







Gridword问题
-
强化学习基础部分的一道例题,题目长这样
-
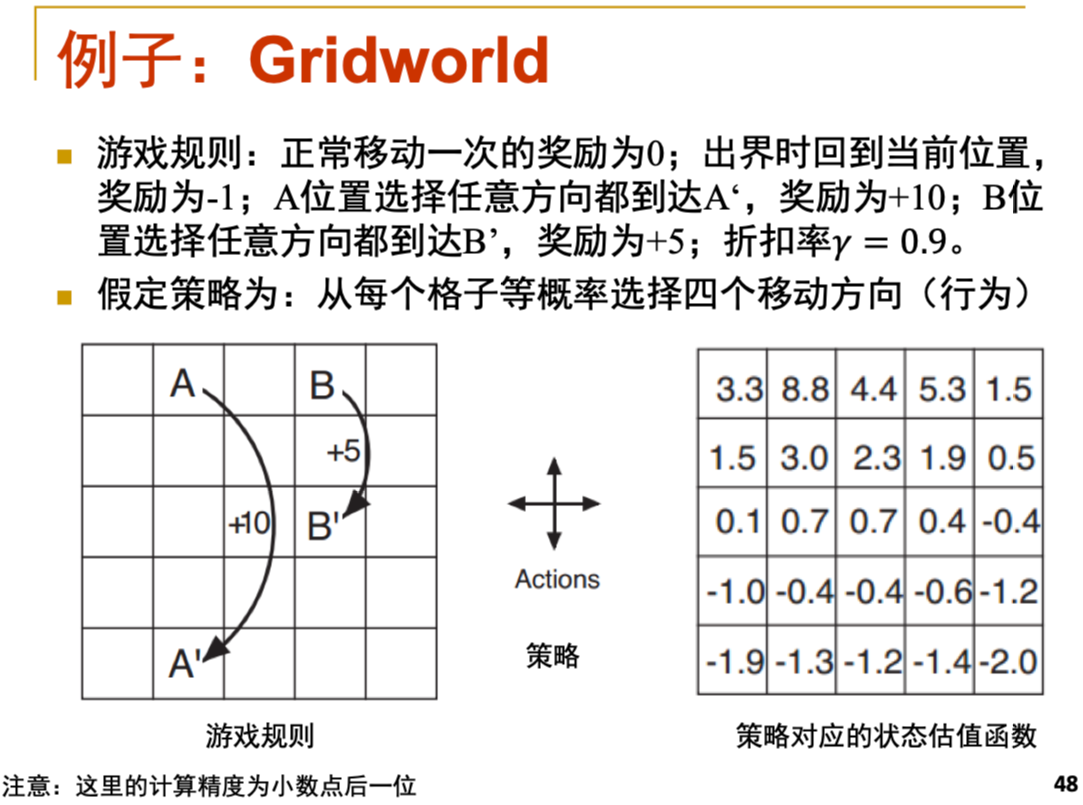
-
根据我们可以抽取题目中的信息建立马尔可夫决策模型:
- reward=0 出界时-1并回到原处,AB任意方向可跳转至A‘B’并得到对应reward
- action就是上下左右四个方向走
-
这是一个没有终止态的马尔可夫决策过程,累计奖励记为:


随机策略

- π ( α ∣ s ) \pi(\alpha|s) π(α∣s)表示在状态s下做action α \alpha α的概率
- 然后用贝尔曼转换状态评估方程,建立与其他状态下的状态的关系
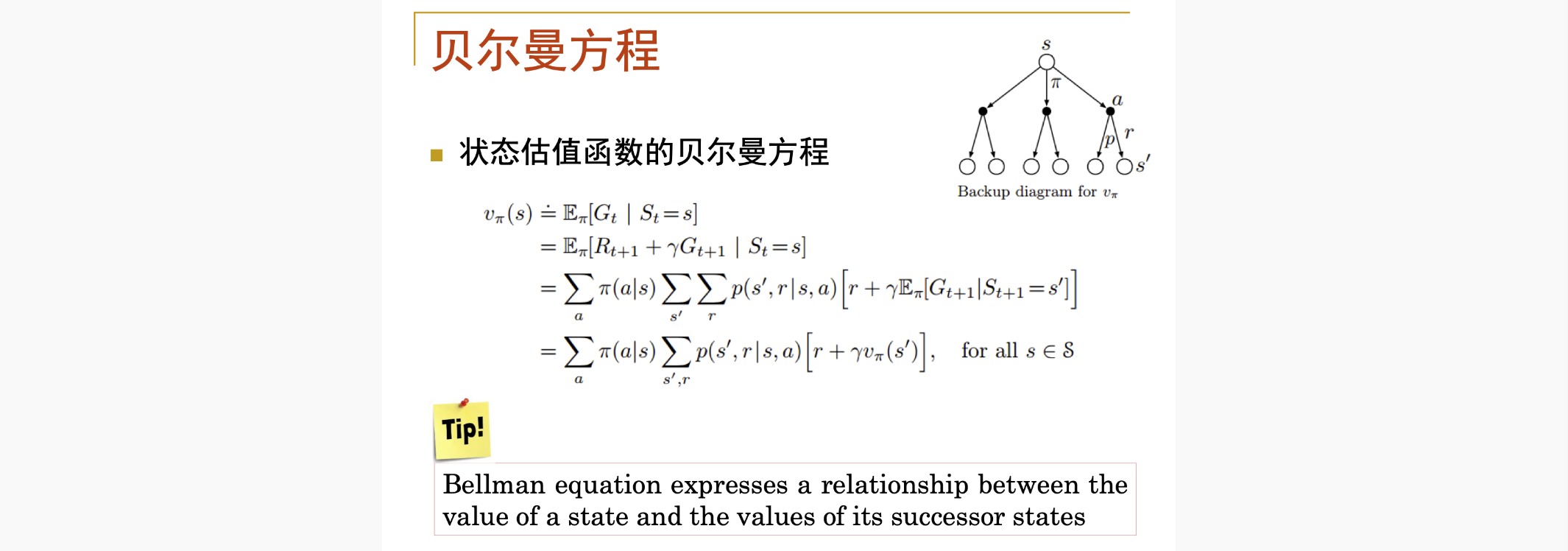
- 贝尔曼方程定义了状态估值函数的依赖关系,
- 给定策略下,每个状态的估值视为一个变量,
- 所有状态(假如有n个)的估值根据贝尔曼方程形成了一个具有n个方程和n个变量的线性方程组
- 求解该方程组即可得到该策略下每个状态的估值
- 在实现中
π
(
α
∣
s
)
=
1
4
\pi(\alpha|s)=\frac{1}{4}
π(α∣s)=41,原因是随机策略四个action随机取,
∑
s
∈
S
∑
r
∈
R
p
(
s
′
,
r
∣
s
,
α
)
=
1
\sum_{s \in S} \sum_{r \in R} p(s',r|s,\alpha)=1
∑s∈S∑r∈Rp(s′,r∣s,α)=1,
r
和
γ
r和\gamma
r和γ已知由此可以列出贝尔曼方程
- 代码实现为randomPolicyCalculate,这里有个点需要注意的是,状态转换是随着action而出现的,换句话说,一个点(普通)的状态只会转换为上下左右四个方向的状态

最优策略
- optimalPolicyCalculate是最优策略:

代码实现
import random
# import pprint
class Gridworld:
def __init__(self, width, rewards, links, gamma) -> None:
self.grid = [[random.random() * (wi + 1) for wi in range(width)]
for w in range(width)]
self.width = width
self.rewards = rewards
for key, value in self.rewards.items():
assert len(value) is width, "width error!"
