






《A ConvNet for the 2020s》
Facebook AI Research(FAIR)
论文链接: https://arxiv.org/pdf/2201.03545.pdf
代码链接: GitHub - facebookresearch/ConvNeXt: Code release for ConvNeXt model
1 Introduction
ViT迅速成为主流的研究方向,然而,当应用于广义CV任务(如目标检测、语义分割)时,常规的ViT面临着极大挑战。因此,分层Transformer(如Swin Transformer)重新引入了ConvNet先验信息,使得Transformer成实际可行的骨干网络并在不同视觉任务上取得了非凡的性能。然而,这种混合方法的有效性仍然很大程度上归根于Transformer的内在优越性,而非卷积固有归纳偏置。
本文是FAIR的Zhuang Liu(DenseNet的作者)与Saining Xie(ResNeXt的作者)关于ConvNet的最新探索,以ResNet为出发点,逐步引入近来ViT架构的一些设计理念而得到的纯ConvNet新架构ConvNeXt,取得了优于SwinT的性能,让ConvNet再次性能焕发。
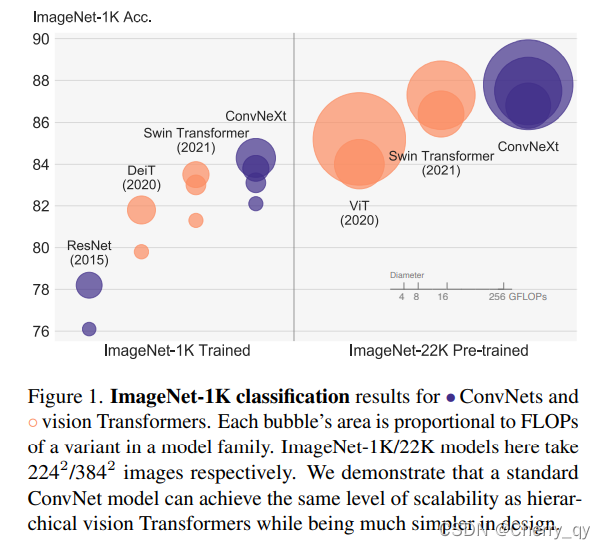
2 Modernizing a ConvNet:a Roadmap
下面研究从ResNet到ConvNeXt的演变轨迹,考虑两种不同FLOPs的模型:
ResNet50/Swin-T(FLOPs约4.5*10^9)与ResNet200/Swin-B(FLOPs约15*10^9).
为简单起见,仅展示ResNet-50/Swin-T模型的结果。另一种模型结果放在附录中。
我们以ResNet50作为出发点,首先采用类似ViT的训练技术对其重训练并得到ResNet50的改进结果(这将作为本文的baseline);然后我们研究了一系列设计准则,总结如下:
- Macro Design
- ResNeXt
- Inverted Bottleneck
- Large Kernel Size
- Various Layer-wise Micro Design.
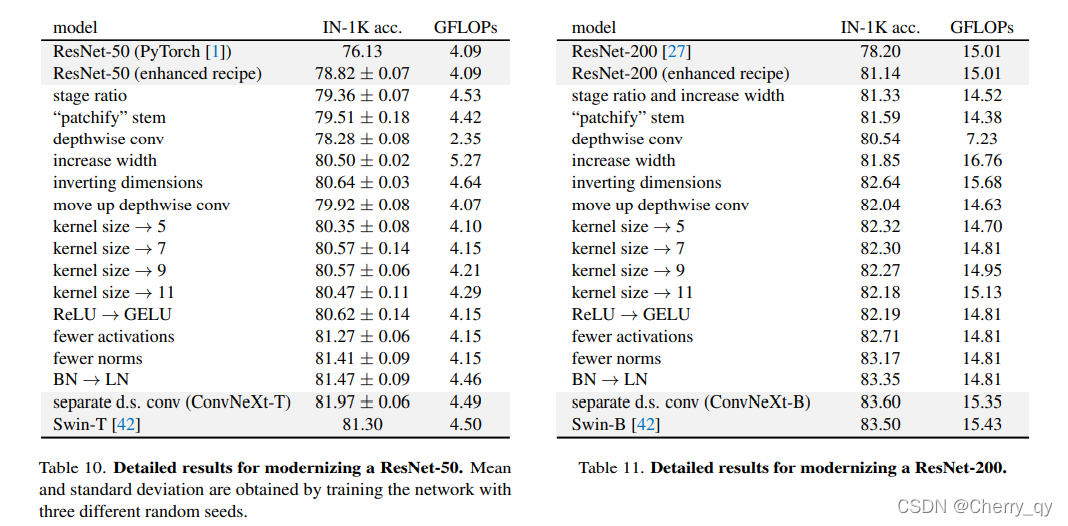
从下图可以看到网络架构每一次改变所能取得的性能(ConvNeXt-T取得了82%,超越了Swin-T的81.3%)。由于模型复杂度与最终性能相关,故FLOPs进行了一定程度的控制。
