






算法原理
bm的局部的代价聚合算法,受到噪声影响比较大,所以bm算法的速度虽然比较快,但是效果比较差,
而sgbm是一个半全局的代价聚合算法,计算代价的时候考虑周围领域的代价值,但不是一次性及算法
整个图像上的代价最小值(这样全局的算法效率比较低),而是利用动态规划的算法,从局部利用贪心的
思想计算全局。
能量代价函数如下:
总共包含三项:
-
第一项就是局部的代价SAD聚合值
-
第二项表示的是视差小于1的惩罚项
-
第三项表示的是视差大于1的惩罚项
这样第二项的惩罚项可以适应变化比较小的平滑区域,第三项的惩罚项适应的是变化比较大的边缘区域或者纹理丰富区域。
具体某一点像素p沿着方向r的路径代价函数如下:
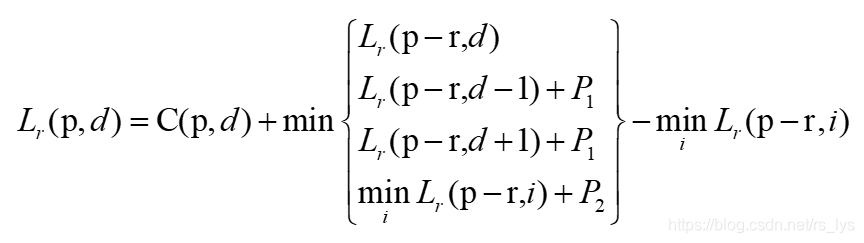
上面的公式就是一个BP算法的基本状态变化公式,平滑项就是选择当前方向的路径代价值、视差小于1的路径代价值加上p1、
当前方向范围内的最小值加上p2 这几项的最小值减去当前方向的最小代价聚合值。这样当前方向的代价聚合的上限为:
↵
总的代价聚合函数就是计算各个路径的路径代价之和:
最终就是计算最小的S对应的视差作为最优的视差。
代码分析
代价计算
static void calcPixelCostBT( const Mat& img1, const Mat& img2, int y,
int minD, int maxD, CostType* cost,
PixType* buffer, const PixType* tab,
int xrange_min = 0, int xrange_max = DEFAULT_RIGHT_BORDER )
{
int x, c, width = img1.cols, cn = img1.channels();
int minX1 = std::max(maxD, 0), maxX1 = width + std::min(minD, 0);
int D = (int)alignSize(maxD - minD, v_int16::nlanes), width1 = maxX1 - minX1;
//This minX1 & maxX2 correction is defining which part of calculatable line must be calculated
//That is needs of parallel algorithm
xrange_min = (xrange_min < 0) ? 0: xrange_min;
xrange_max = (xrange_max == DEFAULT_RIGHT_BORDER) || (xrange_max > width1) ? width1 : xrange_max;
maxX1 = minX1 + xrange_max;
minX1 += xrange_min;
width1 = maxX1 - minX1;
int minX2 = std::max(minX1 - maxD, 0), maxX2 = std::min(maxX1 - minD, width);
int width2 = maxX2 - minX2;
const PixType *row1 = img1.ptr<PixType>(y), *row2 = img2.ptr<PixType>(y);
PixType *prow1 = buffer + width2*2, *prow2 = prow1 + width*cn*2;
for( c = 0; c < cn*2; c++ )
{
prow1[width*c] = prow1[width*c + width-1] =
prow2[width*c] = prow2[width*c + width-1] = tab[0];
}
int n1 = y > 0 ? -(int)img1.step : 0, s1 = y < img1.rows-1 ? (int)img1.step : 0;
int n2 = y > 0 ? -(int)img2.step : 0, s2 = y < img2.rows-1 ? (int)img2.step : 0;
int minX_cmn = std::min(minX1,minX2)-1;
int maxX_cmn = std::max(maxX1,maxX2)+1;
minX_cmn = std::max(minX_cmn, 1);
maxX_cmn = std::min(maxX_cmn, width - 1);
if( cn == 1 ) //prow1 是左影像的响应值,
{
for( x = minX_cmn; x < maxX_cmn; x++ )
{
prow1[x] = tab[(row1[x+1] - row1[x-1])*2 + row1[x+n1+1] - row1[x+n1-1] + row1[x+s1+1] - row1[x+s1-1]];
prow2[width-1-x] = tab[(row2[x+1] - row2[x-1])*2 + row2[x+n2+1] - row2[x+n2-1] + row2[x+s2+1] - row2[x+s2-1]];
prow1[x+width] = row1[x];
prow2[width-1-x+width] = row2[x];
}
}
else
{
for( x = minX_cmn; x < maxX_cmn; x++ )
{
prow1[x] = tab[(row1[x*3+3] - row1[x*3-3])*2 + row1[x*3+n1+3] - row1[x*3+n1-3] + row1[x*3+s1+3] - row1[x*3+s1-3]];
