







 本文详细介绍了从感知机到支持向量机(SVM)的转变,探讨了函数距离和几何距离在两者中的作用。重点讲述了SVM中拉格朗日对偶性、Lagrange乘子、SMO优化算法及其步骤,以及启发式选择方法。通过这些内容,读者可以深入理解SVM如何寻找最佳超平面以及如何处理非线性数据。
本文详细介绍了从感知机到支持向量机(SVM)的转变,探讨了函数距离和几何距离在两者中的作用。重点讲述了SVM中拉格朗日对偶性、Lagrange乘子、SMO优化算法及其步骤,以及启发式选择方法。通过这些内容,读者可以深入理解SVM如何寻找最佳超平面以及如何处理非线性数据。
duality chapter有错误,待修订
本文会介绍感知机和支持向量机的原理,着重阐述这两个算法中的一些逻辑推导思路。
1.基础知识:函数距离(functional margins)和几何距离(geometrical margins)
假设 x∈Rn ,那么显然 wTx+b=0 是一个超平面。通过推导,空间中的任意一点 x(i) 到这个超平面的距离为
假设我们有样本点 A(x(i),y(i)),y(i)∈{
1,−1} ,
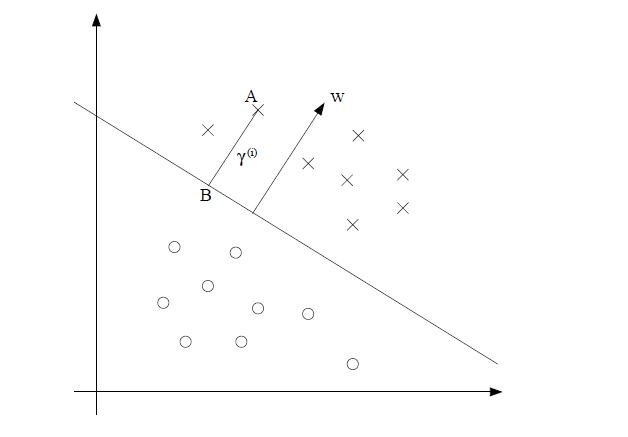
我们定义几何距离(geometrical margins)为
接着我们定义函数距离(functional margins)为
这两个距离有什么特征呢?
① 函数距离可以表示分类的正确性和确信度:当 wTx(i)+b>0 时,说明样本A在超平面的上方,也就属于1类(记上图圆点为-1,叉点为1),如果此时 y(i) =1,那么A样本分类正确, γ^(i)>0 ;否则 γ^(i)<0 。
② 同倍数扩大或缩小w、b,超平面是不变的,函数距离会同等增减;而几何距离不变,因为点到固定平面的距离是不变的。
③ γ^(i)=γ^∗||w||
那这些特性有什么用呢?其实它们在感知计算法中起着重要作用
2.感知机(Perceptron)
利用特性①,我们可以判断样本点是否分类正确,最终画出一个超平面能把线性可分的数据正确分类(注意是线性可分的训练数据);利用特性②,我们可以用误分类样本点的几何距离之和来表示模型的损失函数。
1、具体地,对于误分类点来说, −y(i)(wTx(i)+b)>0 ,所以所有误分类点到超平面的总距离是
M为误分类的集合。这里我们可以直接省略 1||w|| ,就得到感知机学习的损失函数 L(w,b)=−∑x(i)∈My(i)(wTx(i)+b) 。
为什么可以直接省略 1||w|| ?