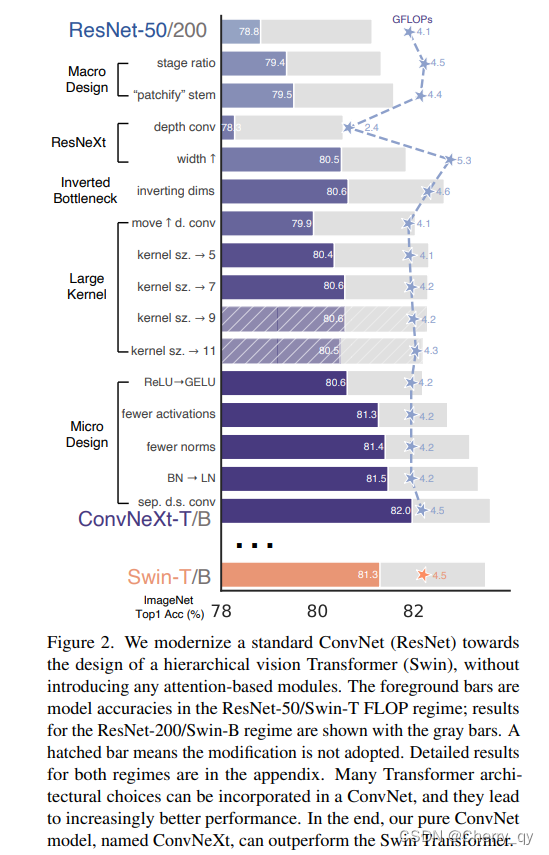
2.1 训练技巧
除了网络架构的设计外,训练方式也会影响最终的性能。
ViT不仅带来了新的模块与架构设计,同时还引入了不同的训练技术,如AdamW优化。
因此,第一步就是采用ViT的训练机制训练基线模型ResNet-50/200。
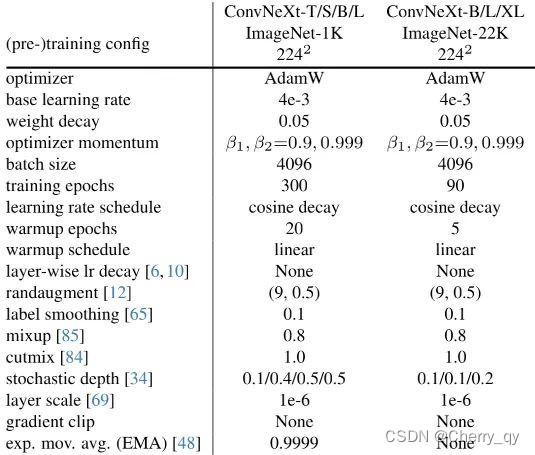
本文采用了DeiT与SwinTransformer的训练方案,可参见上表。
训练周期从原始的90epoch扩展到了300epoch;
优化器为AdamW,数据增广包含Mixup、Cutmix、RandAugment、RandomErasing;
正则化技术包含Stochastic Depth与Label Smoothing。
增强的训练技术将ResNet50的性能从76.1%提升到了78.8%,
这说明:Transformer与ConvNet的性能差距很大比例源自训练技术的升级。
2.2 Macro Design
分析SwinT的宏观架构发现,它参考ConvNet采用了multi-stage设计,每个阶段的特征图分辨率不同。
2.2.1 Changing stage compute ratio
原始ResNet的计算分布设计主要依靠经验。
“res4”的重计算设计是为了与下游任务(如目标检测)相兼容,因为检测头通常处理14*14的特征图;
而Swin-T参考了类似的设计准则,但将不同阶段的计算比例微调为1:1:3:1,更大规模的SwinTransformer的比例则为1:1:9:1。
参考该设计理念,我们将ResNet50每个阶段的块数从(3,4,6,3)调整为(3,3,9,3)。
此时模型的性能从78.8%提升到79.4%。
2.2.2 Changing stem to “Patchify”
一般来讲,Stem设计主要关心在网络起始部分如何对图像进行处理。
由于自然图像的信息冗余性,常见的Stem通过对输入图像下采样到适当的特征尺寸。
ResNet中的Stem包含stride等于2的卷积+MaxPool,它将输入图像进行4倍下采样;
而ViT则采用了"Patchify"策略,它对应了大卷积核(如14、16)、非重叠卷积;
SwinTransformer采用了类似的"Patchify",但patch size更小(=4)以兼容多阶段设计架构。
我们将ResNet中的Stem替换为的"Patchify"层(一个4*4,stride=4的卷积层)。
此时,模型的性能从79.4%提升到了79.5%。
