







本文约2700字,建议阅读6分钟
本文概述了分层问题解决的认知基础,以及如何在当前的 HRL 架构中实现这些基础。根据认知心理学的资料,生物主体复杂问题解决行为的发展,依赖于分层认知机制。分层强化学习是一种很有前途的计算方法,最终可能会在人工代理和机器人中产生类似的问题解决行为。然而,到目前为止,人类和动物的解决问题的能力明显优于人工系统。
在这里,德国汉堡大学的研究人员提出了整合受生物学启发的分层机制的步骤,以实现人工智能代理的高级问题解决技能。
研究人员通过认知心理学文献,发现组合抽象和预测处理的重要性。然后,将获得的见解与当代分层强化学习方法联系起来。
有趣的是,他们的研究结果表明,所有已识别的认知机制,都已经在孤立的计算架构中单独实现;这引发了一个问题,即为什么不存在将它们集成在一起的单一统一架构。研究人员通过提供关于开发这种统一架构的计算挑战的综合观点来解决这个问题。
该研究以「Intelligent problem-solving as integrated hierarchical reinforcement learning」为题,于 2022 年 1 月 25 日发布在《Nature Machine Intelligence》。

人类和某些聪明的动物有能力将复杂的问题分解成更简单的、以前学过的子问题。这种分层方法使他们能够以零样本的方式解决以前看不见的问题,也就是说,无需任何试错。
例如,下图描绘了一只乌鸦如何解决一个由三个因果步骤组成的「不平凡的食物获取」难题:它首先拿起一根棍子,然后用棍子接近一块石头,然后用石头激活一个机制释放食物。