prow1[x+width] = tab[(row1[x*3+4] - row1[x*3-2])*2 + row1[x*3+n1+4] - row1[x*3+n1-2] + row1[x*3+s1+4] - row1[x*3+s1-2]];
prow1[x+width*2] = tab[(row1[x*3+5] - row1[x*3-1])*2 + row1[x*3+n1+5] - row1[x*3+n1-1] + row1[x*3+s1+5] - row1[x*3+s1-1]];
prow2[width-1-x] = tab[(row2[x*3+3] - row2[x*3-3])*2 + row2[x*3+n2+3] - row2[x*3+n2-3] + row2[x*3+s2+3] - row2[x*3+s2-3]];
prow2[width-1-x+width] = tab[(row2[x*3+4] - row2[x*3-2])*2 + row2[x*3+n2+4] - row2[x*3+n2-2] + row2[x*3+s2+4] - row2[x*3+s2-2]];
prow2[width-1-x+width*2] = tab[(row2[x*3+5] - row2[x*3-1])*2 + row2[x*3+n2+5] - row2[x*3+n2-1] + row2[x*3+s2+5] - row2[x*3+s2-1]];
prow1[x+width*3] = row1[x*3];
prow1[x+width*4] = row1[x*3+1];
prow1[x+width*5] = row1[x*3+2];
prow2[width-1-x+width*3] = row2[x*3];
prow2[width-1-x+width*4] = row2[x*3+1];
prow2[width-1-x+width*5] = row2[x*3+2];
}
}
memset( cost + xrange_min*D, 0, width1*D*sizeof(cost[0]) );
buffer -= width-maxX2;
cost -= (minX1-xrange_min)*D + minD; // simplify the cost indices inside the loop
for( c = 0; c < cn*2; c++, prow1 += width, prow2 += width )
{
int diff_scale = c < cn ? 0 : 2;
// precompute
// v0 = min(row2[x-1/2], row2[x], row2[x+1/2]) and
// v1 = max(row2[x-1/2], row2[x], row2[x+1/2]) and
// to process values from [minX2, maxX2) we should check memory location (width - 1 - maxX2, width - 1 - minX2]
// so iterate through [width - maxX2, width - minX2)
for( x = width-maxX2; x < width-minX2; x++ )
{
int v = prow2[x];
int vl = x > 0 ? (v + prow2[x-1])/2 : v;
int vr = x < width-1 ? (v + prow2[x+1])/2 : v;
int v0 = std::min(vl, vr); v0 = std::min(v0, v);
int v1 = std::max(vl, vr); v1 = std::max(v1, v);
buffer[x] = (PixType)v0;
buffer[x + width2] = (PixType)v1;
}
for( x = minX1; x < maxX1; x++ )
{
int u = prow1[x];
int ul = x > 0 ? (u + prow1[x-1])/2 : u;
int ur = x < width-1 ? (u + prow1[x+1])/2 : u;
int u0 = std::min(ul, ur); u0 = std::min(u0, u);
int u1 = std::max(ul, ur); u1 = std::max(u1, u);
int d = minD;
for( ; d < maxD; d++ )
{
int v = prow2[width-x-1 + d];
int v0 = buffer[width-x-1 + d];
int v1 = buffer[width-x-1 + d + width2];
int c0 = std::max(0, u - v1); c0 = std::max(c0, v0 - u);
int c1 = std::max(0, v - u1); c1 = std::max(c1, u0 - v);
cost[x*D + d] = (CostType)(cost[x*D+d] + (std::min(c0, c1) >> diff_scale));
}
}
}
}
这里计算代价值方式是:(之前BM是直接计算代价, sgbm中采用左右临域平均值进行处理可以减少噪声点的影响,同时根据左右一致性选择最优的代价值)
int u1l = (prow1[x] + prow1[x-1])/2 ;
