






最近在跟着相关指导书,利用python对机器学习的相关模型进行实战,但是其中有一个predict函数让我感到很头疼,然后查了一些资料,结合个人的总结,写下这篇文章,想跟大家一起探讨一下,如果我有哪里说错了请见谅,本人虚心接受批评指正。当然,如果这篇文章还能入得了各位“看官”的法眼,麻烦点赞、关注、收藏,支持一下!
本文为了显示的整洁,所以格式中统一不使用“逗号”,但是在编程的时候该用还是要用
一、predict函数的功能
predict函数就是对测试集中的样本点数据进行预测,配合fit函数使用
二、predict函数的使用
predict函数一般与fit函数配合使用,比如
svc.fit(x_train,y_train)
y_out=svc.predict(x_in)
其中x_train是训练集中的样本点数据,y_train是训练样本点数据对应的标签,x_in是测试集中的样本点数据,y_out是预测结果
三、predict函数中x_in的格式说明
先给出结论:predict函数中的样本点数据格式应该与fit函数中样本点数据格式保持一致
比如说,x_train是一个二维的numpy数组,那么x_in必须也是一个二维的numpy数组!!!
PS:为方便书写,本文后续都以二维numpy数组为例进行说明
当x_in是一个二维的numpy数组时,其具体表现形式如下:

特殊情况:
1、一个样本多个特征时:
x_in的格式应写成:![]() 。
。
(注意:x_in是一个二维的numpy数组,即是有两对中括号的,仅写一对中括号系统会报错)
以《深入浅出python机器学习》这本书上的内容举例:
样本是X[312]
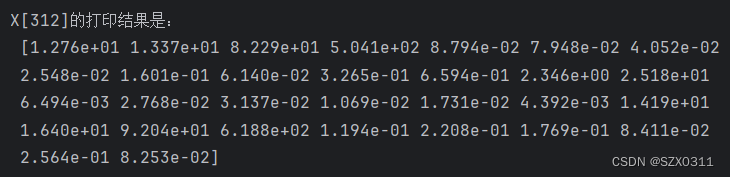
运行代码print(X[312].ndim)可以知道其维度是1
运行代码print(type(X[312]))可以知道它的类型是numpy.ndarray,即numpy数组
如果直接运行代码print(gnb.predict(X[312]))系统会提示错误,错误内容如下:
(PS:gnb是我自定义的模型的名字)

但是如果、将X[321]改变成二维数组的格式并打印出来,即运行代码print(np.array([X[312]]))可得

运行代码print(np.array([X[312]]).ndim)可知维度是2
运行代码 print(type(np.array([X[312]])))可以知道它的类型是numpy.ndarray,即numpy数组
然后我们运行代码print("结果是:",gnb.predict(np.array([X[312]]))),代码正常运行,如下

2、一个特征多个样本时:
针对一个特征多个样本时,很多小伙伴常会错写成如下格式:

但其实上面这种格式是一个一维numpy数组,所以会出现报错现象,因此,应该写成:

















 6568
6568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









