




 本文探讨了Transformer模型性能优异的原因可能并非自我注意力机制,而是结构设计和训练技巧。作者通过借鉴SwinTransformer并进行一系列改进,如改变阶段计算比例、使用大卷积核、减少激活函数和归一化层,成功创建了ConvNeXt模型,其在精度和计算效率上超越了SwinTransformer。实验表明,这些修改对于提升模型性能至关重要。
本文探讨了Transformer模型性能优异的原因可能并非自我注意力机制,而是结构设计和训练技巧。作者通过借鉴SwinTransformer并进行一系列改进,如改变阶段计算比例、使用大卷积核、减少激活函数和归一化层,成功创建了ConvNeXt模型,其在精度和计算效率上超越了SwinTransformer。实验表明,这些修改对于提升模型性能至关重要。
ConvNeXt
文章目录
参考
简记
-
这篇文章作者论证了一个事,就是Transformer性能的优秀可能不是因为self- attention的性能优秀,而是因为模型结构的设计与训练步骤
-
于是作者将模型设计往Swin Transformer的设计靠最终实现用Conv超越了Swin Transformer的性能
-
-
在Conclusions作者希望这项研究报告的新结果将挑战几个广泛持有的观点,并促使人们重新思考卷积在计算机视觉中的重要性,这是我觉得本文比较有意义的地方。
具体改进
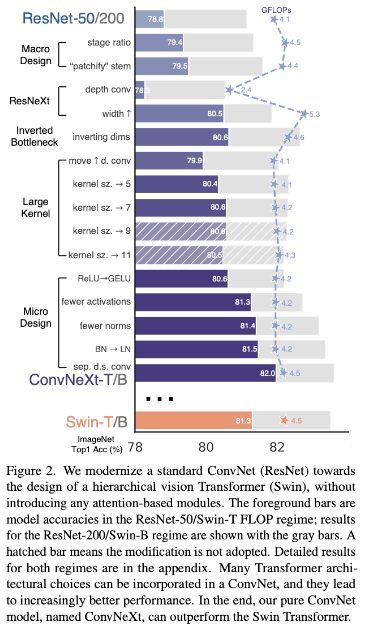
- 作者给了一张路线图,文章也是根据这个讲述的。
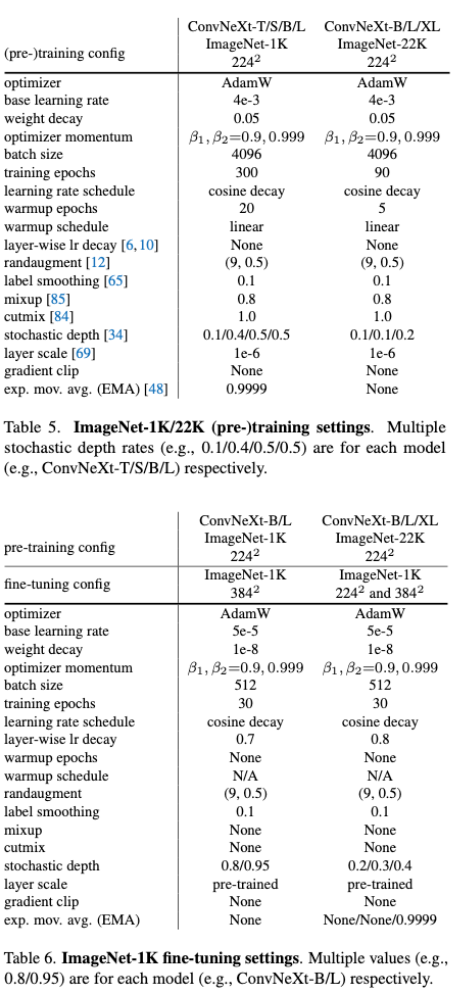
Training Techniques
- 在训练方式中,作者使用Swin Transformer(下文简称Swin)的训练方法,如:
- 300 epoch
- AdamW
- data aug:Mixup,Cutmix。。。。
- regularization schemes:Stochastic Depth、Label Smoothing