int u1r = (prow1[x] + prow1[x+1])/2 ;
u0 = min(prow1[x], u1l , u1r )
u1 = max(prow1[x], u1l , u1r )
u = prow1[x]
int u2l = (prow2[x] + prow2[x-1])/2 ;
int u2r = (prow2[x] + prow2[x+1])/2 ;
v0 = min(prow2[x], u2l , u2r )
v1 = max(prow2[x], u2l , u2r )
v = prow2[x]
#计算代价为:
c0 = max(v- u1, u0-v)
c1 = max(u- v1, v0 -u)
C = min(c0, c1)代价聚合
第一步是前向SP聚合
#计算上一行的-1, 0, 1 和当前一行的-1 四个方向的路径代价
for( x = x1; x != x2; x += dx )
{
int delta0 = P2 + *mem.getMinLr(lrID, x - dx);
int delta1 = P2 + *mem.getMinLr(1 - lrID, x - 1, 1);
int delta2 = P2 + *mem.getMinLr(1 - lrID, x, 2);
int delta3 = P2 + *mem.getMinLr(1 - lrID, x + 1, 3);
CostType* Lr_p0 = mem.getLr(lrID, x - dx);
CostType* Lr_p1 = mem.getLr(1 - lrID, x - 1, 1);
CostType* Lr_p2 = mem.getLr(1 - lrID, x, 2);
CostType* Lr_p3 = mem.getLr(1 - lrID, x + 1, 3);
Lr_p0[-1] = Lr_p0[D] = MAX_COST;
Lr_p1[-1] = Lr_p1[D] = MAX_COST;
Lr_p2[-1] = Lr_p2[D] = MAX_COST;
Lr_p3[-1] = Lr_p3[D] = MAX_COST;
CostType* Lr_p = mem.getLr(lrID, x);
const CostType* Cp = C + x*Da;
CostType* Sp = S + x*Da;
CostType* minL = mem.getMinLr(lrID, x);
}
#代价sp传递到4个方向,并聚合4个路径代价值
for( ; d < D; d++ )
{
int Cpd = Cp[d], L;
int Spd = Sp[d];
L = Cpd + std::min((int)Lr_p0[d], std::min(Lr_p0[d - 1] + P1, std::min(Lr_p0[d + 1] + P1, delta0))) - delta0;
Lr_p[d] = (CostType)L;
minL[0] = std::min(minL[0], (CostType)L);
Spd += L;
L = Cpd + std::min((int)Lr_p1[d], std::min(Lr_p1[d - 1] + P1, std::min(Lr_p1[d + 1] + P1, delta1))) - delta1;
Lr_p[d + Dlra] = (CostType)L;
minL[1] = std::min(minL[1], (CostType)L);
Spd += L;
L = Cpd + std::min((int)Lr_p2[d], std::min(Lr_p2[d - 1] + P1, std::min(Lr_p2[d + 1] + P1, delta2))) - delta2;
Lr_p[d + Dlra*2] = (CostType)L;
minL[2] = std::min(minL[2], (CostType)L);
Spd += L;
L = Cpd + std::min((int)Lr_p3[d], std::min(Lr_p3[d - 1] + P1, std::min(Lr_p3[d + 1] + P1, delta3))) - delta3;
Lr_p[d + Dlra*3] = (CostType)L;
minL[3] = std::min(minL[3], (CostType)L);
Spd += L;
Sp[d] = saturate_cast<CostType>(Spd);
}第二步是反向计算BP
for( x = width1 - 1; x >= 0; x-- )
{
CostType* Sp = S + x*Da;
CostType minS = MAX_COST;
short bestDisp = -1;
if( npasses == 1 )
{
CostType* Lr_p0 = mem.getLr(lrID, x + 1);
Lr_p0[-1] = Lr_p0[D] = MAX_COST;
CostType* Lr_p = mem.getLr(lrID, x);
const CostType* Cp = C + x*Da;
d = 0;
int delta0 = P2 + *mem.getMinLr(lrID, x + 1);
int minL0 = MAX_COST;
for( ; d < D; d++ )
{
int L0 = Cp[d] + std::min((int)Lr_p0[d], std::min(Lr_p0[d-1] + P1, std::min(Lr_p0[d+1] + P1, delta0))) - delta0;
