







 本文探讨了VisionTransformer(ViT)这一基于Transformer架构的目标检测算法,介绍了其原理、论文详细内容以及相关的源代码资源。
本文探讨了VisionTransformer(ViT)这一基于Transformer架构的目标检测算法,介绍了其原理、论文详细内容以及相关的源代码资源。
目标检测算法-transformer系列-ViT(Vision Transformer)(附论文和源码)
一,ViT:
本文收录于ICLR2021,将之前用于自然语言处理的Tansformer架构引入了CV领域,引起了一波热潮。
1.1 概述
虽然Transformer架构已成为自然语言处理任务的标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。
本文证明了,CV领域不一定依赖CNN,使用纯粹的Transformer用于图片块序列,也可以很好的完成图像分类任务。通过实验表明,Vision Transformer (ViT)获得了出色的结果,且消耗的计算资源更少。
1.2 Self - Attention机制
在NLP领域,Self-Attention结构很常见,transformer等方法会在大型文本语料库上进行预训练,然后在较小的任务特定数据集上进行微调。它的可扩展性强、效率高,可以训练参数超过100B的模型,随着模型和数据集的增长,性能仍然没有饱和的迹象。Tansformer很香,所以在CV领域,很多人也尝试一些具有注意力机制的CNN,甚至完全代替一部分卷积,不过在GPU等硬件加速资源上,这种设计还没有得到有效扩展。
受Transformer的启发,作者将它直接从NLP领域转换到CV领域。具体来说,ViT的思想是把图片分割成小块,然后将这些小块作为一个线性的embedding作为transformer的输入,处理方式与NLP中的token相同,用监督训练的方式进行图像分类。
在实验过程中:
-
由于ViT缺少CNN隐藏层中的bias,所以当在数据量不足的情况下进行训练时,不能很好地泛化,效果不如CNN。
-
不过在训练大规模数据时,ViT的效果会反超CNN。
在介绍ViT之前,首先简要回顾一下self-attention的机制:
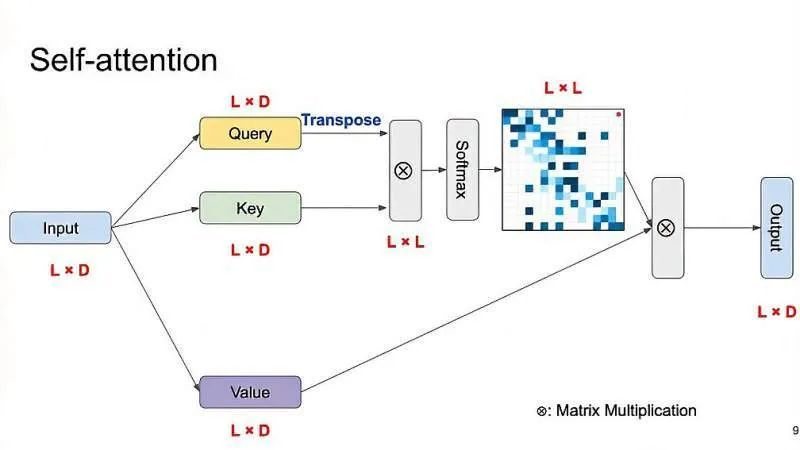
-
如图给定一个input矩阵;
-
转成相同维度的key和value;
-
query经过tanspose后和key相乘;
-
对相乘后结果的最后一个维度做了softmax,可以组成L*L的attention map。map里面每一行的元素总和为1(L×L的方块中,色块越深值越大,色块越浅值越小);
-
得到Query,Key和Value都是普通的1x1卷积,差别只在于输出通道大小不同;
-
将Query的输出转置,并和Key的输出相乘,再经过softmax归一化得到一个attention map;
-
将得到的attention map和Value逐像素点相乘,得到自适应注意力的特征图。
eg: 第一行中,第2个元素对第1个元素比较重要,第3个元素对第1个元素不重要,以此类推,第6和8个元素对它比较重要,其他元素不太重要。这么做的目的是让模型学到输入序列元素之间的重要程度。
1.3 模型结构
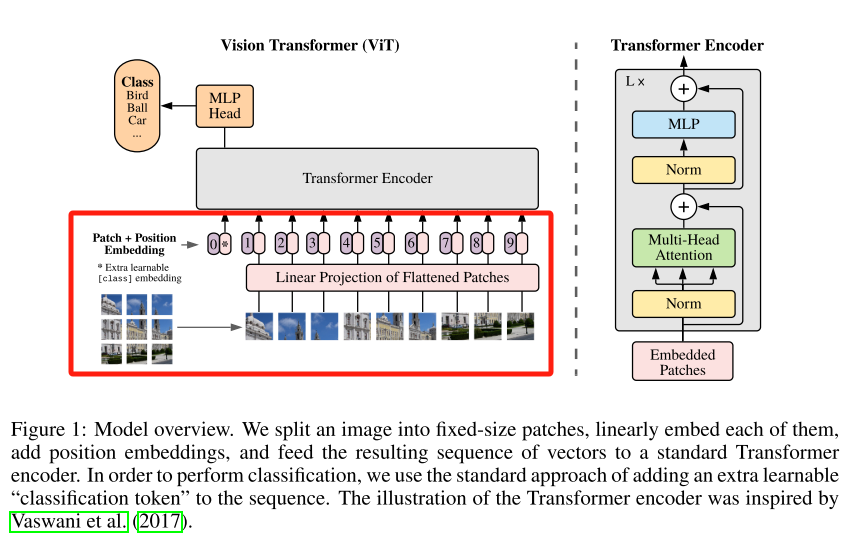
-
