFully(checksumIn, checksumSkip);
}
}
seqno = 0;
//获得block数据的读取数据流,datanode.data这个对象就是FSDataset对象的实例,后续block的数据发送过程就是从这个对象中读取block数据
blockIn = datanode.data.getBlockInputStream(block, offset);
...
}















 4647
4647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









