






2自由度机械臂轨迹跟踪控制,6自由度机械臂轨迹跟踪控制,基于强化学习DDPG的机械臂轨迹跟踪,控制算法,强化学习算法,将强化学习DDPG作为机械臂的轨迹跟踪控制器,simulink仿真。
ID:69750670530607621
欲买桂花同载酒
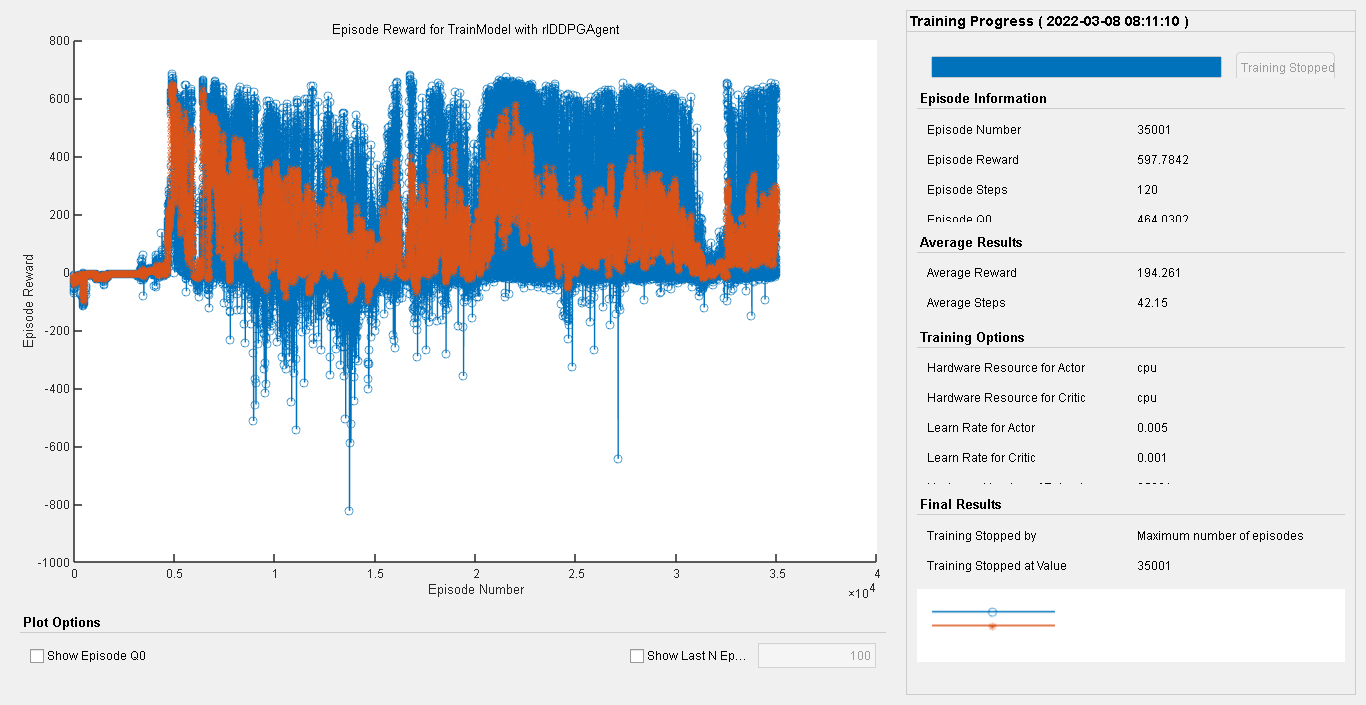
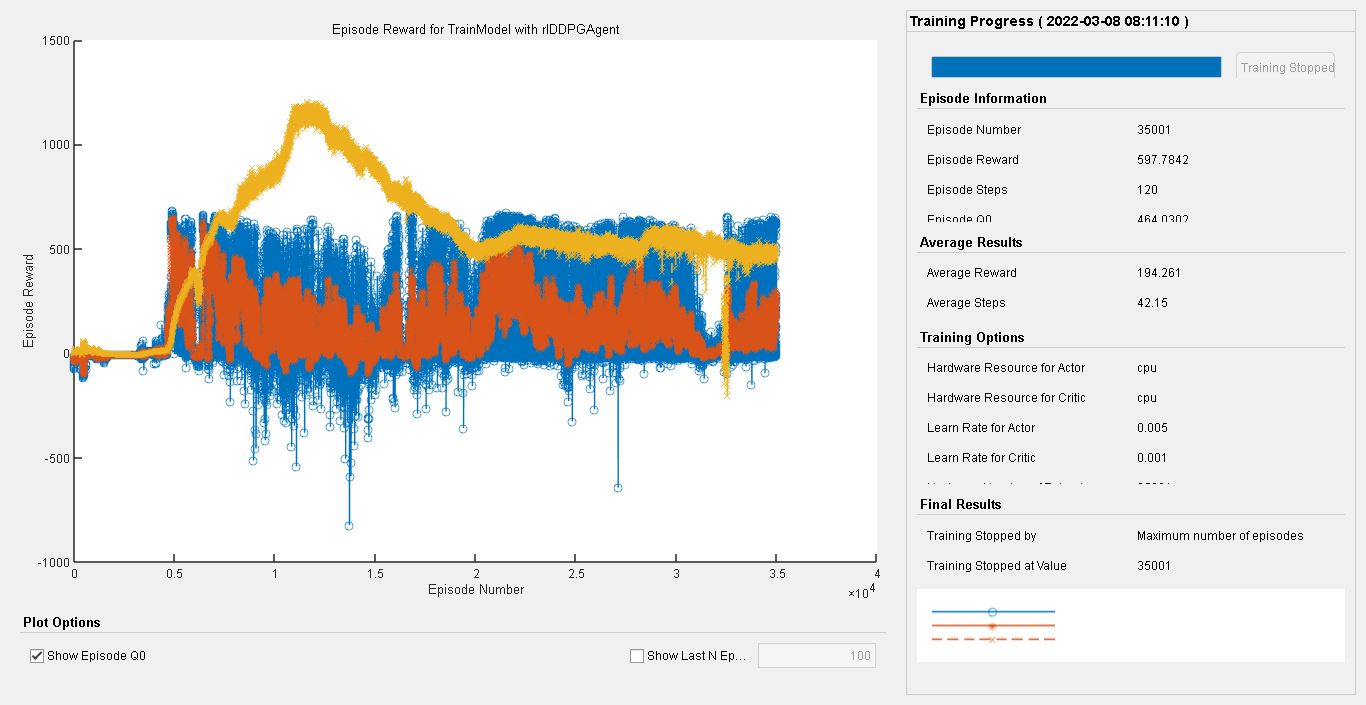