self.jumpPoints = links.keys()
self.links = links
self.gamma = gamma
def randomPolicyCalculate(self):
for i in range(self.width):
for j in range(self.width):
re = self.rewards["L"][i][j] + self.rewards["U"][i][
j] + self.rewards["R"][i][j] + self.rewards["D"][i][j]
# 跳跃边
if (i, j) in self.jumpPoints:
toPoint = self.links[(i, j)]
self.grid[i][j] = (
re + self.gamma *
(4 * self.grid[toPoint[0]][toPoint[1]])) / 4
# 四个角
elif i == 0 and j == 0:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i + 1][j] + self.grid[i][j + 1] +
2 * self.grid[i][j])) / 4
elif i == 0 and j == self.width - 1:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i + 1][j] + self.grid[i][j - 1] +
2 * self.grid[i][j])) / 4
elif i == self.width - 1 and j == 0:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i - 1][j] + self.grid[i][j + 1] +
2 * self.grid[i][j])) / 4
elif i == self.width - 1 and j == self.width - 1:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i - 1][j] + self.grid[i][j - 1] +
2 * self.grid[i][j])) / 4
# 四条边
elif i == 0:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i + 1][j] + self.grid[i][j - 1] +
self.grid[i][j + 1] + self.grid[i][j])) / 4
elif i == self.width - 1:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i - 1][j] + self.grid[i][j - 1] +
self.grid[i][j + 1] + self.grid[i][j])) / 4
elif j == 0:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i - 1][j] + self.grid[i + 1][j] +
self.grid[i][j + 1] + self.grid[i][j])) / 4
elif j == self.width - 1:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i - 1][j] + self.grid[i + 1][j] +
self.grid[i][j - 1] + self.grid[i][j])) / 4
# 内部点
else:
self.grid[i][j] = (
re + self.gamma *
(self.grid[i - 1][j] + self.grid[i + 1][j] +
self.grid[i][j - 1] + self.grid[i][j + 1])) / 4
def optimalPolicyCalculate(self):
for i in range(self.width):
for j in range(self.width):
re = self.rewards["L"][i][j] + self.rewards["U"][i][
j] + self.rewards["R"][i][j] + self.rewards["D"][i][j]
# 跳跃边
if (i, j) in self.jumpPoints:
# 四边一样,因此不用改
toPoint = self.links[(i, j)]
self.grid[i][j] = (
re + self.gamma *
(4 * self.grid[toPoint[0]][toPoint[1]])) / 4
# 四个角
elif i == 0 and j == 0:
self.grid[i][j] = max(
self.rewards["L"][i][j] + self.gamma * self.grid[i][j],
self.rewards["U"][i][j] + self.gamma * self.grid[i][j],
self.rewards["R"][i][j] +
self.gamma * self.grid[i][j + 1],
self.rewards["D"][i][j] +
self.gamma * self.grid[i + 1][j],
)
elif i == 0 and j == self.width - 1:
self.grid[i][j] = max(
self.rewards["L"][i][j] +
self.gamma * self.grid[i][j - 1],
self.rewards["U"][i][j] + self.gamma * self.grid[i][j],
self.rewards["R"][i][j] + self.gamma * self.grid[i][j],
self.rewards["D"][i][j] +
self.gamma * self.grid[i + 1][j],
)
elif i == self.width - 1 and j == 0:
self.grid[i][j] = max(
self.rewards["L"][i][j] + self.gamma * self.grid[i][j],
self.rewards["U"][i][j] +
self.gamma * self.grid[i - 1][j],
self.rewards["R"][i][j] +
self.gamma * self.grid[i][j + 1],
self.rewards["D"][i][j] + self.gamma * self.grid[i][j],
)
elif i == self.width - 1 and j == self.width - 1:
self.grid[i][j] = max(