(1).因为感知机模型是以误分类点为驱动的,最后损失函数的值必然为零,即无误分类点。所以根据特性①,既然函数距离能判断样本点的分类正确性,我们何必用几何距离呢?实际上我们并不关心lost function具体数值的变化,我们只在乎还有没有误分类点。
(2).去掉 1||w|| ,我们得到的lost function是关于w,b的连续可导线性函数,可以用梯度下降法轻松地进行优化。
2、利用随机梯度下降法SGD,损失函数的梯度为
随机选取一误分类点,对w,b进行更新:
3、算法:
给定数据集T,学习率 η
(1)选取初值 w0,b0
(2)根据函数距离选取误分类点
(3)更新 w,b
(4)转至(2),直至没有误分类点
4、可证明对于线性可分数据集,感知机算法是收敛的,具体见《统计学习方法》。
3.支持向量机(SVM)
3.1.从感知机(Perceptron)到支持向量机(SVM)
感知机学习算法会因采用的初值不同而得到不同的超平面。而SVM试图寻找一个最佳的超平面来划分数据,怎么算最佳呢?我们自然会想到用最中间的超平面就是最好的。如下图
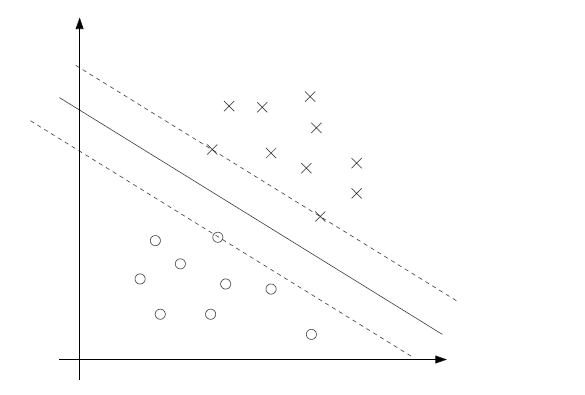
显然在SVM中我们不能在使用函数距离 γ^(i) 来作为损失函数了,当我们试图使上图虚线之间的”gap”,最大自然要用几何距离。
我们定义
通过最大化 γ 就可以找到最大的gap。
根据特性③,我们可以将上面的优化问题转化为
可是这个优化问题并不容易求解,我们期望目标函数是一个凸函数,这样优化起来就比较方便了。
这时注意到函数距离的特性②,我们可以直接让 γ^=1 。Why?假设我们这个优化问题的最优解是 wopt,bopt ,那么我们可以总是可以同倍数地调整 wopt,bopt 使得 γ^=1 ,而此时最优超平面是不变的,所以上面的优化问题可以化成
这样SVM模型就转化为了一个二次规划问题(Quadratic Programming)。此时我们可以用matlab的一些工具来处理这个优化问题了,可是一旦数据量变大,计算就会变得很缓慢。所以我们此时把这个优化问题转化为一个拉格朗日对偶问题,此时不仅能简化计算,更能引入SVM中最重要的kernel概念。啥是拉格朗日对偶问题?为什么能简化计算?什么是kernel?为什么能引入kernel?好吧,我承认问题有很多,不过让我们一一来窥探。
3.2. Lagrange Duality
首先来看看wiki上对Lagrange Multipler和Lagrange Duality的说明
Lagrange Multipler:In mathematical optimization, the method of Lagrange multipliers is a strategy for finding the local maxima and minima of a function subject to equality constraints.
1.对于最简单的只有等式约束的规划问题,例如:
这个优化问题可以粗略地用函数等高线图来表示
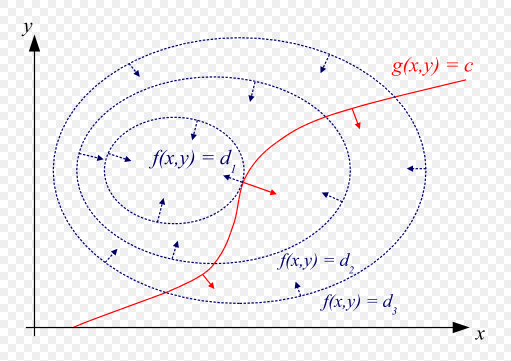
我们的目标就是要找到一点相切点 (x0,y0) ,使得 f(x,y) 达到最小值,因为梯度和等高线图是垂直的,所以 f(x,y)和g(x,y) 在点 (x0,y0) 上的梯度是平行的,此时, ∇x,yf=−λ∇x,yg ,其中 ∇x,yf=(∂f∂x,∂f∂y) , ∇x,yg=(∂g∂x,∂g∂y) , −λ 就是两个向量的平行参数。
我们可以引入一个拉格朗日乘子 λ 得到Lagrange Function
那么令 ∇x,yL=0 就是平行条件, ∇λL=0 就是原始问题的等式约束,这样就把原问题放到一个Lagrange Function中求解。
2.对于更一般的优化问题的原始问题,会有不等式约束例如:
原问题的定义域: D=(∩mi=0domfi)∩(∩pj=1domhj)
可行点(feasible): x∈D ,且满足约束条件。
可行域:所有可行点的集合F。
最优化值: p∗=inf{ f0(x)|fi(x)⩽0,hj(x)=0} (求下确界inf和求最小值min在这里是等价的)
注意定义域和可行域的差别:定义域和约束条件无关,一般来说定义域大于可行域。
步骤1:定义一个Lagrange函数为
假设对L函数在 x∈D 上逐点求下确界(参考boyd的《convex optimization》)的函数是
如果我们把原问题的约束条件 (fi(x)⩽0,hj(x)=0) 代入Lagrange function,那么对于原问题中可行域F中的任意可行点 x˜ 有
这个不等式可以推导出两个结果:
① 因为L函数后两项小于等于0,所以, maxλ,νL(x,λ,ν)=f0(x) (注:这里的 f0(x) 是关于x的函数),进而
我们称这个式子为对偶问题中的Primal Problem
② 因为L函数后两项小于等于0,所以
(注:这里的 f0(x˜) 是一个具体的值)
根据下确界的性质:一系列函数逐点下确界必然小于等于这一系列函数,有
因为 x˜ 是可行域F中的任意值,所以
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









