






hadoop分时计算支持。
问题背景:
分布式计算平台接入的分析任务涉及的数据量非常庞大,数据分析需求又往往需要一天或一月完整数据,这就导致分布式计算平台接入的任务都集中在晚上凌晨开始执行(因为这个时间段,数据刚刚准备好),直接的影响就是平台的支撑能力,因为白天大部分机器空闲,晚上又忙的要死。
解决方案:
将用户白天上传的数据分时段进行map计算,中间结果存储HDFS,到晚上的时候只需要进行reduce汇总操作。
我们的想法:
1.业务用户自行进行分时计算,中间结果进行保留,最终reduce操作(需要业务进行优化,增加了平台使用门槛)
2.平台优化,用户仅仅只需要完成原来的mapreudce程序(用户需要完成的工作和不分段计算完全一样,用户满意度高)
平台优化的实现思路:
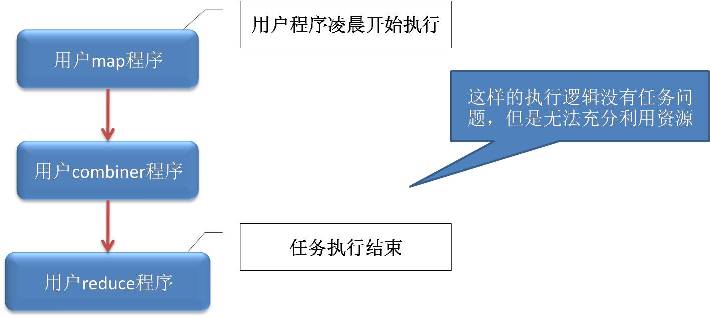
如下是缺省的mapreduce执行过程:
优化后数据处理流程如下:
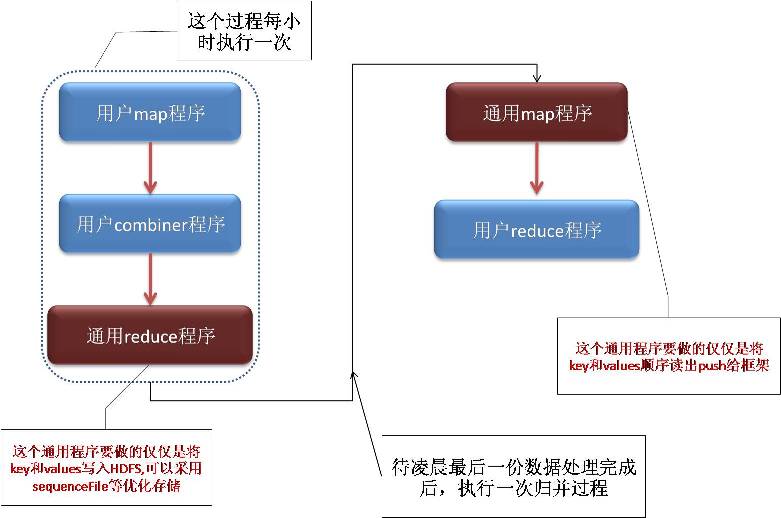
优化后的问题:
通用reduce程序将按part-00000-01H,part-00000-02H...... part-00001-01H,part-00001-02H,等按照partion组织文件名安排数据。
通用的map程序虽然只需要从part-00000-01H,part-00000-02H等文件中读出key,value;但是其产生的中间结果,还是很大的IO瓶颈,这样的优化效果仅仅减少了分散在每小时的map任务的数据处理逻辑代码;
进一步优化:
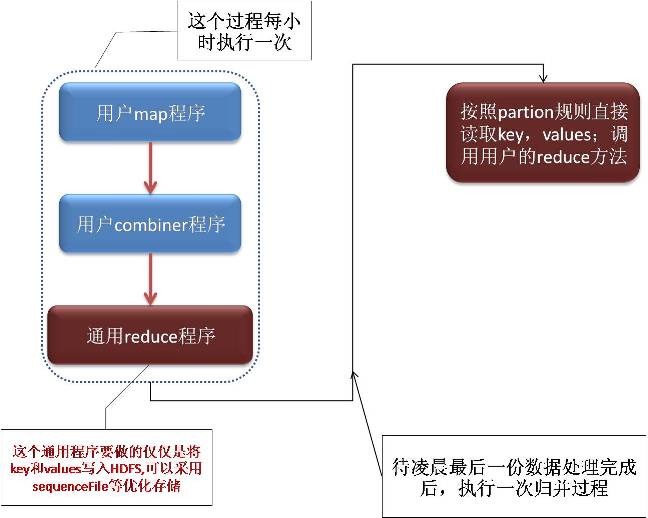
通用reduce程序将按part-00000-01H,part-00000-02H...... part-00001-01H,part-00001-02H,等按照partion组织文件名安排数据;也就是说part-00000为前缀的数据文件本身就是需要安排在一台机器进行reduce操作的。我们只需要从同一个前缀的多个文件中依次读出相同key的数据,整合在一起直接调用用户reduce方法。 直接省去了从map结果到reduce归并中间庞大的网络数据传输环节,可以大大提高数据处理性能以及资源利用率。















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