首先,需要把图片输入进网络,和传统的卷积神经网络输入图片不同的是,这里的图片需要分为一个个patch,如图中就是分成了9个patch。每个patch的大小是可以指定的,比如1 16×16等等。
-
然后把每个patch输入到embedding成,也就是Linear Projection of Flattened Patches,通过该层以后,可以得到一系列向量(token),9个patch都会得到它们对应的向量,然后在所有的向量之前加入一个用于分类的向量*,它的维度和其他9个向量一致。
-
此外,还需要加入位置信息,也就是图中所示的0~9。然后把所有的token输入Transformer Encoder中,然后把TransFormer Encoder重复堆叠L次,再将用于分类的token的输出输入MLP Head,然后得到最终分类的结果。

ViT 动态示意图
1.4 Embedding层
Embedding层如上面模型结构图中红框部分所示,标准的Transformer模块需要输入token序列,它是一个二维矩阵,也就是[token的数量,token的维度]。在实际实现中,直接用一个卷积层来实现。以论文中的VitB/16为例,步距为16,卷积核的大小也为16,卷积核的个数设置为768。
维度的变换是这样的:输入224*224*3的图片,通过卷积层变成14*14*768,然后打平高宽所对应的维度,变成196*768。当然,在输入Embedding层之前,需要加入类别和位置这两个参数。假设该图片属于A类别,就将1*768的向量与196*768的向量进行拼接,得到197*768的向量。最后再与位置编码进行数值上的相加,最后的向量是197*768。
1.4.1 图像块嵌入 (Patch Embeddings)
该模型的概述如上面图 1 所示。标准 Transformer 使用 一维标记嵌入序列 (Sequence of token embeddings) 作为输入。
为处理 2D 图像,将图像![]() reshape 为一个展平 (flatten) 的2D patches 序列
reshape 为一个展平 (flatten) 的2D patches 序列
![]()
,其中(H,W)为原始图像分辨率,C是原始图像通道数 (RGB图像C=3),(P,P)是每个图像patch的分辨率,由此产生的图像patch数N=HW/P^2。亦为 Vision Transformer 的有效输入序列长度。
Transformer 在其所有层中使用恒定的隐向量 (latent vector) 大小 D,将图像 patches 展平,并使用 可训练的线性投影 (FC 层) 将维度 P^2*C映射为D维,同时保持图像 patches 数N不变
上述投影输出即 图像块嵌入 (Patch Embeddings) (本质就是对每一个展平后的 patch vector,
![]()
做一个线性变换 / 全连接层
![]()
,由P^2*C维降维至D维,得到![]() ,好比于 NLP 中的 词嵌入 (Word Embeddings)。
,好比于 NLP 中的 词嵌入 (Word Embeddings)。
图像 patch 嵌入的实现为:
