







本文首发于微信公众号:人工智能于图像处理
常见的关键点
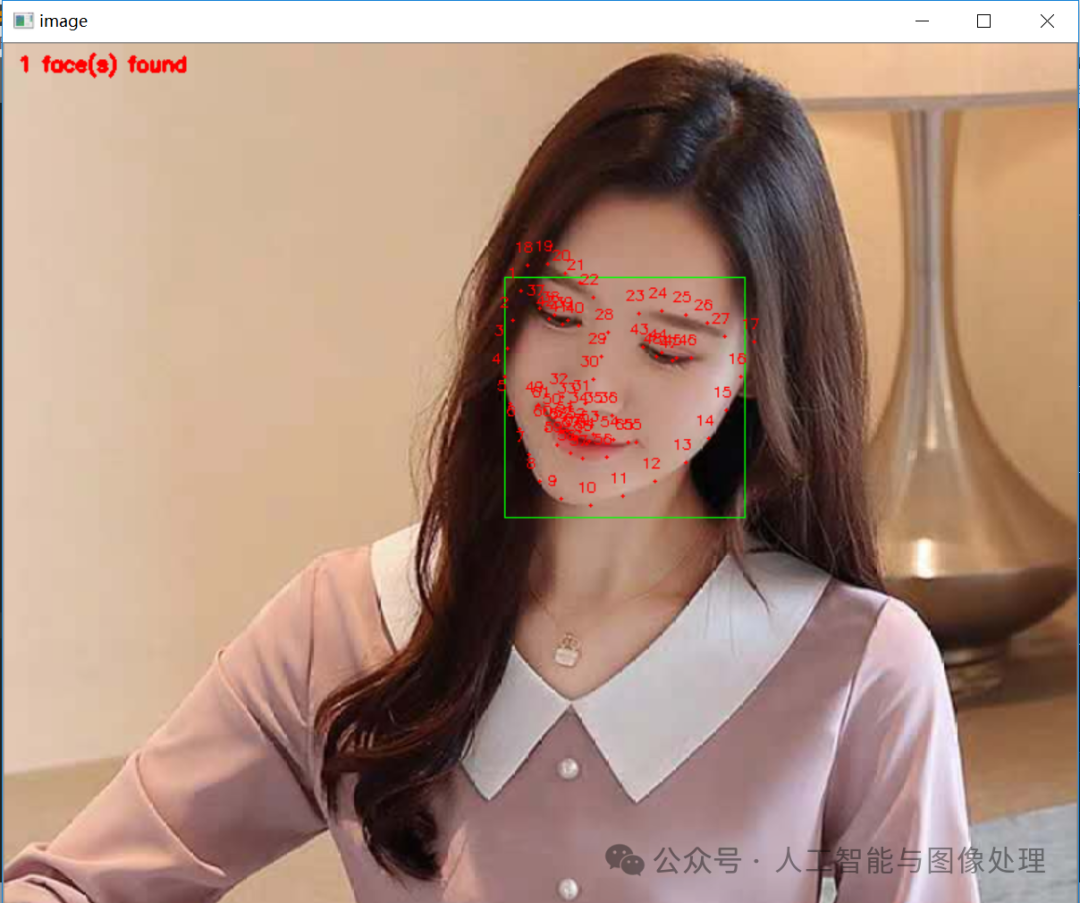
人脸关键点检测

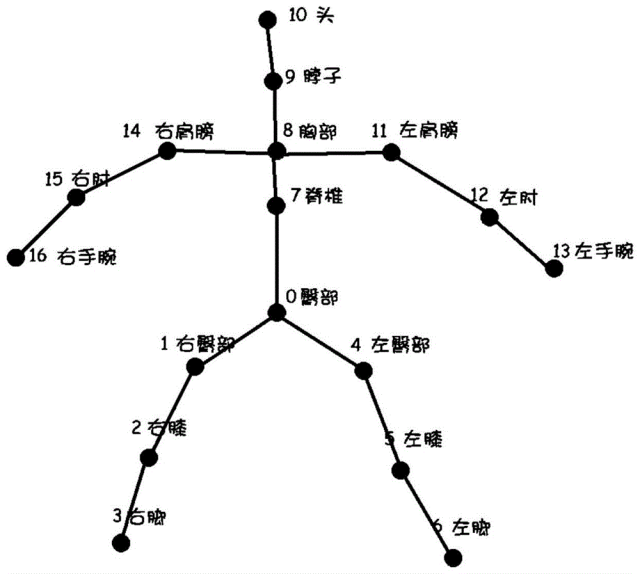
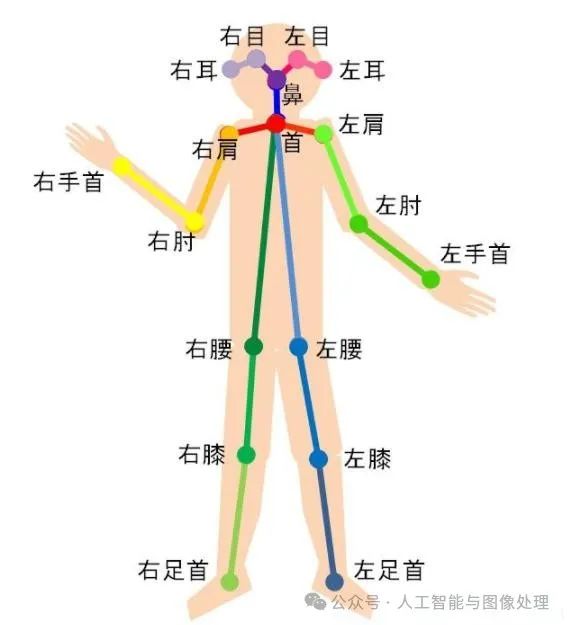
人体关键点检测
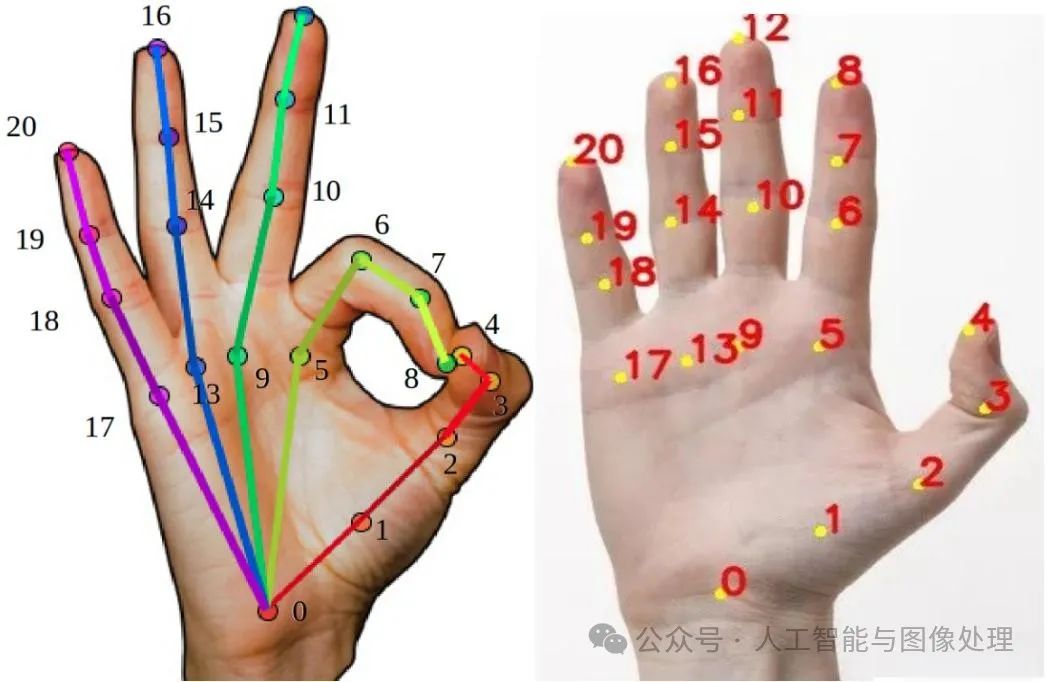
手部关键点检测
一,关键点检测算法
关键点检测(Keypoint Detection)是一种计算机视觉技术,旨在定位对象或人体上特定点的位置。这些点通常是具有重要意义的解剖学或结构特征,例如人的关节点(肘部、膝盖、肩膀等)、面部特征点(眼睛、鼻子、嘴巴等)或物体的关键点(例如汽车的车轮、门把手等)。
二,关键点检测的应用
-
人体姿态估计(Human Pose Estimation):用于检测人体的主要关节点,从而估计出人体的姿态,广泛应用于健身监控、舞蹈跟踪、动作捕捉等。
-
面部关键点检测(Facial Landmark Detection):用于识别面部特征点,应用于表情识别、人脸验证、面部解锁等。
-
物体关键点检测:用于检测物体的特征点,如汽车、家具等的关键部位,应用于增强现实(AR)、物体识别等领域。
三,关键点检测的工作原理
关键点检测通常基于深度学习模型,通过训练带有标注的关键点位置的数据集,使模型学会在新图像中自动检测这些关键点。关键点检测的过程可以分为以下几步:
-
1)数据预处理:包括图像的标准化、数据增强等,以提高模型的泛化能力。
-
2)特征提取:通过卷积神经网络(CNN)提取图像的深层特征,这些特征能够很好地表示图像中的重要信息。
-
3)关键点预测:利用全连接层或卷积层预测图像中关键点的位置。常见的输出形式有两种:
-
回归方法:直接回归出每个关键点的坐标。
-
热力图方法(Heatmap):生成每个关键点的概率热力图,通过热力图的峰值来确定关键点的位置。
-
4)后处理:包括非极大值抑制(NMS)、坐标校正等,进一步提高关键点检测的精度。
四,常见算法和模型
-
