







 本文从概率角度探讨线性回归模型,解释为何采用最小二乘法作为成本函数。通过将输出y视为随机变量,利用高斯分布进行建模,通过最大似然估计求解最优参数θ。同时,介绍了线性模型的推广——广义线性模型(GLM),它将响应变量的分布扩展至指数分散族,并允许使用不同的连接函数。
本文从概率角度探讨线性回归模型,解释为何采用最小二乘法作为成本函数。通过将输出y视为随机变量,利用高斯分布进行建模,通过最大似然估计求解最优参数θ。同时,介绍了线性模型的推广——广义线性模型(GLM),它将响应变量的分布扩展至指数分散族,并允许使用不同的连接函数。
模型
监督学习:given a training set, to learn a function h : X → Y so that h(x) is a“good” predictor for the corresponding value of y.
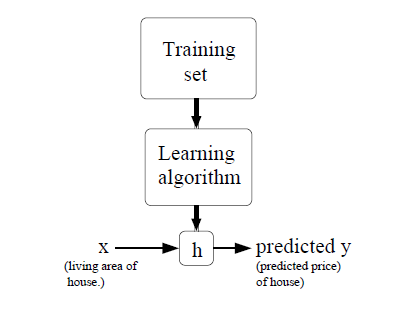
对于线性回归,我们假设可以通过一条直线拟合样本,从而预测y。所以我们假设:
hθ(x)=∑i=0nθixi=θTx
那么 cost function 为:
j(θ)=12∑i=1m(hθ(x(i))−y(i))2
,也就是最小二乘法(LMS)。为了最小化 j(θ) ,我们可以采用批梯度下降法(BGD)、随机梯度下降法(SGD)或者用normal equation直接求 θ 。
接下来从概率的角度来讨论为什么cost function要采用LMS?
Probabilistic interpretation
- 我们把输入y看成是随机变量。此时,
y(i)=θTx(i)+ϵ(i).
ϵ 可以代表各种误差,比如测量误差,或者因为其他未知的特征x引起的误差。假设这些误差都是独立同分布的,那么由大数定律可知 ϵ(i)∼N(0,σ2) ,
p(ϵ(i))=12π−−√exp(−(ϵ(i))22σ2).
所以可以得 y(i)|x(i);θ∼N(θTx(i),σ2) ,
p(y(i)|x(i);θ)=12π−−√exp(−(y(i)−θTx(i))22σ2).
注意,这里 p(y(i)|x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2769
2769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