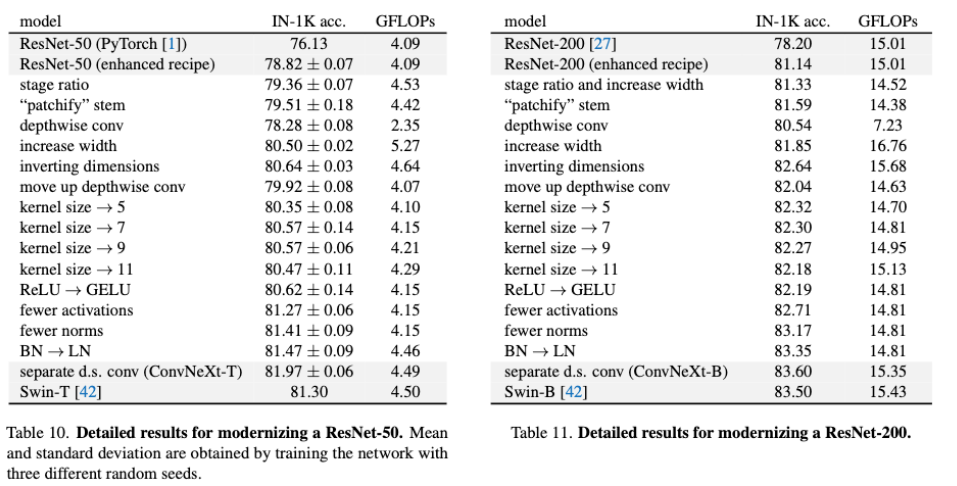
- 这个训练方式使得Res50的acc从76.1达到了78.8,也就是上图中第一个柱形图,这是模型修改的baseline
Macro Design
- 在宏观设计部分,作者主要修改了两个部分:
Changing stage compute ratio
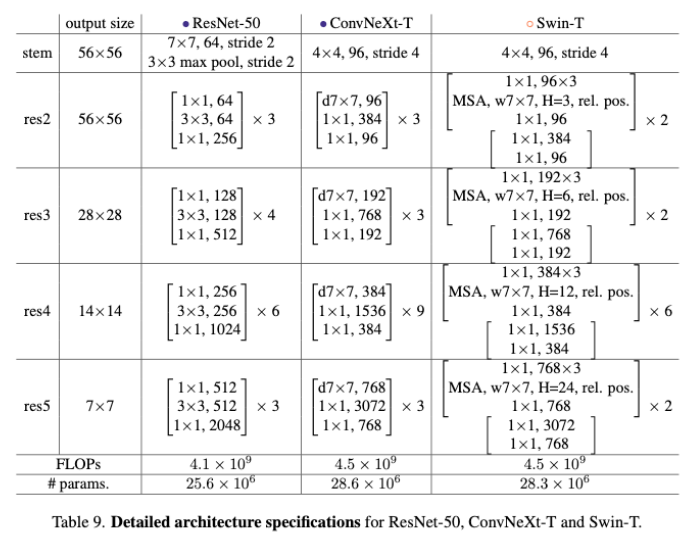
- 参照Swin的1:1:3:1和1:1:9:1的两个stage比例,将res50/200的比例改为3:3:9:3和3:3:27:3
- acc78.8到79.4
Changing stem to “Patchify”
- 参考Swin的local window的patch大小(4x4),使用kernel=4,stage=4的卷积核做类似设计
ResNeXt-ify
-
参考ResNeXt的思路,使用DWConv减少计算量,同时追求更大的width以弥补性能损失与追求更好的性能
-
ResNeXt可以参考Aggregated Residual Transformations for Deep Neural Networks这篇笔记
Inverted Bottleneck
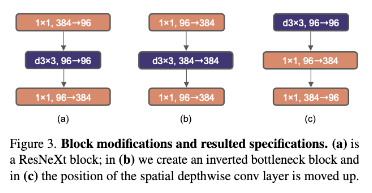
- a是ResNeXt的block结构,b是作者参考Swin涉及到Inverted Block,其中channel膨胀系数是4,c中较大的卷积核上移(这在下节说),减少了计算量的同时使得acc从80.5到80.6,其中res200多acc涨多比较多,从81.9到82.6
Large Kernel Sizes
- Swin中的window size至少为7x7,因此作者想到
Moving up depthwise conv layer
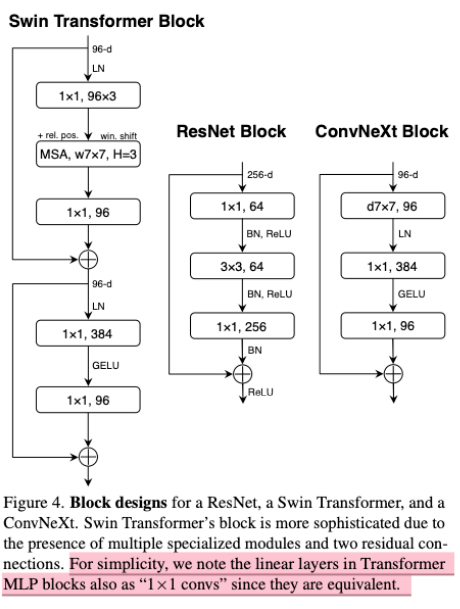
- 这也就是fig3的c图,这么设计是参考了Transformer中MSA与MLP的关系,作者这里将大号卷积等效为MSA,1x1卷积等效为MLP,这么做可以减少计算量