1)OpenPose:一种经典的人体姿态估计模型,可以同时检测多个人体的关键点,输出人体的骨架图。
-
2)HRNet:一种高分辨率网络,能够保留图像的高分辨率信息,提升关键点检测的精度。
-
3)DETR:一种基于Transformer的检测模型,也可以应用于关键点检测任务。
-
4)YOLO-KP:一种将YOLO模型用于关键点检测的改进版本,结合了目标检测和关键点检测的优势。
五,回归与热力图方法分析
5.1 回归方法
原理:
回归方法直接将关键点的位置作为一个坐标对 (x,y)进行预测。模型的任务是学习从输入图像到这些坐标之间的映射关系。
过程:
-
1)特征提取: 输入图像首先通过卷积神经网络(CNN)提取出高维特征。
-
2)全连接层或卷积层: 提取的特征接着通过全连接层(或卷积层)直接输出关键点的坐标值。例如,对于人体姿态估计任务,如果要检测17个关键点,模型的最后一层输出会是一个长度为34的向量(每个关键点的 x和 y坐标)。
-
3)损失函数: 回归方法通常使用欧氏距离(L2损失)来衡量预测的关键点坐标与真实坐标之间的差异。
优点:
-
1)简洁直接: 预测直接得到关键点坐标,不需要复杂的后处理。
-
2)快速: 计算简单,预测效率高,适合实时应用。
缺点:
-
1)精度有限: 对于高分辨率图像或复杂背景下,直接回归坐标的精度可能不足。
-
2)难以处理多尺度问题: 不同尺度下关键点的定位难以统一处理。
5.2 热力图方法
原理:
热力图方法不是直接回归出关键点坐标,而是预测出每个关键点的概率分布图(热力图)。在热力图上,关键点的位置对应最高概率的区域。
过程:
-
1)特征提取: 图像首先经过卷积神经网络,提取出深层特征。
-
2)热力图生成: 提取的特征通过卷积层生成每个关键点的热力图。热力图的每个像素点表示关键点出现在该位置的概率。
-
3)热力图后处理:
通过寻找热力图中的最大值(通常采用非极大值抑制)来确定关键点的坐标。使用一些插值方法可以进一步提升坐标的精度。
-
4)损失函数: 热力图方法常用均方误差(MSE)或交叉熵损失来衡量预测热力图与真实热力图之间的差异。真实热力图通常是通过在真实关键点位置生成高斯分布得到的。
优点:
-
1)高精度: 热力图能够在特征图上保留更多的空间信息,从而提高关键点定位的精度,尤其是在高分辨率任务中。
-
2)适应复杂场景: 热力图方法对复杂背景或遮挡有更好的鲁棒性。
缺点:
-
1)计算复杂: 热力图生成和后处理相对复杂,计算量较大,不如回归方法高效。
-
2)对分辨率敏感: 热力图的分辨率往往比输入图像低,可能导致一定的精度损失。
比较和应用场景
-
回归方法 更适合实时性要求高且场景相对简单的应用场景,例如一些轻量级的移动端应用。
-
热力图方法 则适合需要高精度关键点检测的场景,尤其是在复杂的背景和遮挡情况下,常用于人体姿态估计、面部特征点检测等任务。
两种方法各有优劣,实际应用中选择哪种方法取决于任务的需求和模型的计算能力。
六,YOLO-KP
YOLO-KP 是一种基于 YOLO(You Only Look Once)模型改进的关键点检测方法,它结合了目标检测和关键点检测的优势。YOLO 模型以其高效的单阶段目标检测能力著称,而 YOLO-KP 则在此基础上扩展了关键点检测功能。
YOLO-KP 的核心思想是将关键点检测任务整合到 YOLO 的目标检测框架中,使得模型能够同时输出目标的边界框和对应的关键点位置。
1)网络架构
YOLO-KP 的网络架构与 YOLO 的基本框架类似,采用了单阶段检测的方式。其主要结构包括:
-
Backbone 网络:用于提取图像的特征。YOLO-KP 可以使用经典的 YOLOv3、YOLOv4、YOLOv5 或 YOLOv8 等版本作为其骨干网络来提取特征。
-
Neck 部分:包括特征金字塔网络(FPN)或路径聚合网络(PANet),用来融合多层次的特征,提升小目标和多尺度检测的能力。
-
Head 部分:这是 YOLO-KP 与传统 YOLO 的主要区别之一。除了传统的边界框预测,YOLO-KP 的 Head 部分还会输出关键点的位置。
2)输出设计
YOLO-KP 的每个预测单元(通常是网格单元)会同时输出以下信息:
-
类别置信度(Class Confidence):表示该单元中存在某一类别目标的概率。
-
边界框坐标(Bounding Box Coordinates):用于定位目标的边界框。