class PatchEmbed(nn.Module):""" Image to Patch Embedding """def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):super().__init__()# (H, W)img_size = to_2tuple(img_size)# (P, P)patch_size = to_2tuple(patch_size)# N = (H // P) * (W // P)num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])self.img_size = img_sizeself.patch_size = patch_sizeself.num_patches = num_patches# 可训练的线性投影 - 获取输入嵌入self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)def forward(self, x):B, C, H, W = x.shape# FIXME look at relaxing size constraintsassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# (B, C, H, W) -> (B, D, (H//P), (W//P)) -> (B, D, N) -> (B, N, D)# D=embed_dim=768, N=num_patches=(H//P)*(W//P)# torch.flatten(input, start_dim=0, end_dim=-1) # 形参:展平的起始维度和结束维度# 可见 Patch Embedding 操作 1 行代码 3 步到位x = self.proj(x).flatten(2).transpose(1, 2)return x
1.4.2 可学习的嵌入 (Learnable Embedding)
类似于 BERT 的类别 token [class],此处 为图像 patch 嵌入序列预设一个 可学习的嵌入
![]() ,该嵌入在 Vision Transformer 编码器输出的状态/特征
,该嵌入在 Vision Transformer 编码器输出的状态/特征
![]()
用作 图像表示 y (等式 4)。无论是预训练还是微调,都有一个 分类头 (Classification Head) 附加在
![]() 之后,从而用于图像分类。在预训练时,分类头为 一个单层 MLP;在微调时,分类头为 单个线性层 (多层感知机与线性模型类似,区别在于 MLP 相对于 FC 层数增加且引入了非线性激活函数,例如 FC + GELU + FC 形式的 MLP)。
之后,从而用于图像分类。在预训练时,分类头为 一个单层 MLP;在微调时,分类头为 单个线性层 (多层感知机与线性模型类似,区别在于 MLP 相对于 FC 层数增加且引入了非线性激活函数,例如 FC + GELU + FC 形式的 MLP)。
更明确地,等式 1 中给长度为N的嵌入向量后追加了一个分类向量,用于训练 Transformer 时学习类别信息。假设将图像分为N个图像块
![]()
,输入到 Transformer 编码器中就有N个向量,但该取哪一个向量用于分类预测呢?都不合适!一个合理的做法是手动添加一个可学习的嵌入向量作为用于分类的类别向量 xclass,同时与其他图像块嵌入向量一起输入到 Transformer 编码器中,最后取追加的首个可学习的嵌入向量作为类别预测结果。所以,追加的首个类别向量可理解为其他N个图像块寻找的类别信息。从而,最终输入 Transformer 的嵌入向量总长度为N+1。可学习嵌入 在训练时随机初始化,然后通过训练得到,其具体实现为:
### 随机初始化self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # shape = (1, 1, D)### 分类头 (Classifier head)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()### 前馈过程 (Forward)B = x.shape[0] # Batch Size# 通过 可学习的线性投影 获取 Input Imgaes 的 Patch Embeddings (实现在 3.1 节)x = self.patch_embed(x) # x.shape = (B, N, D)# 可学习嵌入 - 用于分类cls_tokens = self.cls_token.expand(B, -1, -1) # shape = (B, 1, D)# 按元素相加 附带 Position Embeddingsx = x + self.pos_embed # shape = (B, N, D) - Python 广播机制# 按通道拼接 获取 N+1 维 Embeddingsx = torch.cat((cls_tokens, x), dim=1) # shape = (B, N+1, D)
1.4.3 位置嵌入 (Position Embeddings)
位置嵌入也被加入图像块嵌入
![]()
,以保留输入图像块之间的空间位置信息。不同于 CNN,Transformer 需要位置嵌入来编码 patch tokens 的位置信息,这主要是由于 自注意力 的 扰动不变性 (Permutation-invariant),即打乱 Sequence 中 tokens 的顺序并不会改变结果。
相反,若不给模型提供图像块的位置信息,那么模型就需要通过图像块的语义来学习拼图,这就额外增加了学习成本。ViT 论文中对比了几种不同的位置编码方案:
无位置嵌入1-D 位置嵌入 (1D-PE):考虑把 2-D 图像块视为 1-D 序列2-D 位置嵌入 (2D-PE):考虑图像块的 2-D 位置 (x, y)相对位置嵌入 (RPE):考虑图像块的相对位置
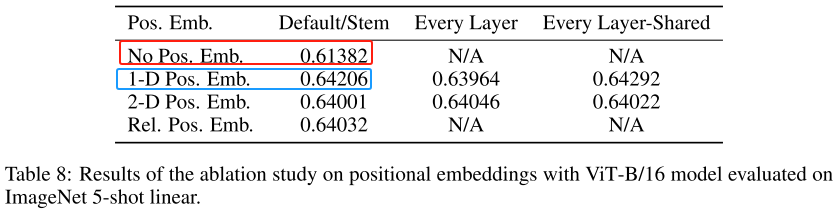
关于位置编码的作用,作者也做了实验,从上表可以看出,一维的位置编码(蓝色框)比不加位置编码(红色框)多了近3个点,而且一维的编码比二维的位置编码或者相对位置编码效果也要好一点。
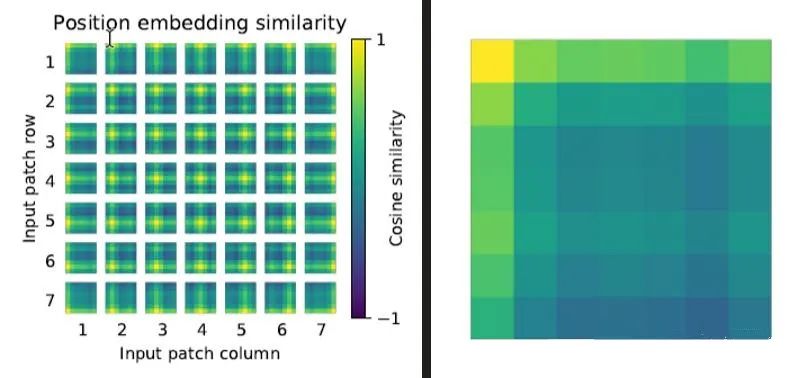
关于位置编码的可视化,我们针对每个patch的位置编码,和其他位置上的编码求余弦相似度得到上图。例如,图中的patch代表原图中32*32的一块区域,共有(224/32)* (224/32) = 7*7的区域。每个块由7*7个小块构成,每个小块的颜色代表当前patch和该行索引和列索引对应patch的相似度,颜色越接近绿色相似度越低,越接近黄色,相似度越高。第一行第一列的patch,我们把它放大来看,发现最左上角的点是黄色,代表和第一行第一列的patch相似度最高(因为第一行第一列是本身的位置,相似度当然最高)。其次,第一行和第一列的相似度也较高,表示它和当前行以及当前列的patch相似度较高。其他位置的相似度就比较低了。以此类推,可以得到7*7个patch的相似度情况。
1.5 实验
