







本文首发于微信公众号:人工智能与图像处理
一,YOLOV7
1,概述:
YOLO代表“You Only Look Once”,它是当下流行的实时对象检测算法。最初的YOLO物体检测器于2016年首次发布。它由Joseph Redmon、Ali Farhadi和Santosh Divvala创建。在发布时,这种架构比其他物体检测器快得多,并成为实时计算机视觉应用的最新技术。
YOLO的官方版本只有YOLO v1、YOLO v2、YOLO v3、YOLO v4和最新版的YOLO v7。每个版本的YOLO都比上一个版本提高了性能和效率。YOLOv5和YOLOv6都不是官方YOLO系列的一部分。
2022年7月,YOLOv7来临,在v7论文挂出不到半天的时间,YOLOv3和YOLOv4的官网上均挂上了YOLOv7的链接和说明,由此看来大佬们都比较认可这款检测器。
官方版的YOLOv7相同体量下比YOLOv5精度更高,速度快120%(FPS),比 YOLOX 快180%(FPS),比 Dual-Swin-T 快1200%(FPS),比 ConvNext 快550%(FPS),比 SWIN-L快500%(FPS)。在5FPS到160FPS的范围内,无论是速度或是精度,YOLOv7都超过了目前已知的检测器,并且在GPU V100上进行测试, 精度为56.8% AP的模型可达到30 FPS(batch=1)以上的检测速率,与此同时,这是目前唯一一款在如此高精度下仍能超过30FPS的检测器。
