







问题描述及算法
考虑下图所示的分布式机器学习架构.

我们用
t
t
t表示迭代训练的次数,
N
N
N代表节点的数量,工作节点
i
i
i计算得到的梯度向量为
g
t
(
i
)
\mathbf{g}^{(i)}_t
gt(i),输入的样本为
z
t
(
i
)
\mathbf{z}^{(i)}_t
zt(i).
为了能够进一步实现压缩,在训练过程中中央服务器并不保存模型,每个工作节点都保存一个模型副本,计算得到梯度后由中央服务器进行聚合,将得到的梯度也进行量化后发送到每个工作节点,由工作节点本地进行模型更新.
工作节点在进行梯度上传的时候对梯度向量进行量化,将其量化为一个三元向量(向量中每个元素的值为1或-1或0),其量化的具体公式为:
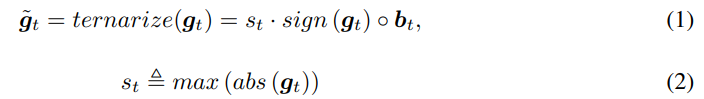
其中向量
b
t
\mathbf{b}_t
bt的计算公式为:
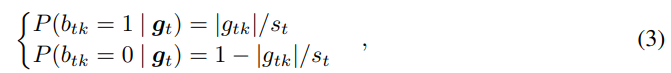
考虑到每个工作节点计算出来的值
s
t
s_t
st都是不同的,因此当在服务端进行聚合后可能并不能实现很好的压缩传输,因此我们进行参数共享
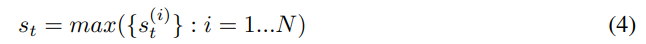
通过这样处理后,在服务端聚合后的梯度向量中最多只有
2
N
+
1
2N+1
2N+1个值,因此每个梯度可以量化为
l
o
g
(
2
N
+
1
)
log\ (2N+1)
log (2N+1).具体算法过程如下所示

为了分析该量化算法的收敛性,我们使用在线学习系统框架,定义
Q
(
z
,
w
)
Q(z,w)
Q(z,w)为损失函数,其中的
w
w
w为模型参数,
z
z
z为接受到的样本.在广义在线梯度算法中,梯度的更新过程为
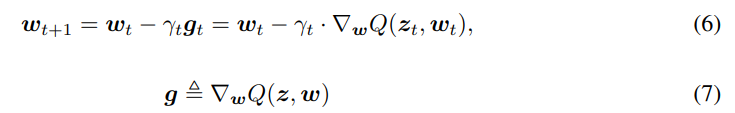
经过量化压缩后,更新梯度的过程修改为:
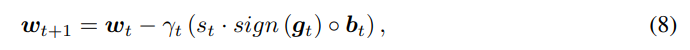
我们的量化过程是无偏的,即:
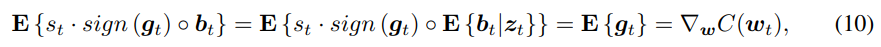
为了分析该量化算法的收敛性,我们首先介绍在基本梯度更新过程中的收敛性证明.

同时定义当前计算得到的参数与最优参数的距离

除了以上两个假设外,在线学习算法还假设了梯度平方期望值的上界,即:
E
{
∣
∣
g
∣
∣
2
}
≤
A
+
B
∣
∣
w
−
w
∗
∣
∣
\mathbf{E}\{||\mathbf{g}||^2\}\le A+B||w-w^*||
E{∣∣g∣∣2}≤A+B∣∣w−w∗∣∣
由已有的关于在线学习算法的介绍中可以得到以下定理:
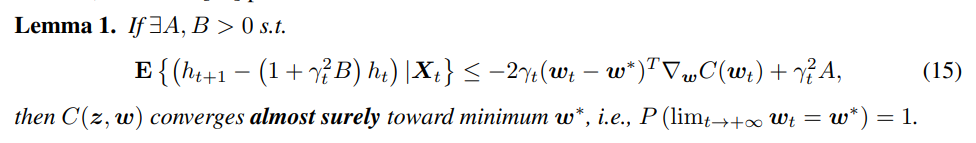
以上是在线学习算法收敛性的相关定理和假设,接下来利用这些来分析量化算法的收敛性,由于我们对梯度做了量化,因此除了上述的假设1和2外,我们对梯度的平方的上限做了更强的假设,即
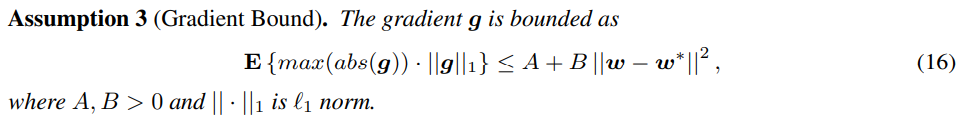
根据
h
t
h_t
ht的定义和量化后梯度的更新过程,我们可以得到
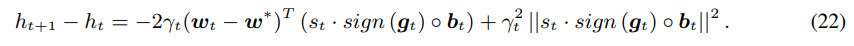
对上式进行期望值求解,即
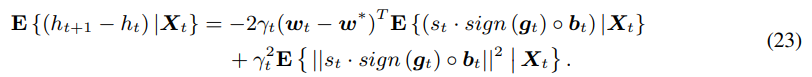
由于我们已经介绍过了量化算法是无偏的,所以上式可以修改为
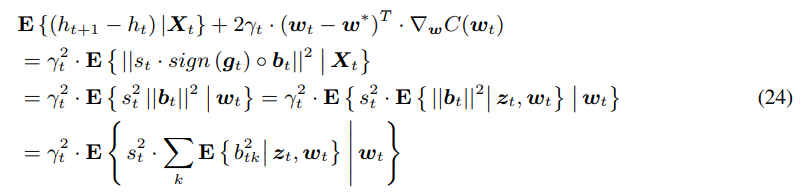
根据之前对于向量
b
\mathbf{b}
b的定义,可以得到
∑
k
E
{
b
t
k
2
}
=
∣
∣
g
∣
∣
1
s
t
\sum_k \textbf{E}\{b_{tk}^2\}=\frac{||\mathbf{g}||_1}{s_t}
∑kE{btk2}=st∣∣g∣∣1,因此上式可以修改为
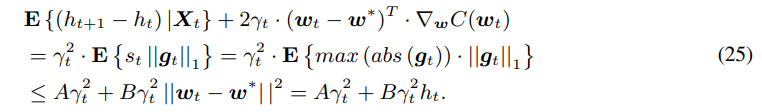
因此得到了关于定理1的不等式
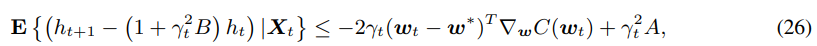
故该量化算法会收敛.
在量化算法的收敛证明中,由于
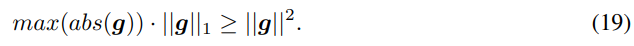
因此我们的假设3的假设性更强,为了解决这个问题,我们提出了分层量化和梯度裁剪的方法.
分层量化是每一层网络的梯度范围都不同,因此不采取全部参数的最大值,而是对每一层的参数都利用公式1进行量化.
梯度裁剪则是对梯度的最大值进行限制
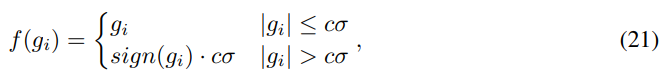















 3471
3471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