# 标准ResNet
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=7, stride=2),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# ConvNeXt
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)2.3 ResNeXt-ify
尝试采用ResNeXt的设计理念。
具体来说,ResNeXt在Bottleneck block中为采用组卷积。
这种设计方式可以大幅减少FLOPs。
在本文中,我们采用depthwise卷积。depthwise卷积是一种特殊的组卷积,组数等于通道数。
depthwise卷积之前主要是应用在MobileNet和Xception中,用于降低计算量。但在本文中,作者发现DW conv每个卷积核单独处理一个通道,与self-attention很相似,都是在单个通道内做空间信息的混合加权。将bottleneck中的3*3卷积替换成DW conv。
同时将网络的宽度进行了提升(64→96),此时它与Swin-T具有相同的通道数。
此时,模型的性能提升到了80.5%,而FLOPs则提升到了53.G。
2.4 Inverted Bottleneck
在标准ResNet中使用的bottleneck是(大维度-小维度-大维度)的形式来减小计算量。后来在MobileNetV2中提出了inverted bottleneck结构,采用(小维度-大维度-小维度)形式,认为这样能让信息在不同维度特征空间之间转换时避免压缩维度带来的信息损失,后来在Transformer的MLP中也使用了类似的结构,中间层全连接层维度数是两端的4倍。
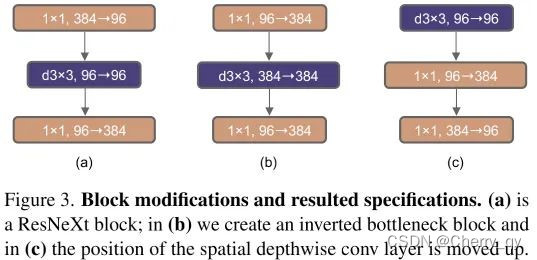
图3(b)的设计将网络的FLOPs下降到了4.6G。
并将模型的性能从80.5%提升到了80.6%。对ResNet200的性能提升则更大,从81.9%提升到了82.6%。
2.5 Large Kernel Size
ViT最重要的组成部分是其非局部自注意力,它使得每一层均具有全局感受野。
尽管SwinTransformer采用了局部窗口机制,但窗口尺寸仍至少为7*7,远大于ConvNet的3*3。
2.5.1 Moving up depthwise conv layer
将depthwise卷积的位置上移(图3(c))。这种设计理念等同于Transformer中的MHSA先于MLP。