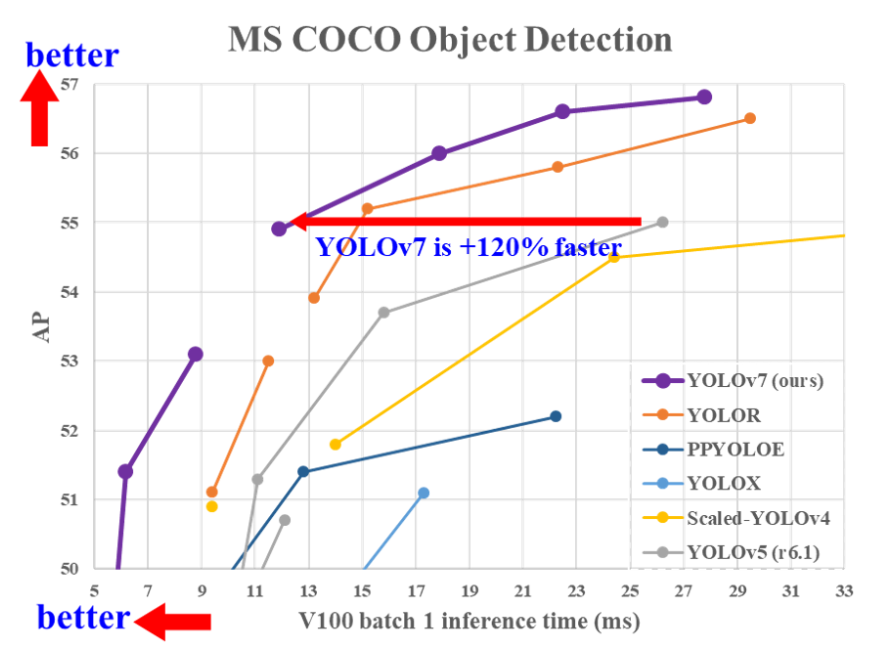
总的来说,YOLOv7提供了更快更强的网络架构,提供了更有效的特征集成方法、更准确的目标检测性能、更鲁棒的损失函数以及更高的标签分配和模型训练效率。
2,YOLOV7主要的贡献在于:
-
模型重参数化。YOLOV7将模型重参数化引入到网络架构中,重参数化这一思想最早出现于REPVGG中。
-
标签分配策略。YOLOV7的标签分配策略采用的是YOLOV5的跨网格搜索,以及YOLOX的匹配策略。
-
ELAN高效网络架构。YOLOV7中提出的一个新的网络架构,以高效为主。
-
带辅助头的训练。YOLOV7提出了辅助头的一个训练方法,主要目的是通过增加训练成本,提升精度,同时不影响推理的时间,因为辅助头只会出现在训练过程中。
3,YOLOV7 网络结构
3.1,整体结构
YOLOV7将整个模型分成了三个大块。具体结构和YOLOV5类似,主要就是对网络内部组件进行了更换,比如辅助训练头、标签分配思想等,但是基本上整体结构还是保持了YOLO的那一套处理。
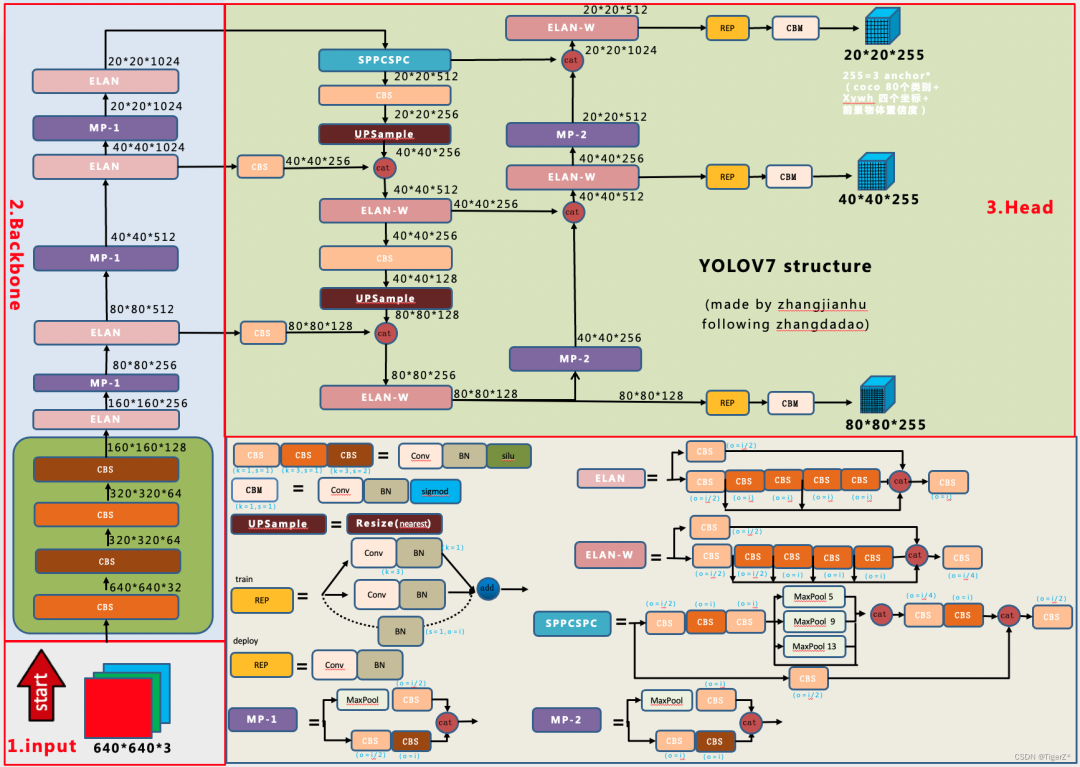
YOLOV7首先将输入的图片 resize 为 640x640 大小,并输入到 backbone 网络中,然后经 head 层网络输出三层不同 size 大小的 feature map,经过 Rep 和 conv输出预测结果,这里以 coco 为例子,输出为 80 个类别,然后每个输出(x ,y, w, h, o) 即坐标位置和前后背景,3 是指的 anchor 数量,因此每一层的输出为 (80+5)x3 = 255再乘上 feature map 的大小就是最终的输出了。