Increasing the kernel size
- 经过测试(k=3、5、7、9、11),kernel_size=7的时候性能最好同时计算量较小,于是Block改成这样
Micro Design
Replacing ReLU with GELU
- GELU比ReLU更加平滑
- 80.6%
Fewer activation functions
- 上图中(右边)ConvNeXt Block的激活函数只保留两个1x1之间的GELU
- 81.3%(+0.7)
Fewer normalization layers
- 参考Transformer的block中很少用到归一化操作,因此作者减少了ConvNeXt Block中的归一化层的数量,只保留7x7和1x1之间的一个
- 81.4%
Subsituting BN with LN
- BN可能对模型性能有损害(Batch太小会导致归一化不太一致,不过作者这Batch设了4096真是打扰了,这么大一般不太会有影响,最终也就涨了0.1),因此采用更有效简单的LN
- 81.5%
Separate downsampling layers
-
用kernel=2,stride=2替代max pooling/conv3x3,stride=2
-
这是考虑到Swin中downsampling的方式(印象中代码实现是叠加层数然后走fc压缩?)
-
82.0%
实验与总结
- 附录中有详细的改动性能变化
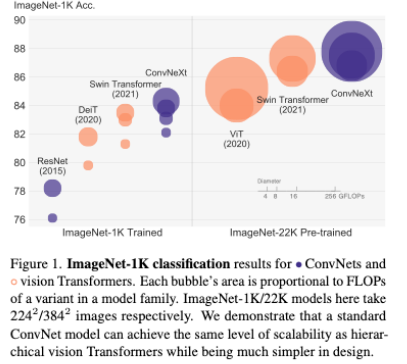
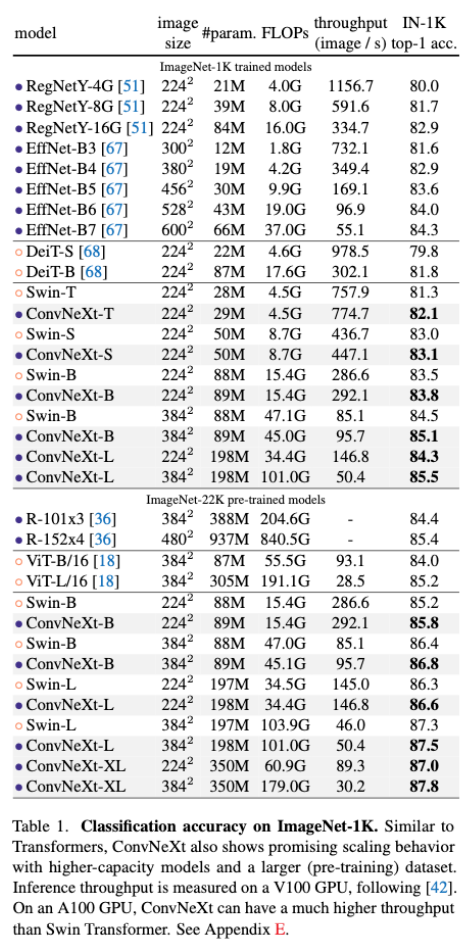
- IN-1K中的acc如下,注意看同等参数量/FLOPs下的性能就会发现整体比Swin好一丢丢
- 此外在下游任务中的表现也比较良好



















 3228
3228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