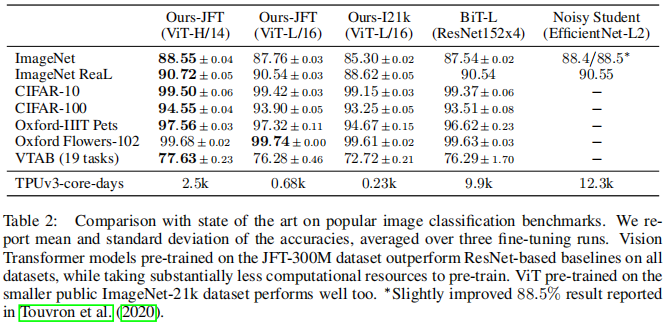
ViT 并不像 CNN 那样具有 Inductive Bias,若直接在 ImageNet 上训练,同 level 的 ViT 效果不如 ResNet。但若先在较大的数据集上预训练,然后再对特定的较小数据集进行微调,则效果优于 ResNet。比如 ViT 在Google 私有的 300M JFT 数据集上预训练后,在 ImageNet 上的最好的 Top-1 ACC 可达 88.55%,这在当时已和 ImageNet上的 SOTA 相当了 (Noisy Student EfficientNet-L2 效果为 88.5%,Google 最新的 SOTA 是 Meta Pseudo Labels,效果可达 90.2%):
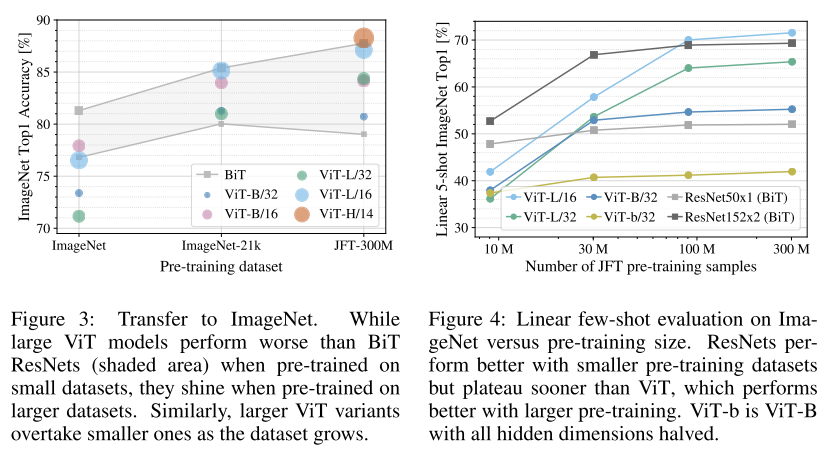
那么 ViT 至少需要多大的数据量才能比肩 CNN 呢?结果如下图所示。可见预训练的数据量须达到 100M 时才能凸显 ViT 的优势。Transformer 的一个特色其 Scalability:当模型和数据量提升时,性能持续提升。在大数据下,ViT 可能会发挥更大的优势。
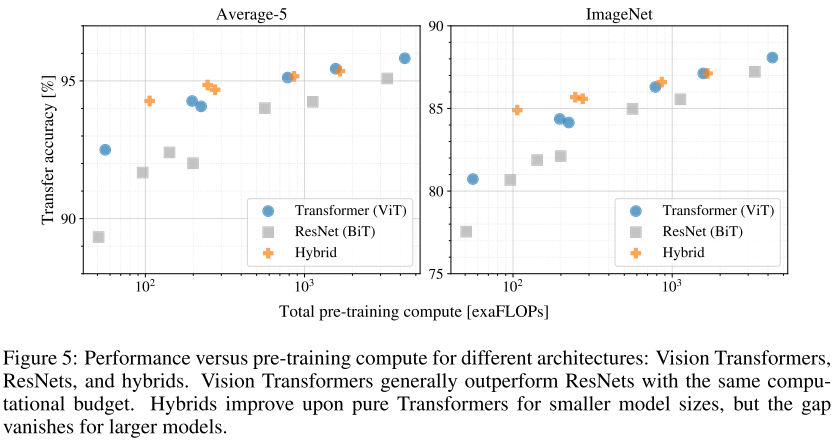
Transformer、ResNet 与 Hybrid Transformer 三者的性能变化比较:
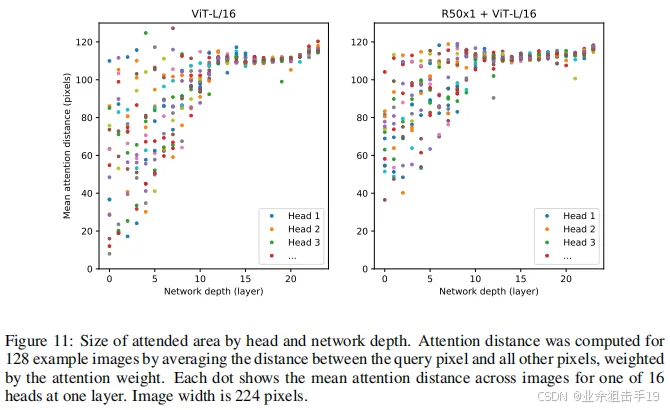
此外,论文分析了 不同 Layers 的 Mean Attention Distance,其类比于 CNN 的感受野。结果表明:前面层的 “感受野” 虽然差异很大,但总体相比后面层 “感受野” 较小;而模型后半部分 “感受野” 基本覆盖全局,和 CNN 比较类似,说明 ViT 也最后学习到了类似的范式。
当然,ViT 还可根据 Attention Map 来可视化,得知模型具体关注图像的哪个部分,从结果上看比符合实际:

1.6 ViT总结:
ViT作用:
-
推翻了 2012 Alexnet 提出的 CNN 在 CV 的统治地位
-
有足够多的预训练数据,NLP 的 Transformer 搬运到CV,效果很好
-
打破 CV 和 NLP 的壁垒,给 CV、多模态挖坑
ViT 都能处理的四种情况:
-
遮挡
-
数据分布的偏移(纹理的去除)
-
鸟头部+对抗的patch
-
图片打散重新排列组合
二,相关地址:
论文地址:https://arxiv.org/pdf/2010.11929.pdf
代码地址:https://github.com/google-research/vision_transformer
https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
三,参考文章:
https://arxiv.org/pdf/2010.11929.pdf
https://zhuanlan.zhihu.com/p/418184940
https://zhuanlan.zhihu.com/p/340149804
https://zhuanlan.zhihu.com/p/427388113

















 3236
3236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