3.2,backbone
YOLOV7 的 backbone 如下图所示
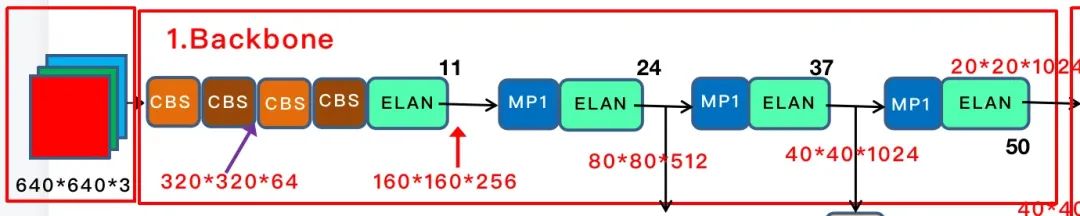
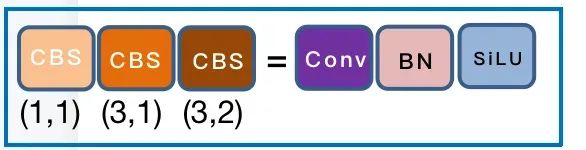
总共有 50 层, 上图用黑色数字把关键层数标示出来了。首先是经过 4 层卷积层,如下图,CBS 主要是 Conv + BN + SiLU 构成,在图中用不同的颜色表示不同的 size 和 stride, 如 (3, 2) 表示卷积核大小为 3 ,步长为 2。在 config 中的配置如图。
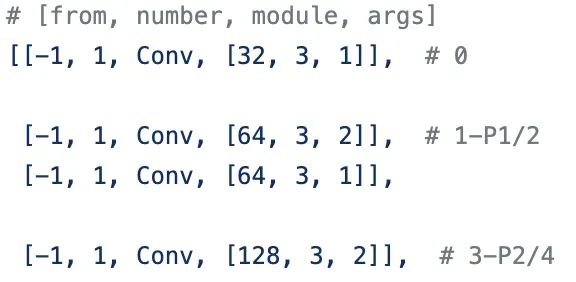
经过 4个 CBS 后,特征图变为 160 * 160 * 128 大小。随后会经过论文中提出的 ELAN 模块,ELAN 由多个 CBS 构成,其输入输出特征大小保持不变,通道数在开始的两个 CBS 会有变化, 后面的几个输入通道都是和输出通道保持一致的,经过最后一个 CBS 输出为需要的通道。
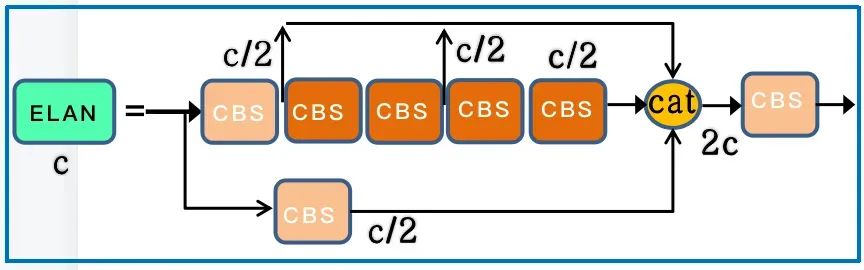

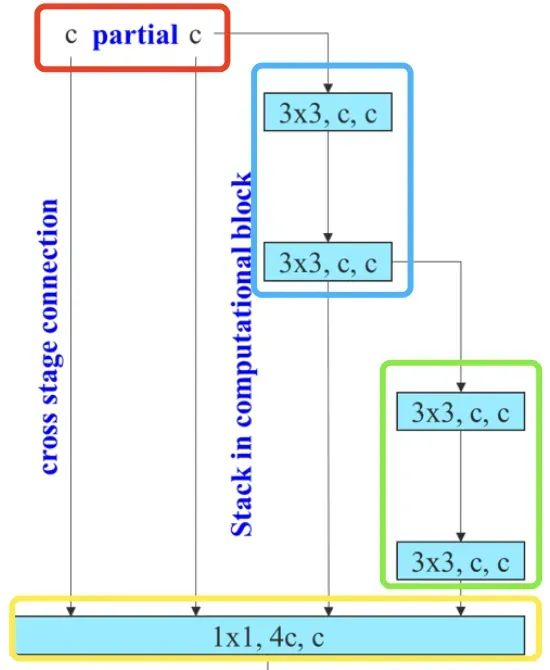
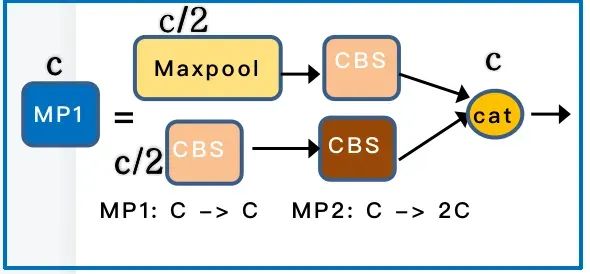
MP 层 主要是分为 Maxpool 和 CBS , 其中 MP1 和 MP2 主要是通道数的比变化。