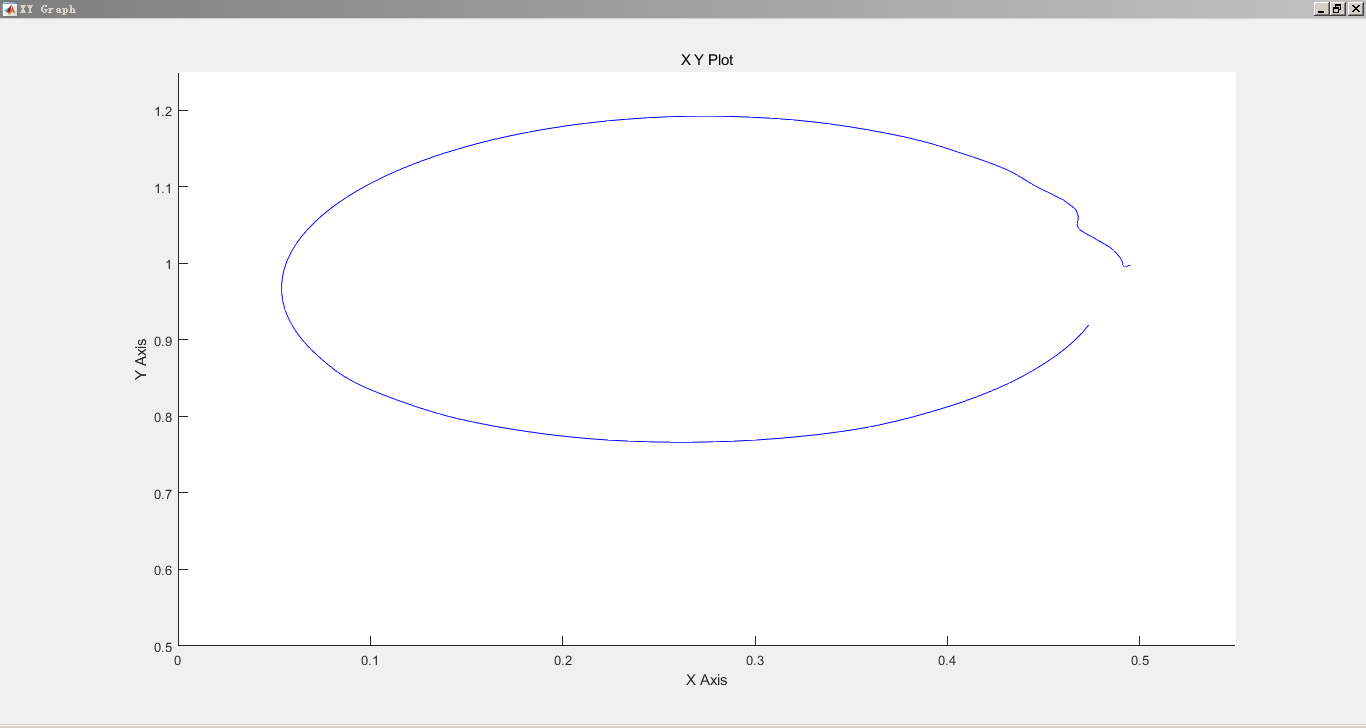
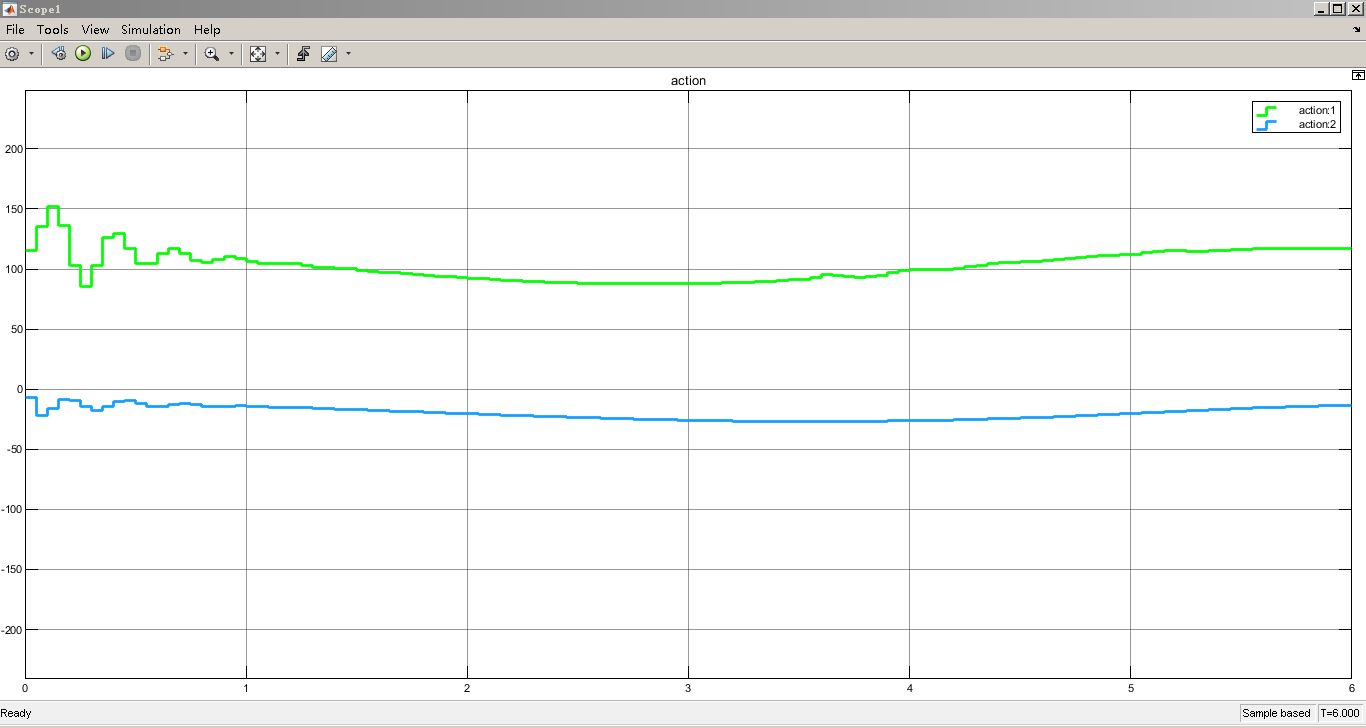
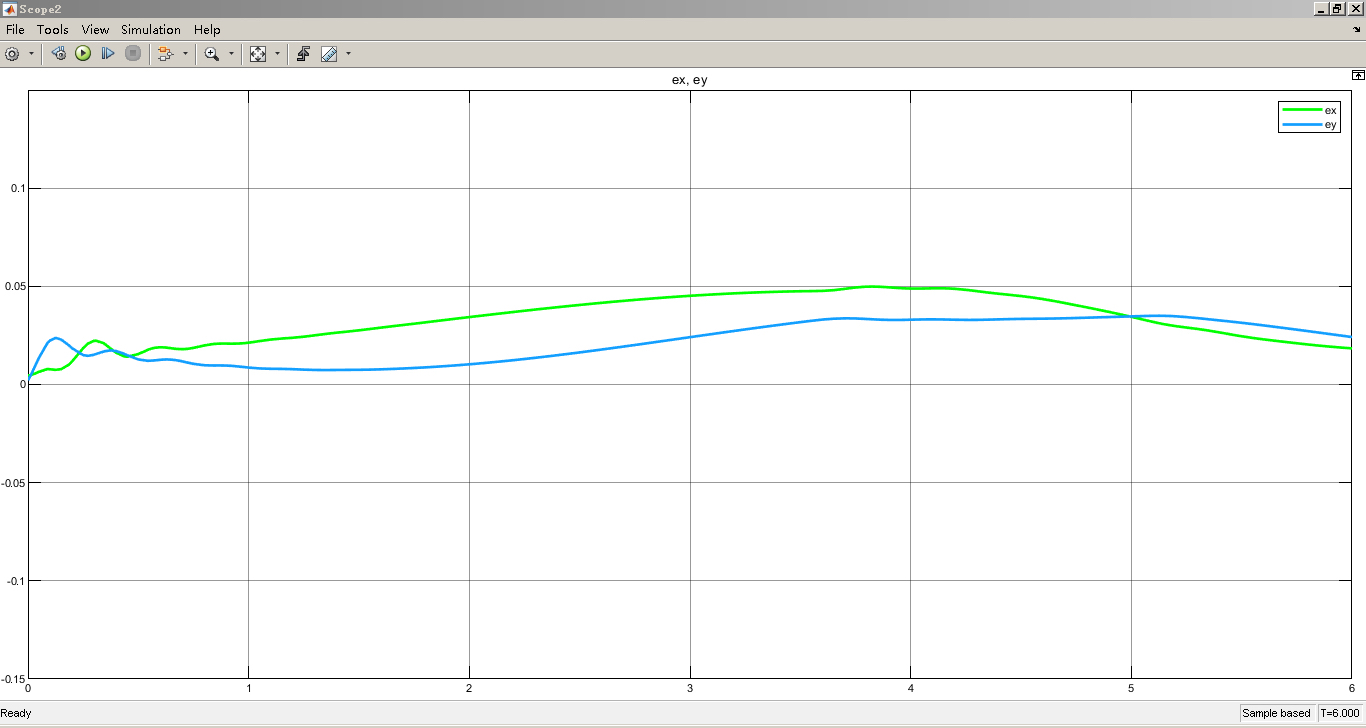
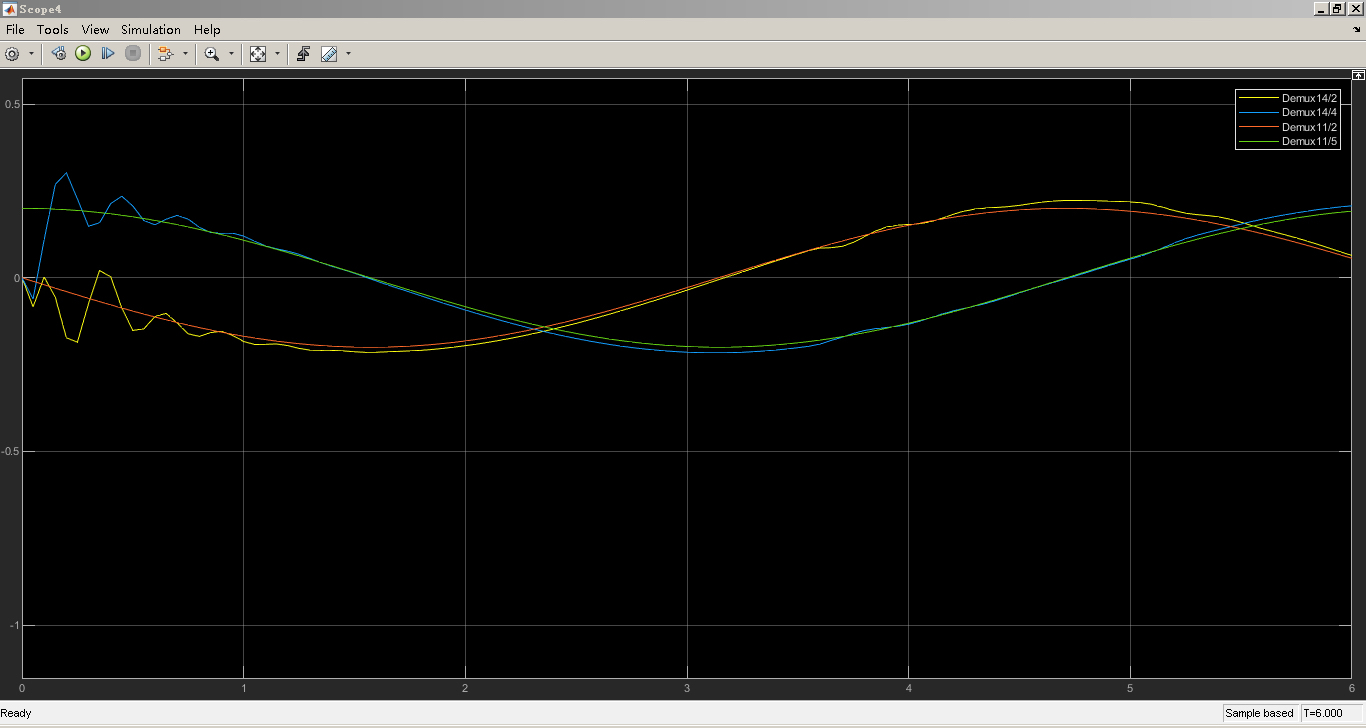
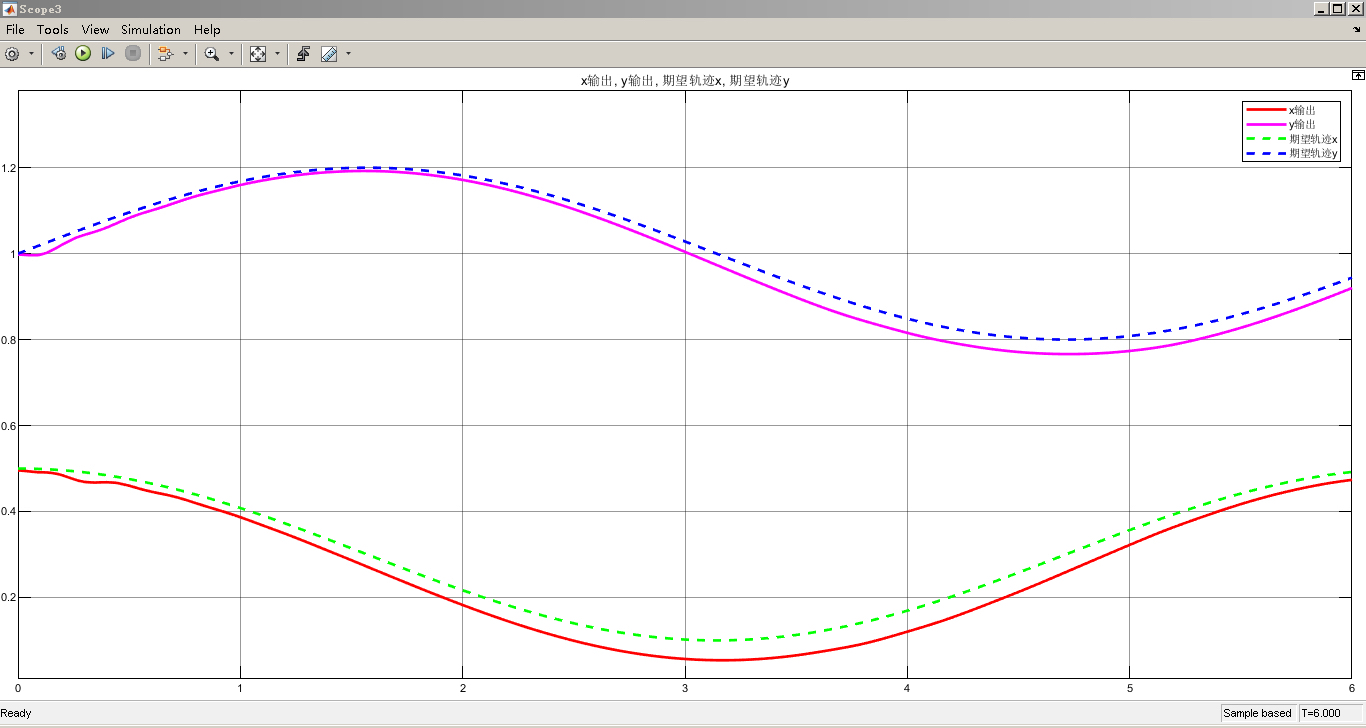
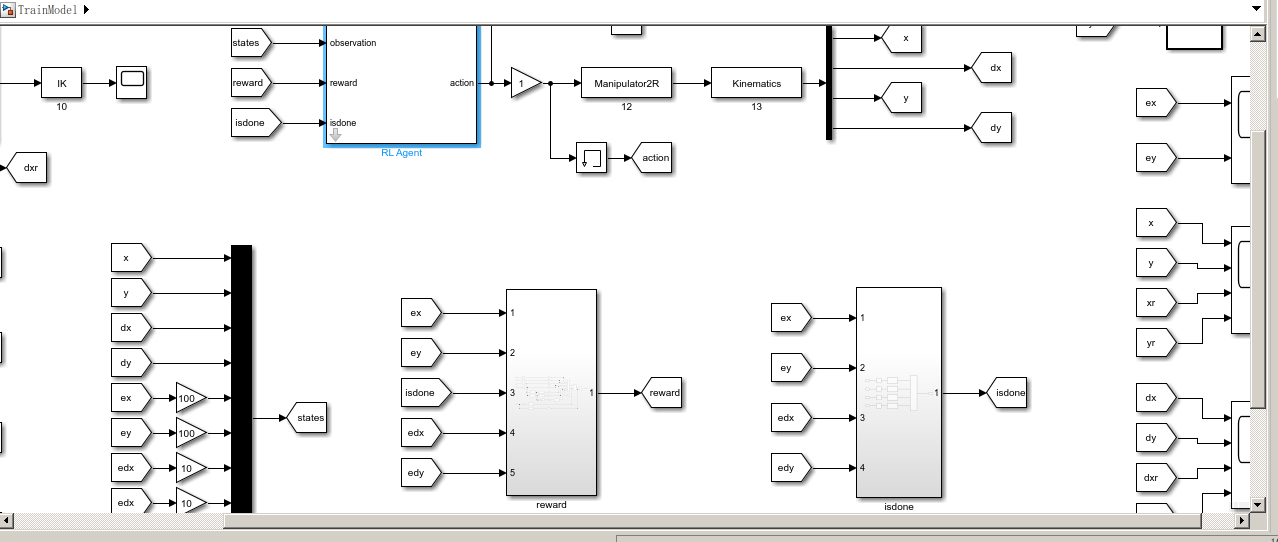