这样的话复杂模块将拥有更少的通道数,1*1卷积层则负责做heavy lifting。
此时,模型的性能临时下降到了79.9%,而FLOPs也下降到了4.1G。
2.5.2 Increasing the kernel size
然后采用更大的卷积核,如3,5,7,9,11。此时,模型的性能从79.9%!提升到了80.6%(7*7),而模型的FLOPs几乎不变。
2.6 Various Layer-wise Micro Design
接下来,我们将从微观角度探索几种架构差异,主要聚焦于激活函数与Normalization层的选择。
2.6.1 Replacing ReLU with GELU
NLP与视觉架构的一个差异体现在激活函数的实用。ConvNet大多采用ReLU,而ViT大多采用GELU。我们发现ConvNet中的ReLU可以替换为GELU,同时性能不变(80.6%)。
2.6.2 Fewer activation functions
Transformer与ResNet模块的一个小区别:Transformer模块使用了更少的激活函数。类似的,我们对ConvNeXt模块进行改进,只在block的两个1*1卷积之间使用一层激活层,模型性能从80.6%提升到了81.3%(此时,它具有与Swin-T相当的性能)。
2.6.3 Fewer normalization layers
Transformer通常具有更少的Normalization层,因此我们移除两个BN层仅保留1*1卷积之前的一个BN。模型的性能提升到了81.4%,超越了Swin-T。
2.6.4 Substituting BN with LN
尽管BN是ConvNet的重要成分,具有加速收敛降低过拟合的作用;但BN对模型性能也存在有害影响。Transformer中的LN对不同的应用场景均具有比较好的性能。直接在原始ResNet中将BN替换为LN会导致性能下降,而组合了上述技术后再将BN替换为LN则能带来性能的提升:81.5%。
2.6.5 Separate downsampling layers
在ResNet中,每个阶段先采用stride=2的3*3卷积进行下采样;而SwinTransformer则采用了分离式下采样层。我们探索了类似的策略:采用stride=2的2*2卷积进行下采样,但这种方式导致了训练不稳定。因此在下采样前添加LN层。此时,模型的性能提升到了82.0%,大幅超越了Swin-T的81.3%。
self.downsample_layers = nn.ModuleList()