backbone的基本组件就介绍完了,我们整体来看下 backbone,经过 4 个 CBS 后,接入例如一个 ELAN ,然后后面就是三个 MP + ELAN 的输出,对应的就是 C3/C4/C5 的输出,大小分别为 80 * 80 * 512 , 40 * 40 * 1024, 20 * 20 * 1024。每一个 MP 由 5 层, ELAN 有 8 层, 所以整个 backbone 的层数为 4 + 8 + 13 * 3 = 51 层, 从 0 开始的话,最后一层就是第 50 层。
3.3,head
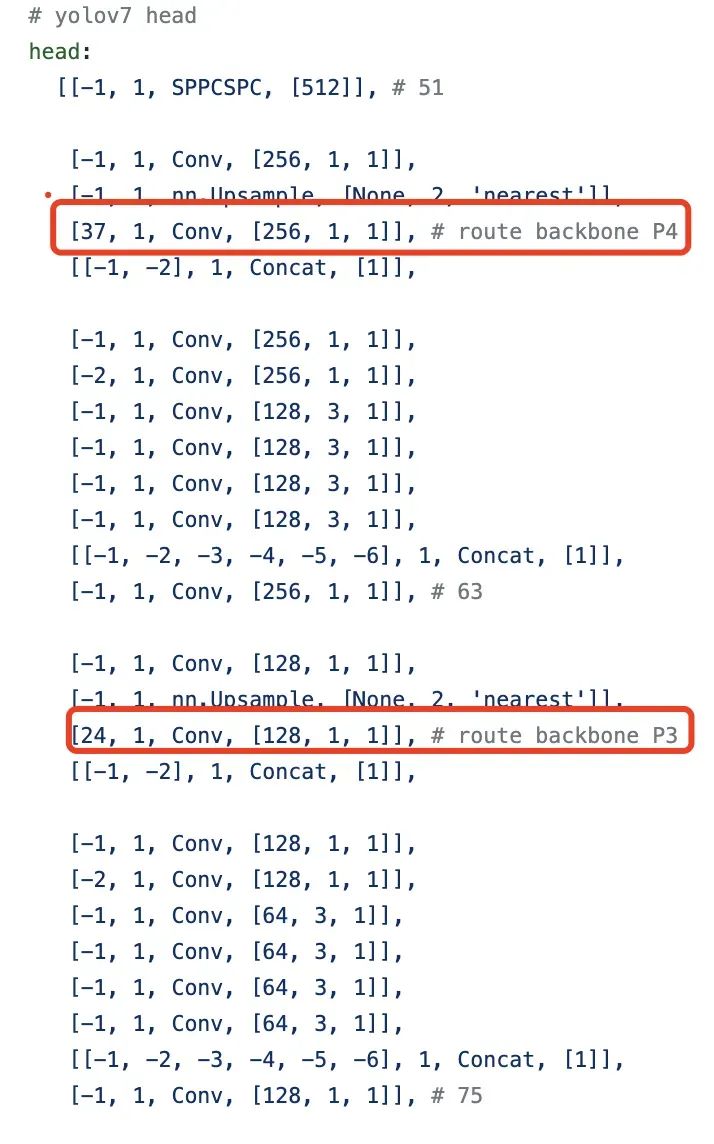
YOLOV7 head 其实就是一个 pafpn的结构,和之前的YOLOV4,YOLOV5 一样。首先,对于 backbone 最后输出的 32 倍降采样特征图 C5,然后经过 SPPCSP,通道数从1024变为512。先按照 top down 和 C4、C3融合,得到 P3、P4 和 P5;再按 bottom-up 去和 P4、P5 做融合。这里基本和 YOLOV5 是一样的,区别在于将 YOLOV5 中的 CSP 模块换成了 ELAN-H 模块, 同时下采样变为了 MP2 层。ELAN-H 模块是我自己命名的,它和 backbone 中的 ELAN 稍微有点区别就是 cat 的数量不同。
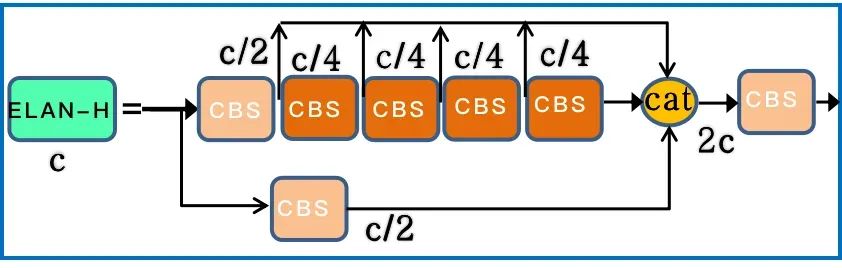