Lr_p[d] = (CostType)L0;
minL0 = std::min(minL0, L0);
CostType Sval = Sp[d] = saturate_cast<CostType>(Sp[d] + L0);
if( Sval < minS )
{
minS = Sval;
bestDisp = (short)d;
}
}
*mem.getMinLr(lrID, x) = (CostType)minL0;通过构建前向BP聚合和反向BP聚合,相当于构建了5个方向的路径代价聚合,相当于一个弱化的全局代价函数。
视差计算
for( ; d < D; d++ )
{
int Sval = Sp[d];
if( Sval < minS )
{
minS = (CostType)Sval;
bestDisp = (short)d;
}
}找最小的代价聚合对应的视差d。
视差后处理
左右一致性原则
int _x2 = x + minX1 - d - minD;
if( mem.disp2cost[_x2] > minS )
{
mem.disp2cost[_x2] = (CostType)minS;
mem.disp2ptr[_x2] = (DispType)(d + minD);
}
if( 0 < d && d < D-1 )
{
// do subpixel quadratic interpolation:
// fit parabola into (x1=d-1, y1=Sp[d-1]), (x2=d, y2=Sp[d]), (x3=d+1, y3=Sp[d+1])
// then find minimum of the parabola.
int denom2 = std::max(Sp[d-1] + Sp[d+1] - 2*Sp[d], 1);
d = d*DISP_SCALE + ((Sp[d-1] - Sp[d+1])*DISP_SCALE + denom2)/(denom2*2);
}
else
d *= DISP_SCALE;
disp1ptr[x + minX1] = (DispType)(d + minD*DISP_SCALE);
}
for( x = minX1; x < maxX1; x++ )
{
// we round the computed disparity both towards -inf and +inf and check
// if either of the corresponding disparities in disp2 is consistent.
// This is to give the computed disparity a chance to look valid if it is.
int d1 = disp1ptr[x];
if( d1 == INVALID_DISP_SCALED )
continue;
int _d = d1 >> DISP_SHIFT;
int d_ = (d1 + DISP_SCALE-1) >> DISP_SHIFT;
int _x = x - _d, x_ = x - d_;
if( 0 <= _x && _x < width && mem.disp2ptr[_x] >= minD && std::abs(mem.disp2ptr[_x] - _d) > disp12MaxDiff &&
0 <= x_ && x_ < width && mem.disp2ptr[x_] >= minD && std::abs(mem.disp2ptr[x_] - d_) > disp12MaxDiff )
disp1ptr[x] = (DispType)INVALID_DISP_SCALED;
}唯一性检测
如果次最小视差和最小视差的的比值小于某一个阈值就剔除
去除离群的小离群点
参考上一章BM所讲的方式通过四连域构建相同的连通域,如果连通域面积小于一定的阈值就剔除。
视差亚像素化
主要采用相邻的视差值采用二次曲线拟合的方式,二次曲线需要三个点进行插值
(d-1, S(d-1)), (d, S(d)) , (d+1, S(d+1))
然后取曲线中的最小值。
if( 0 < d && d < D-1 )
{
// do subpixel quadratic interpolation:
// fit parabola into (x1=d-1, y1=Sp[d-1]), (x2=d, y2=Sp[d]), (x3=d+1, y3=Sp[d+1])
// then find minimum of the parabola.
int denom2 = std::max(Sp[d-1] + Sp[d+1] - 2*Sp[d], 1);
d = d*DISP_SCALE + ((Sp[d-1] - Sp[d+1])*DISP_SCALE + denom2)/(denom2*2);
}
else
d *= DISP_SCALE;滤波处理
采用双边滤波或者均值滤波,会更平滑。双边滤波可以参考https://blog.csdn.net/u013066730/article/details/87859184
算法优化
- 只采用前后左右这四个方向的聚合,这个时候可以先水平方向上的并行聚合处理,然后再进行垂直方向的并行聚合
- 直接在垂直方向上分多块进行分别求解代价值,每一块进行了一定程度上的重叠这样可以实现并行。














 9736
9736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









