







Very Deep Convolutional Networks for Large-Scale Image Recognition
文章目录
参考
- VGGNet 阅读理解 - Very Deep Convolutional Networks for Large-Scale Image Recognition
- VGGNet介绍
- VGG网络结构和代码详解
Introduction
- 作者对网络的深度进行了一个感性的判断(认为越深越好)。因此,他们探索了卷积神经网络的深度和其性能之间的关系,通过反复的堆叠3*3的小型卷积核和2*2的最大池化层,成功的构建了16~19层深的卷积神经网络。
ConvNet Configurations
Architecture
- 网络的输入是固定的大小(input=224*224)
- 预处理时,对训练集减去RGB均值
- 同时选用3*3的卷积核(关于卷积核的大小后面会有讨论)stride=1,padding=1
- 使用1*1卷积对输入的层数进行线性转换(就是channel数变化)
- 使用2*2的MaxPooling,stride=2
- 卷积完毕后接三个FC(全链接层),最后由SoftMax输出分类结果
- 且所有的隐藏层后面都跟一个ReLU激活层
Configurations
- 下面为具体的网络结构,其中,层数的计算是计算conv(卷积)层+FC(全链接)层的和(如:A=8conv+3FC=11 layers)
- VGGNet的网络结构如下图所示。VGGNet包含很多级别的网络,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。
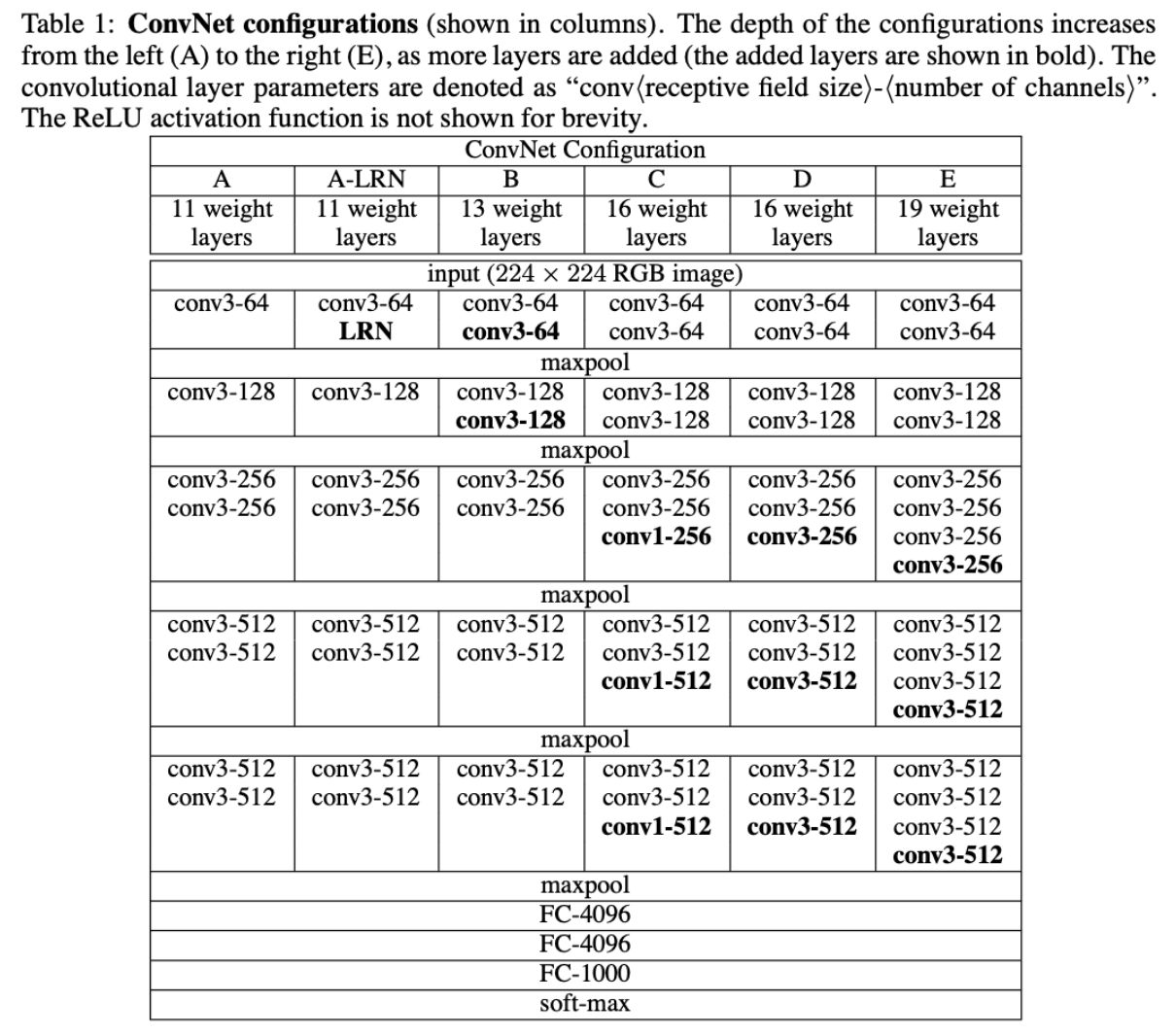
- 各个网络的参数量如下所示:

Discussion
- 首先讨论了大小卷积核的优劣
- 一般来说对于一个7*7的卷积核来说用三个3x3的卷积核可以获得与之相当的感受野,计算公式如下

- 且一般来说多个3*3卷积可以使得决策函数的判断能力提升,同时参数量减少参数量(文中提到,使用3*3卷积的参数量为3(3C)2=27C2,而7*7卷积的参数量为(7C)2=49C2,其中C为通道数)
- 1*1的卷积也是很有效的,但是没有3*3的卷积效果好,因为3*3的网络可以学习到更大的空间特征
- 一般来说对于一个7*7的卷积核来说用三个3x3的卷积核可以获得与之相当的感受野,计算公式如下
Classification Framework
Training(参考VGGNet 阅读理解,原文位于第4页3.1部分)
-
优化方法:带动量(momentum)的小批量梯度下降
-
batch size:256
-
learning rate:0.01
-
和AlexNet一样,当val-acc 不下降则学习率缩小十倍,训练过程缩小了三次
-
momentum:0.9
-
weight decay(L2惩罚乘子):5×10−4
-
dropout rate(前两个全连接层):0.5
-
目标函数:多项式逻辑斯特回归(SoftMax)
-
迭代次数:37万次iteration(74 epochs)后,停止训练
-
模型参数量是AlexNet的三倍多且层数深,但收敛比AlexNet块,原因如下:
- 正则化:dropout和小卷积核的使用。关于dropout,我记得AlexNet有写道:前两个全连接层用到了dropout,若没有dropout模型必然会过拟合, 但是有dropout后,收敛大约需要原本两倍的 iteration 次数。我对 dropout 的理解是模型 ensemble,每次iteration对原网络dropout 一些神经元后的模型可视为一个单独的模型,最后test时则是ensemble的模型,效果必然好于单模型。参数越多越容易过拟合,比方全连接层比卷积层要容易过拟合,全连接层因为参数量大,好比一个多元高次函数,而卷积层好比简单的函数,多元高次的函数肯定在捕捉细节特征上会比简单函数好,但代价就是训练时间更长,需要正则化等方法去平衡。对于收敛更快,我认为主要是小卷积核带来的优势,小卷积核参数少,从训练样本中需要拟合/学习的参数自然少,而且backprop的时候涉及到前面的范围也比较小,因而似乎会收敛快(但我不认为这是 VGG 比 AlexNet 收敛快的根本原因);
- pre-initialisation,相当于预训练。为了防止不好的初始化会导致训练过程中停止学习,作者把A实验的模型的前四个卷积层和三个全连接层的参数拿来作为模型的初始化参数,中间层的初始值从均值为0,方差为0.01的正态分布中采样得到,bias初始化为0,学习率设定和训练A(相当于pre-train)时的一样。虽然作者没有承认pre-initialisation是预训练,但本质上就是。好处主要两点:性能比train-from-scratch有提高,且收敛更。
pytorch实现
import torch.nn as nn
import torch
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
def __init__(self,features, num_classes=1000,init_weights=False):
super(VGG, self).__init__()
# 特征提取部分
self.features = features
# 分类器部分
self.classifier = nn.Sequential(
nn.Linear(512*7*7,4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096,4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096,num_classes)
)
# 初始化权重
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias,0)
def forward(self,x):
x = self.features(x)
x = torch.flatten(x,start_dim=1)
x = self.classifier(x)
return x
'''
由于vgg的网络的卷积核大小和步长都固定,因此cfg只需要指出输出的channels即可,然后再利用in_channels记录上一层的输出即可得到下一层的输入,且由于卷积核大小为3步长为1还有一层padding,故算出来的feature map和上层的一样大(前两维)
以vgg16为例:'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
input:(224,224,3)
conv2d:(224,224,64)
conv2d:(224,224,64)
MaxPool2d:(112,112,64)
conv2d:(112,112,128)
conv2d:(112,112,128)
MaxPool2d:(56,56,128)
conv2d:(56,56,256)
conv2d:(56,56,256)
conv2d:(56,56,256)
MaxPool2d:(28,28,256)
conv2d:(28,28,512)
conv2d:(28,28,512)
conv2d:(28,28,512)
MaxPool2d:(14,14,512)
conv2d:(14,14,512)
conv2d:(14,14,512)
conv2d:(14,14,512)
MaxPool2d:(7,7,512)
#上面为卷积的部分,接下来通过torch.flatten(x,start_dim=1),将其转化成4096x1x1(底层变为一维,shape还是512x7x7)
# 然后是全链接层,中间夹杂Dropout层,用于丢弃部分参数,防止过拟合
# 也有大神对dropout的理解是:对 dropout 的理解是模型 ensemble,每次iteration对原网络dropout 一些神经元后的模型可视为一个单独的模型,最后test时则是ensemble的模型,效果必然好于单模型
Linear(512*7*7,4096)
Linear(4096,4096)
Linear(4096,num_classes)
最后在用SoftMax化成概率即可实现分类了
'''
def make_feature(cfg:list):
layers = []
in_channels = 3
for v in cfg:
if v == "M"
layers += [nn.MaxPool2d(kernel_size=2,stride=2)]
else:
conv2d = nn.Conv2d(in_channels,v,kernel_size=3,padding=1)
layers += [conv2d,nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# kwargs:https://www.jianshu.com/p/0ed914608a2c
def vgg(model_name="vgg16",**kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_feature(cfg),**kwargs)
return model


















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