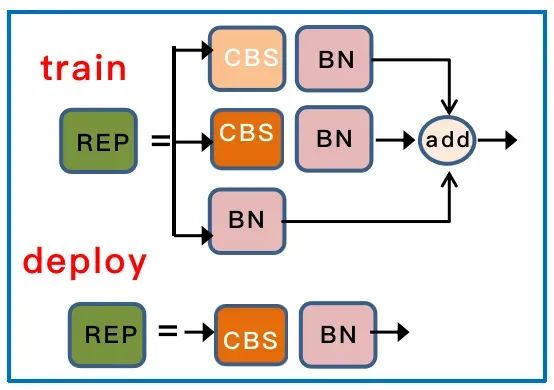
对于 pafpn输出的 P3、P4 和 P5 , 经过 RepConv 调整通道数,最后使用 1x1 卷积去预测 objectness、class 和 bbox 三部分。RepConv 在训练和推理是有一定的区别。训练时有三个分支的相加输出,部署时会将分支的参数重参数化到主分支上。
4,YOLOv7基础版本的区别
YOLOv7基础版本有三种,分别是YOLOv7、YOLOv7-tiny和YOLOv7-W6:
-
YOLOv7是针对普通GPU计算优化的基础模型。
-
YOLOv7-tiny是针对边缘GPU优化的基础模型。计算机视觉模型的后缀“小”意味着它们针对边缘AI和深度学习工作负载进行了优化,并且更轻量级,可以在移动计算设备或分布式边缘服务器和设备上运行ML。该模型对于分布式现实世界的计算机视觉应用程序很重要。与其他版本相比,边缘优化的YOLOv7-tiny使用leaky ReLU作为激活函数,而其他模型使用SiLU作为激活函数。
-
YOLOv7-W6是针对云GPU计算优化的基础模型。此类云图形单元(GPU)是用于运行应用程序以在云中处理大量AI和深度学习工作负载的计算机实例,而无需在本地用户设备上部署GPU。
5,实验对比
5.1,基础比较
选择早期版本的YOLO和State-of-the-Art对象检测器YOLOR作为基线。表1显示Yolov7模型和那些用相同设置训练的基线的比较。
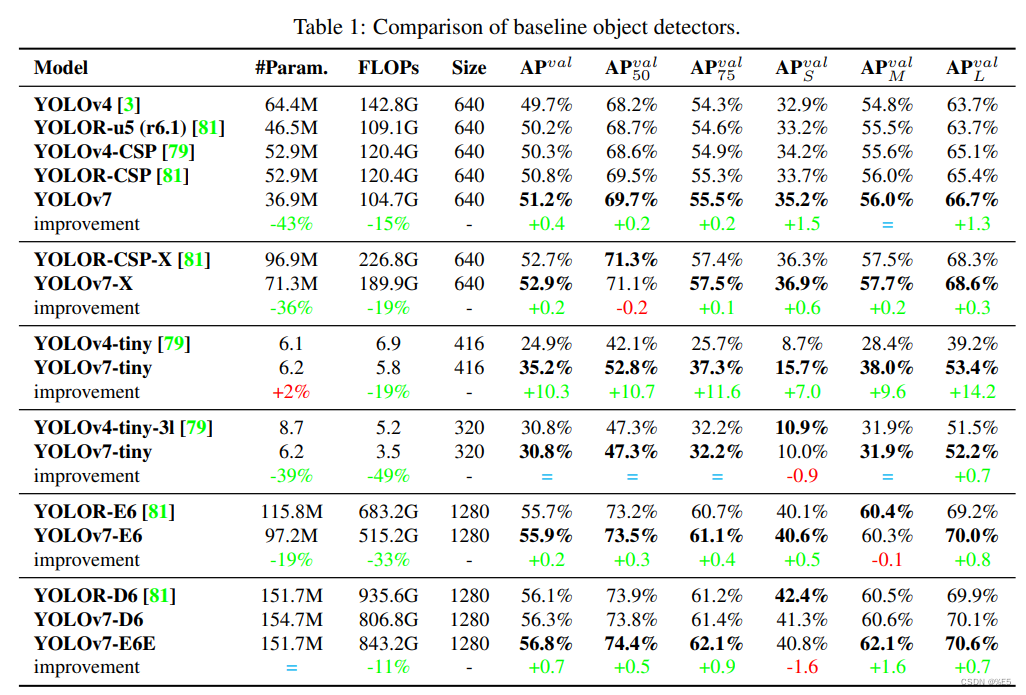