2自由度机械臂轨迹跟踪控制和6自由度机械臂轨迹跟踪控制一直是机器人领域的研究热点之一。随着机器人技术的不断发展和应用场景的多样化,对机械臂轨迹跟踪控制算法的需求也越来越高。本文将介绍一种基于强化学习DDPG的机械臂轨迹跟踪控制算法,并通过在Simulink仿真环境下的实验验证其性能。
首先,我们来了解一下强化学习DDPG算法。DDPG(Deep Deterministic Policy Gradient)是一种基于策略梯度的强化学习算法,它能够处理连续动作空间和高维状态空间的问题。DDPG算法通过构建Actor网络和Critic网络,并利用经验回放和目标网络来提高策略的稳定性和收敛性。在机械臂轨迹跟踪控制问题中,DDPG算法可以用来学习机械臂的控制策略。
针对2自由度机械臂轨迹跟踪控制问题,我们设计了以下实验方案。首先,我们建立了一个包含两个关节的机械臂模型,并定义了轨迹跟踪的目标函数。然后,我们使用DDPG算法来学习机械臂的控制策略,并将其作为机械臂的轨迹跟踪控制器。在仿真过程中,我们通过不断更新Actor和Critic网络的参数来优化控制策略,并观察机械臂在不同轨迹下的跟踪效果。
接下来,我们考虑6自由度机械臂轨迹跟踪控制问题。由于关节数量的增加,问题的复杂度也相应增加。在这种情况下,我们需要对DDPG算法进行适当的修改和调整。一种常用的方法是引入多个Actor和Critic网络,并进行合理的参数共享。通过这种方式,我们可以充分利用机械臂的自由度,提高轨迹跟踪控制的精度和效率。
通过Simulink仿真实验,我们可以对基于强化学习DDPG的机械臂轨迹跟踪控制算法进行性能评估。我们可以通过比较机械臂的实际轨迹和期望轨迹之间的误差来衡量算法的控制精度。此外,我们还可以观察机械臂在不同环境和轨迹下的控制效果,验证算法的鲁棒性和通用性。
综上所述,本文提出了一种基于强化学习DDPG的机械臂轨迹跟踪控制算法,并通过Simulink仿真实验验证了其性能。该算法可以有效解决2自由度和6自由度机械臂轨迹跟踪问题,并具有良好的控制精度和鲁棒性。技术上,本文采用了DDPG算法和Simulink仿真环境,并结合机械臂模型进行了详细的实验分析。通过本文的研究,我们可以为机械臂轨迹跟踪控制问题提供一种新的解决思路和方法。
相关的代码,程序地址如下:http://wekup.cn/670530607621.html
















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