-
关键点坐标(Keypoint Coordinates):YOLO-KP 对每个目标预测出固定数量的关键点,每个关键点的位置以相对于网格单元的偏移量的形式输出。
这些信息通常被编码为一个向量进行输出,例如对于检测类别为 C,预测 N 个关键点的情况,每个网格单元的输出维度为:(C+5+2N)。其中,5 代表4个边界框坐标和1个置信度,2N代表N个关键点的x、y坐标。
3)损失函数
YOLO-KP 设计了专门的损失函数来同时优化目标检测和关键点检测。损失函数通常包括以下部分:
-
边界框回归损失:用于优化预测的边界框与真实框之间的差异(通常使用 IoU 损失或 L2 损失)。
-
类别分类损失:用于优化目标类别的预测准确性(使用交叉熵损失)。
-
关键点回归损失:用于优化预测关键点与真实关键点之间的距离(通常使用 L2 损失或 MSE)。
这种设计能够让模型在训练过程中同时学习如何精确定位目标的边界框和关键点。
4)预测和后处理
在推理阶段,YOLO-KP 会对每个检测框进行后处理,包括:
-
非极大值抑制(NMS):消除重叠的检测框,只保留最优的检测结果。
-
关键点提取:从每个检测框的输出中提取关键点坐标,进一步应用插值或其他方法提高精度。
优势
-
高效性:YOLO-KP 继承了 YOLO 模型的高效性,能够在单次前向传播中完成目标检测和关键点检测,适合实时应用。
-
联合优化:通过联合训练目标检测和关键点检测任务,模型能够利用两者的互补信息,提高整体检测精度。
-
适应性强:YOLO-KP 可以适应不同数量的关键点检测任务,如人体姿态估计(多关键点)或物体特征点检测(少关键点)。
应用场景
YOLO-KP 适用于需要同时进行目标检测和关键点检测的任务,如:
-
人体姿态估计: 在检测人的同时输出关键点来估计姿态。
-
物体特征点检测:如在自动驾驶中检测车辆并定位其关键部位。
YOLO-KP 的创新在于它将传统的目标检测与关键点检测有机结合,使得模型在保证高效性的同时能够提供丰富的输出信息。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