结果表明,与Yolov4相比,Yolov7的参数减少了75%,计算量减少了36%,计算效率提高了1.5%。与现有的Yolor-CSP相比,Yolov7的参数减少了43%,计算量减少了15%,AP提高了0.4%。在Tiny模型的性能方面,与Yolov4-Tiny-31相比,Yolov7Tiny模型的参数数减少了39%,计算量减少了49%,但AP保持不变。在云GPU模型上,我们的模型在减少19%的参数数和33%的计算量的同时,仍然可以有更高的AP。
5.2,与最新技术的比较
Yolov7与现有的通用GPU和移动GPU的目标检测器进行了比较,结果如表2所示。从表2中的结果可知,Yolov7具有最佳的速度-精度综合权衡。将Yolov7-Tiny-Silu与Yolov5-N(R6.1)相比,Yolov7-Tiny-Silu在AP上的速度快127 fps,准确度高10.7%。此外,Yolov7在161 fps的帧率下拥有51.4%的AP,而同样AP的PPYoloe-L只有78 fps的帧率。在参数使用方面,YOLOV7比PPYOLOE-L少41%。将114 fps推理速度的Yolov7-X与99 fps推理速度的Yolov5-L(R6.1)相比,Yolov7-X可以提高3.9%的AP。如果将Yolov7x与相似尺度的Yolov5-x(R6.1)进行比较,Yolov7-x的推断速度要快31 fps。此外,在参数和计算量方面,Yolov7-x比Yolov5-x(R6.1)减少了22%的参数和8%的计算量,但AP提高了2.2%。