# stem也可以看成下采样层,一起存到downsample_layers中,推理时通过index进行访问
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
# 由于网络结构是downsample-stage-downsample-stage的形式,所以stem和后面的下采样层中的LN是不会连在一起的2.6.6 Closing remarks
到此为止,我们构建了如下图所示的block。
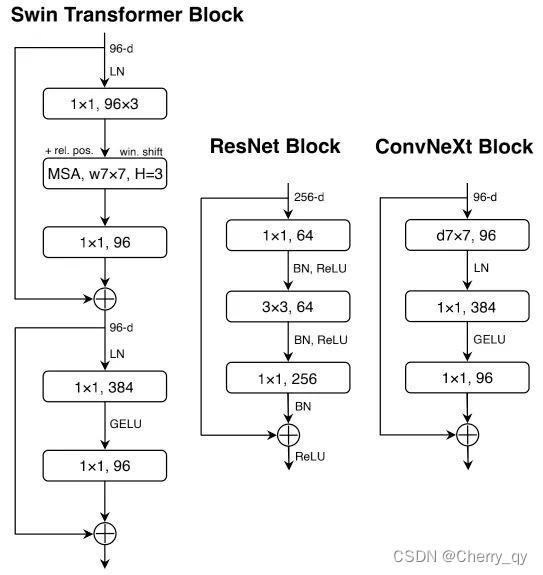
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
# 分组卷积+大卷积核
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
# 在1x1之前使用唯一一次LN做归一化
self.norm = LayerNorm(dim, eps=1e-6)
# 全连接层跟1x1conv等价,但pytorch计算上fc略快
self.pwconv1 = nn.Linear(dim, 4 * dim)
# 整个block只使用唯一一次激活层
self.act = nn.GELU()
# 反瓶颈结构,中间层升维了4倍
self.pwconv2 = nn.Linear(4 * dim, dim)
# gamma的作用是用于做layer scale训练策略
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
# drop_path是用于stoch. depth训练策略
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
# 由于用FC来做1x1conv,所以需要调换通道顺序
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x通过代码可以注意到,以上Block中两层1x1卷积是用全连接层来实现的,按照作者的说法,在GPU上进行实验时,使用全连接层会比使用卷积层略快。
至此,我们完成了ConvNet的进化之路,得到了超越SwinTransformer的纯ConvNet架构ConvNeXt。ConvNeXt具有与SwinTransformer相当的参数量、吞吐量、内存占用,更高的性能,且不需要依赖特定的模块(比如移位窗口注意力、相对位置偏置)。
3 Empirical Evaluations on ImageNet
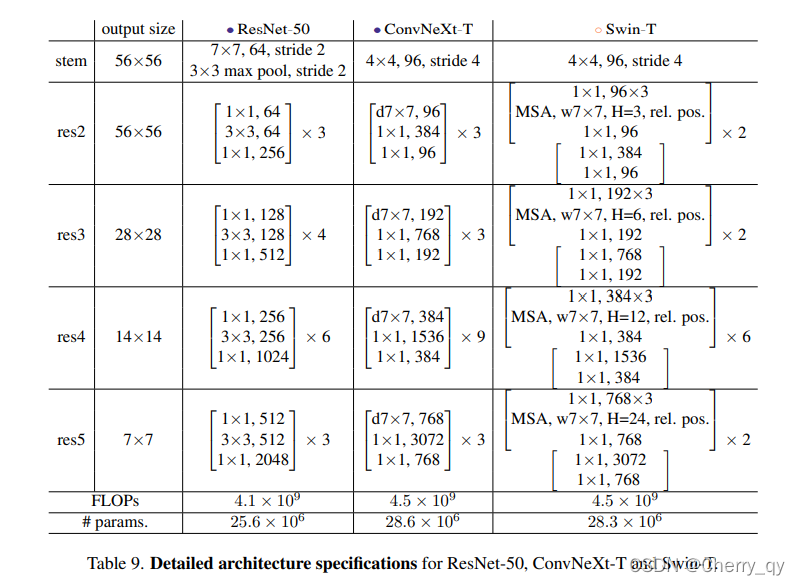
