






问题一:分析为什么平方损失函数不适用于分类问题,交叉熵损失函数不适用于回归问题。
平方损失函数的定义为:
对于特定的分类问题,平方差的损失有上限但交叉熵则可以用整个非负域来反映优化程度的程度。
线性回归中求解最优参数中使用的最大似然估计和最小二乘法的解相同,而最大似然估计是对于高斯分布而言,因求解参数效果相同,所以使用平方损失函数就类似假设了高斯先验。由于高斯分布不适合分类问题所以平方损失函数也不适用。
交叉熵函数定义:
交叉熵函数结果只和正确分类的结果有关;
回归问题关注的是预测结果和真实结果之间的差距,而交叉熵函数只关注于真确的分类结果忽略错误的分类结果。回归问题中需要让预测的函数满足所有的样本,这样就要包含错误的样本,所以交叉熵不适用于回归任务。
总结:交叉熵损失函数适用于分类问题 (离散),不适用于回归问题 (连续)。
问题二:对于一个三分类问题,数据集的诊室标签和模型的预测标签如下: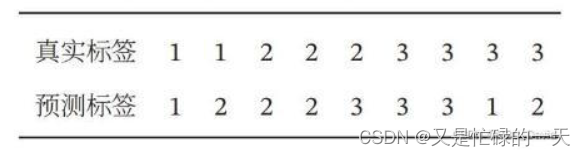
分别计算模型的精确率、召回率、F1值以及它们的宏平均和微平均。
精确率(Precision):是衡量模型预测精度的度量指标。在二元分类问题中定义为:
TPc:真实标签为c,预测也为c FNc:真实为c,预测不为c
FPC:真实标签不为c,预测标签为c TNc:真实不为c,预测也不为c
召回率(Recall):也被称为查全率,是信息检索和统计学分类领域中的一个重要度量值。它表示检索出的相关文档数与文档库中所有的相关文档数的比率,用于衡量检索系统的查全率。
F值(F Measure):是一个综合指标,为精确率和召回率的调和平均:
宏平均:每一类的性能指标的算数平均值
微平均:每一个样本的性能指标的算数平均值















 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