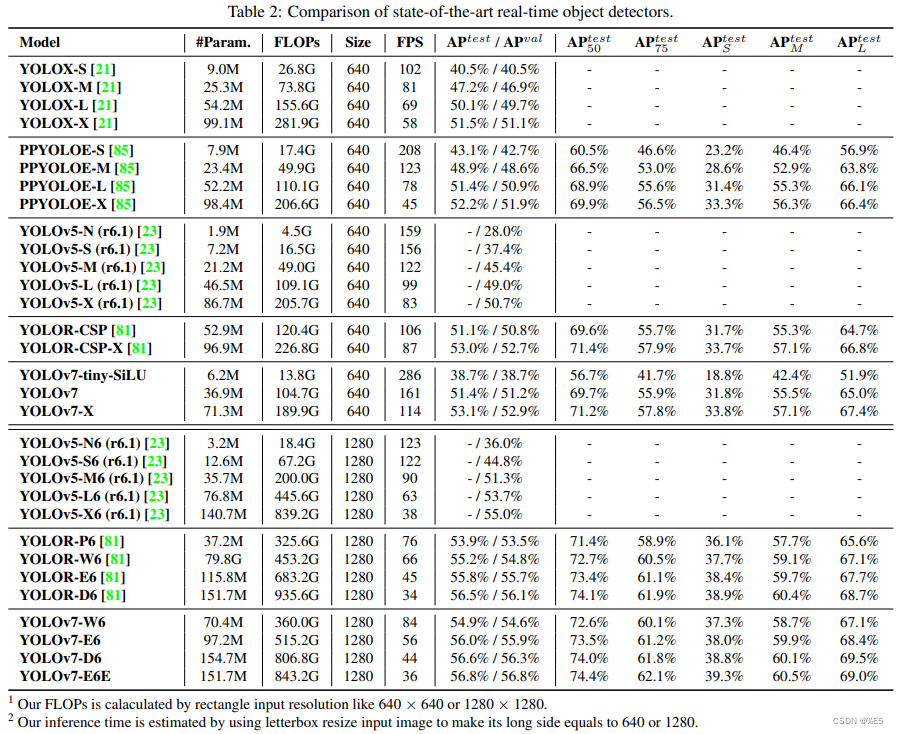
使用1280的输入分辨率来比较Yolov7和Yolor,Yolov7-W6的推断速度比Yolor-P6快8 fps,检测率也提高了1%AP。与YOLOV7-E6和YOLOV5-X6(R6.1)相比,前者的AP增益为0.9%,参数减少45%,计算量减少63%,推理速度提高47%。Yolov7-D6的推理速度接近于Yolor-E6,但AP提高了0.8%。Yolov7-E6E的推理速度与Yolor-D6接近,但AP提高了0.3%。
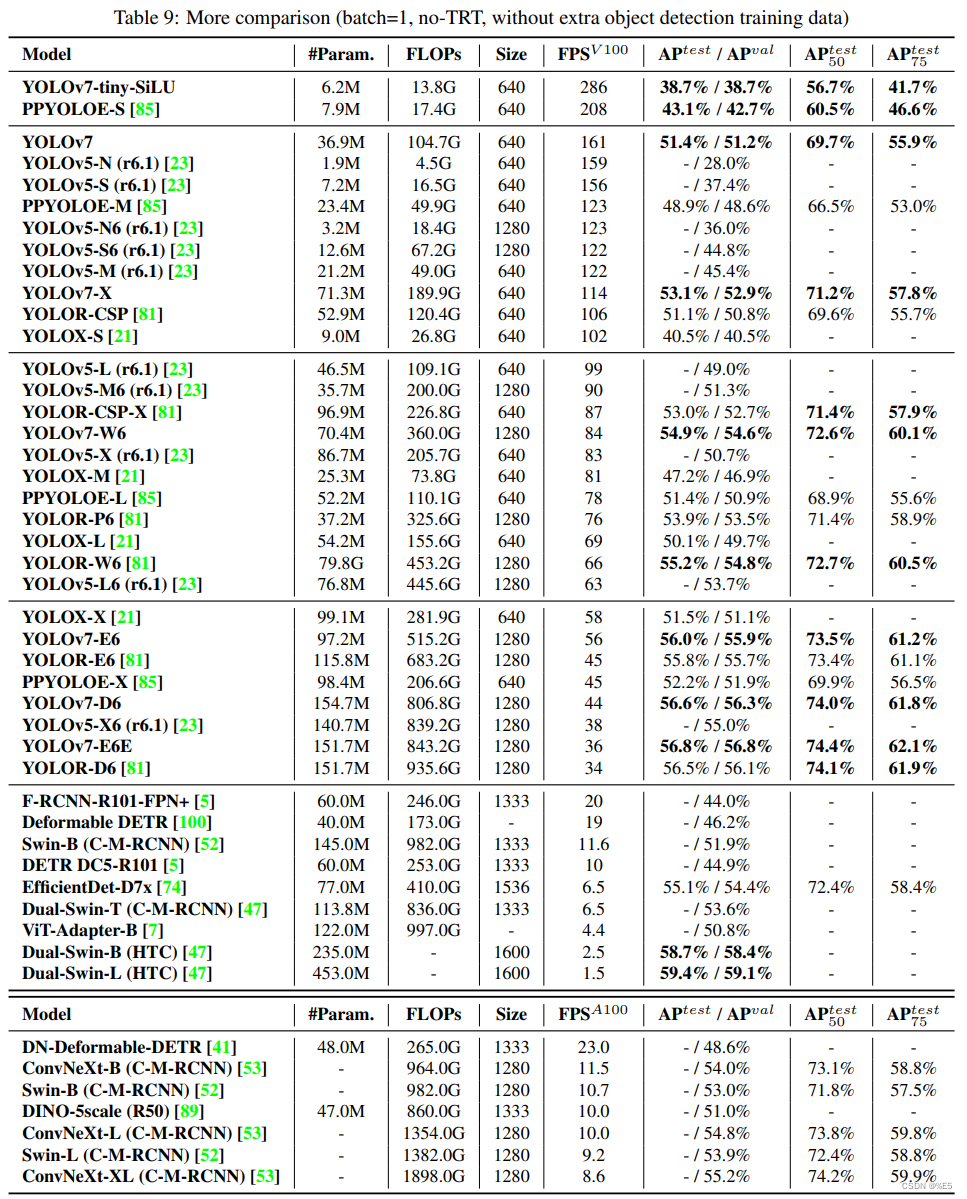
5.3,更多比较
Yolov7在5 fps到160 fps范围内的速度和精度都超过了所有已知的物体检测器,在GPU V100上的30 fps或更高的所有已知实时物体检测器中,它具有最高的精度56.8%AP Test-Dev/56.8%AP Min-Val。YOLOV7-E6目标检测器(56 fps V100,55.9%AP)在速度和精度上优于基于转换的检测器SWIN-L级联掩模R-CNN(9.2 fps A100,53.9%AP)509%和2%;基于卷积的检测器Convnext-XL级联掩模R-CNN(8.6 fps A100,55.2%AP)551%和0.7%AP;YOLOV7在速度和精度上优于:YOLOR、YOLOX、Scaled-YOLOV4、YOLOV5、DETR、DETR、DINO-5Scale-R50、VIT-Adapter-B和许多其他目标检测器。此外,我们只在MS Coco数据集上从头开始训练Yolov7,而不使用任何其他数据集或预先训练的权值。
在COCO数据集上,Yolov7-E6E实时模型的最大精度(56.8%AP)比目前最精确的Meituan/Yolov6-S模型(43.1%AP)高出+13.7%AP。在COCO DataSet和Batch=32的V100 GPU上,我们的Yolov7-Tini(35.2%AP,0.4ms)模型比Meituan/Yolov6-n(35.0%AP,0.5ms)快+25%,高+0.2%AP。
6,检测效果

二,相关地址:
论文地址:https://arxiv.org/abs/2207.02696
代码地址:https://github.com/WongKinYiu/yolov7
三,参考文章:
https://zhuanlan.zhihu.com/p/540068099
https://fuxi.163.com/database/146
https://blog.csdn.net/u012863603/article/details/126118799
https://blog.51cto.com/u_10913151/5487685
https://blog.csdn.net/qq_41048761/article/details/130512101

















 4429
4429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