基于前述ConvNeXt架构,我们构建了ConvNeXt-T/S/B/L以对标Swin-T/S/B/L。此外,我们还构建了一个更大的ConvNeXt-XL以进一步测试ConvNeXt的缩放性。不同变种模型的区别在于通道数、模块数,详细信息如下:

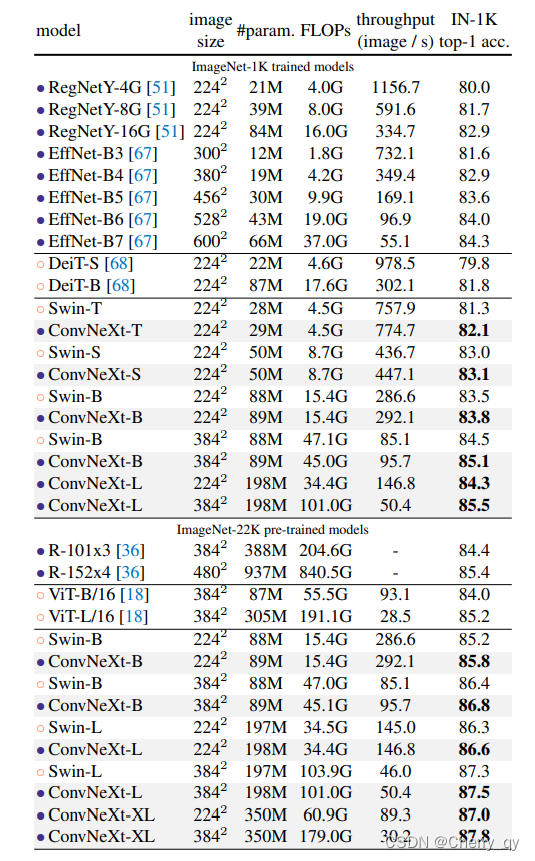
上表给出了ImageNet上的性能对比,从中可以看到:
ConvNeXt具有比ConvNet(如RegNet、EfficientNet)更佳的精度-计算均衡以及吞吐量;
ConvNeXt同样具有比SwinTransformer更佳的性能,且无需特殊操作模块;
ConvNeXt@384比Swin-B性能高0.6%且推理速度快12.5%;
仅需ImageNet训练,ConvNeXt-XL的性能即可达到85.5%;当采用ImageNet-22K预训练时,模型性能进一步提升到了87.8%。
Isotropic ConvNeXt vs. ViT
ConvNeXt的设计理念能否应用到ViT中呢?当没有下采样层,在所有深度都保持相同分辨率时,结果如下表:
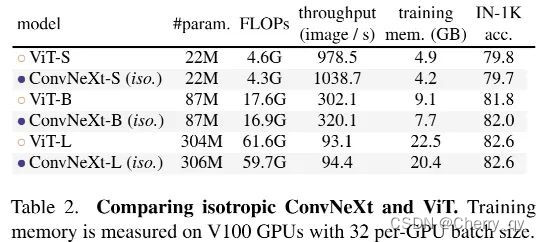
从中可以看到:两者具有相当的性能,这意味着:ConvNeXt的设计理念用于非分层模块时仍具有竞争力。
4 Empirical Evaluation on Downstream Tasks
4.1 Object detection and segmentation on COCO
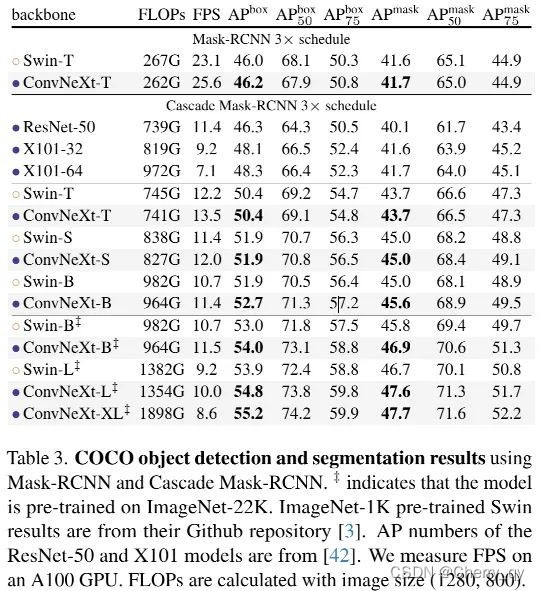
ConvNeXt取得了与SwinTransformer相当,甚至更优的性能。当采用更大的骨干且ImageNet22K预训练时,ConvNeXt的性能更佳。
4.2 Semantic segmentation on ADE20K
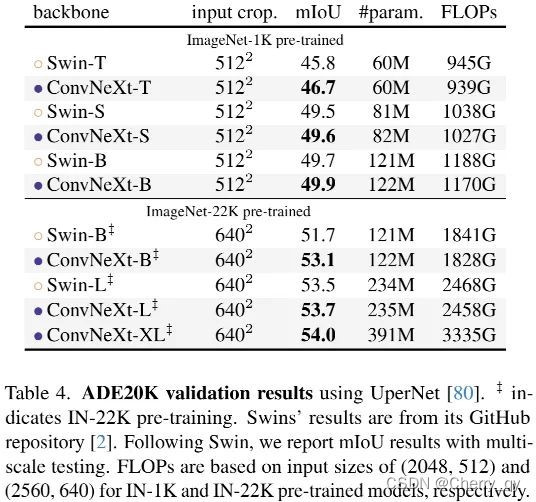
在不同容量大小下,ConvNeXt均可取得极具竞争力的结果,进一步验证了ConvNeXt的有效性。
4.3 Remarks on model efficiency
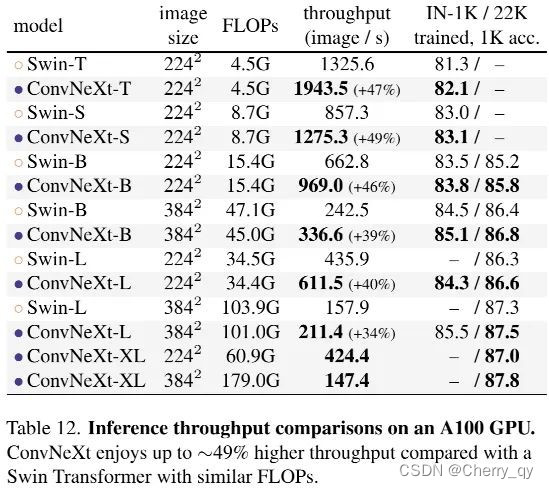
ConvNeXt具有比Swin更高的吞吐量、更高的精度。

















 6290
6290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