self.rewards["L"][i][j] +
self.gamma * self.grid[i][j - 1],
self.rewards["U"][i][j] +
self.gamma * self.grid[i - 1][j],
self.rewards["R"][i][j] + self.gamma * self.grid[i][j],
self.rewards["D"][i][j] + self.gamma * self.grid[i][j],
)
# 四条边
elif i == 0:
self.grid[i][j] = max(
self.rewards["L"][i][j] +
self.gamma * self.grid[i][j - 1],
self.rewards["U"][i][j] + self.gamma * self.grid[i][j],
self.rewards["R"][i][j] +
self.gamma * self.grid[i][j + 1],
self.rewards["D"][i][j] +
self.gamma * self.grid[i + 1][j],
)
elif i == self.width - 1:
self.grid[i][j] = max(
self.rewards["L"][i][j] +
self.gamma * self.grid[i][j - 1],
self.rewards["U"][i][j] +
self.gamma * self.grid[i - 1][j],
self.rewards["R"][i][j] +
self.gamma * self.grid[i][j + 1],
self.rewards["D"][i][j] + self.gamma * self.grid[i][j],
)
elif j == 0:
self.grid[i][j] = max(
self.rewards["L"][i][j] + self.gamma * self.grid[i][j],
self.rewards["U"][i][j] +
self.gamma * self.grid[i - 1][j],
self.rewards["R"][i][j] +
self.gamma * self.grid[i][j + 1],
self.rewards["D"][i][j] +
self.gamma * self.grid[i + 1][j],
)
elif j == self.width - 1:
self.grid[i][j] = max(
self.rewards["L"][i][j] +
self.gamma * self.grid[i][j - 1],
self.rewards["U"][i][j] +
self.gamma * self.grid[i - 1][j],
self.rewards["R"][i][j] + self.gamma * self.grid[i][j],
self.rewards["D"][i][j] +
self.gamma * self.grid[i - 1][j],
)
# 内部点
else:
self.grid[i][j] = max(
self.rewards["L"][i][j] +
self.gamma * self.grid[i][j - 1],
self.rewards["U"][i][j] +
self.gamma * self.grid[i - 1][j],
self.rewards["R"][i][j] +
self.gamma * self.grid[i][j + 1],
self.rewards["D"][i][j] +
self.gamma * self.grid[i - 1][j],
)
def show(self):
# import pprint
# pprint.pprint(self.grid)
for index in range(self.width):
print(self.grid[index])
# print(self.grid)
# for key, value in self.rewards.items():
# print(key)
# pprint.pprint(value)
# pprint.pprint('key={}\nvalue={}'.format(key, value))
if __name__ == '__main__':
# 四个方向的reward
rewardL = [[-1, 10, 0, 5, 0], [-1, 0, 0, 0, 0], [-1, 0, 0, 0, 0],
[-1, 0, 0, 0, 0], [-1, 0, 0, 0, 0]]
rewardU = [[-1, 10, -1, 5, -1], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0],
[0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]
rewardR = [[0, 10, 0, 5, -1], [0, 0, 0, 0, -1], [0, 0, 0, 0, -1],
[0, 0, 0, 0, -1], [0, 0, 0, 0, -1]]
rewardD = [[0, 10, 0, 5, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0],
[0, 0, 0, 0, 0], [-1, -1, -1, -1, -1]]
rewards = {"L": rewardL, "U": rewardU, "R": rewardR, "D": rewardD}
links = {(0, 1): (4, 1), (0, 3): (2, 3)}
g = Gridworld(width=5, rewards=rewards, links=links, gamma=0.9)
# before train
g.show()
# g.calculate()
for index in range(10000):
g.randomPolicyCalculate()
# g.optimalPolicyCalculate()
print("after randomPolicyCalculate train")
g.show()
for index in range(10000):
# g.randomPolicyCalculate()
g.optimalPolicyCalculate()
print("after optimalPolicyCalculate train")
g.show()
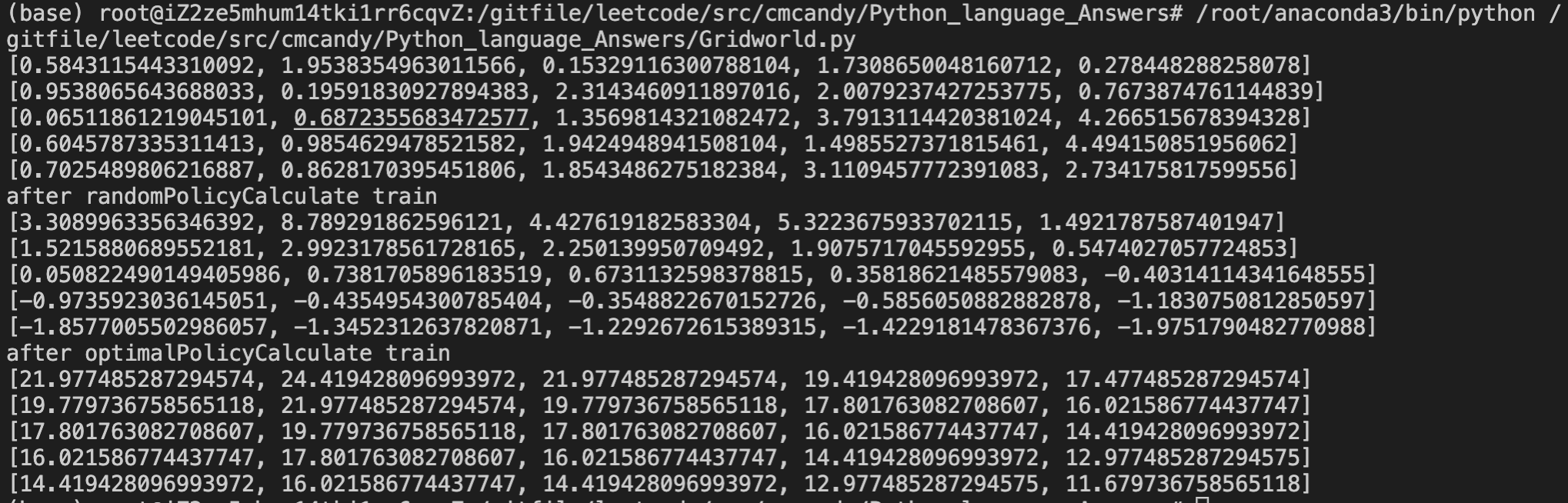
- 两种策略结果如下,对比程序跑出来的,只有精度差别。



















 3972
3972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