图示:一只乌鸦解决了食物获取问题。(来源:论文)
有许多类似的实验证明了灵长类动物、章鱼,当然还有人类的类似能力。人类和动物的认知研究表明,分层学习和解决问题对于这些技能的发展至关重要。
这就提出了一个问题,即我们如何为智能人工智能代理和机器人配备类似的分层学习和零样本解决问题的能力。
研究人员从强化学习(RL)的角度来解决这个问题。几项研究表明,RL 在生物学和认知上是合理的。许多现有的基于 RL 的方法旨在解决零样本问题和迁移学习,但这目前仅适用于相同或相似任务的微小变化或简单的合成领域,例如二维(2D)网格世界。
与上图中乌鸦的行为相当的连续空间问题解决行为,尚未通过任何人工系统完成。鉴于分层 RL (HRL) 的研究代表性不足,研究人员认为很大程度上是缺少对分层学习和问题解决的关注。
研究人员分三个步骤解决这一差距。首先,评估了分层决策的神经认知基础,并确定了能够实现高级问题解决能力的重要机制。其次,揭示了当代 HRL 方法的一个整合问题:表明生物学机制大部分已经实施,但只是孤立地而不是以整合的方式实施。最后,提出了结合关键方法和机制的步骤,以克服开发统一认知架构的集成挑战。
神经认知基础
该研究中,研究人员提出生物制剂中复杂的问题解决技能,可以通过特定的认知能力来区分。在他们看来,这些能力取决于关键的认知机制,包括抽象、内在动机和心理模拟。下图概述了这些机制如何从正向和反向模型发展为基本的神经功能先决条件。
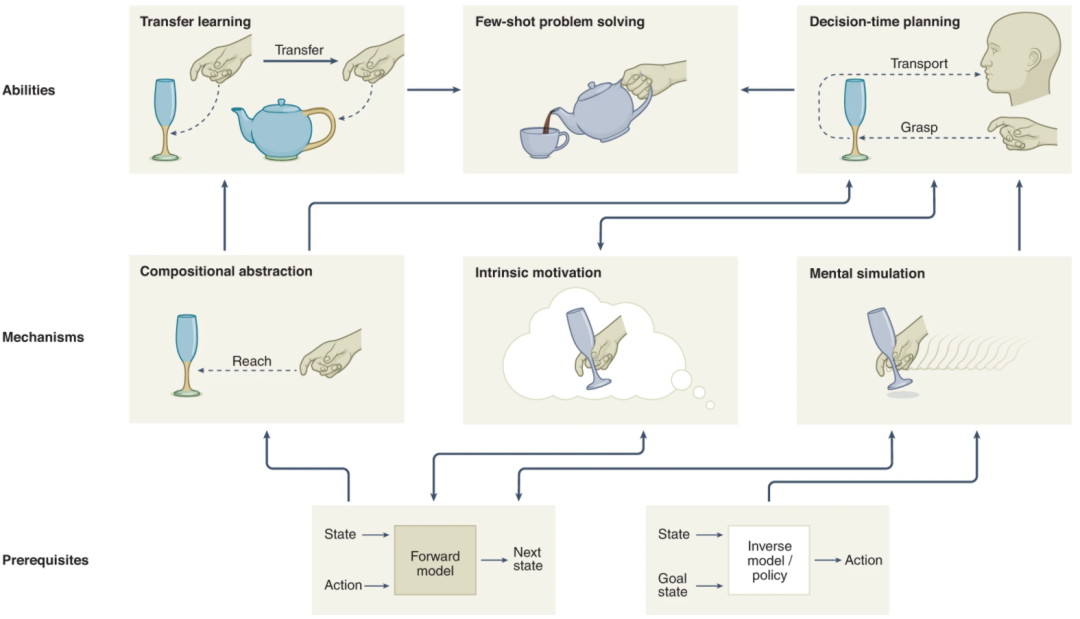
图示:生物问题解决的先决条件、机制和特征。(来源:论文)
计算实现
计算 HRL 机制不如生物制剂集成。该研究中,研究人员总结了与神经认知基础相关的计算方法的最新状态。通过对神经认知基础的调查表明,解决小问题需要两种基本认知能力:迁移学习和规划。
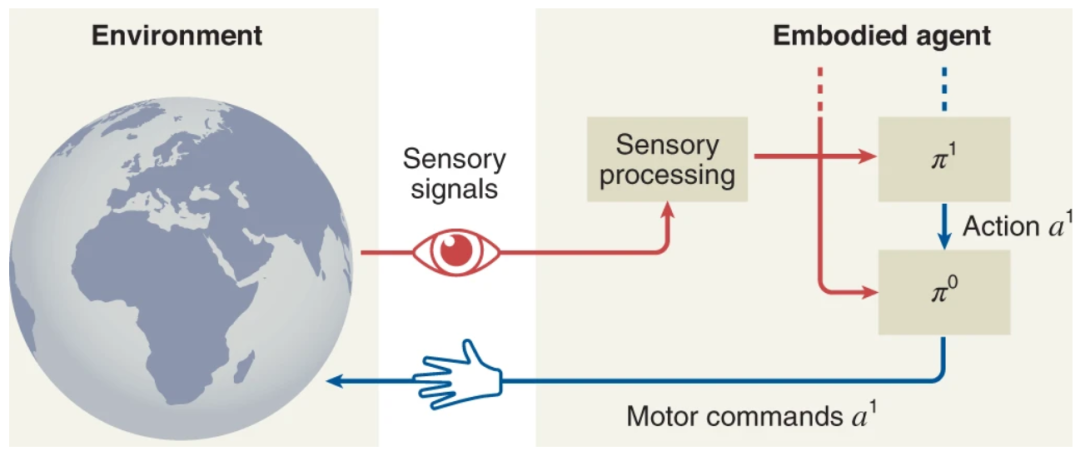
图示:通用分层问题解决架构。(来源:论文)
迁移学习
迁移学习对于分层架构来说是很自然的,因为它们可以潜在地重用一般的高级技能并将它们应用于不同的低级用例,反之亦然。因此,现有迁移学习方法的很大一部分建立在学习可重用的低级策略之上。研究不仅考虑了不同任务之间的迁移学习,还考虑了不同机器人和代理形态之间的迁移学习。
规划
计划可以分为决策时间计划和背景计划。决策时间计划是指对一系列动作进行搜索,以决定接下来要执行哪个动作以实现特定目标。
通过使用域动态的内部预测模型模拟动作来实现搜索。决策时间计划可以实现零样本问题解决,因为只有在内部预测模型验证操作成功时,代理才会执行计划的操作。背景规划是指 Sutton 引入的基于模型的 RL。它用于通过使用前向模型模拟动作来训练策略。
这可以提高采样效率,但不能达到解决小样本问题的程度。
分层决策时间规划是经典人工智能中众所周知的范例,但将其与 HRL 集成的方法很少见。一些方法通过使用,用于高级决策的动作规划器和用于低级运动控制的强化学习器,将动作规划与 RL 相结合。这些方法支持决策时间规划,对于离散状态动作空间中的高级推理特别有用。
迁移学习和规划背后的机制
通过对迁移学习和规划背后的认知原理的总结,揭示了对生物代理的学习和解决问题能力至关重要的三个重要机制,即成分感觉运动抽象、内在动机和心理模拟。
HRL架构的缺点和挑战
分层心理模拟需要稳定的分层表示和精确的预测
内在动机需要具有精细不确定性处理的前向模型
组合性需要精细的角色填充表示
推理拟合状态抽象需要强大的学习信号
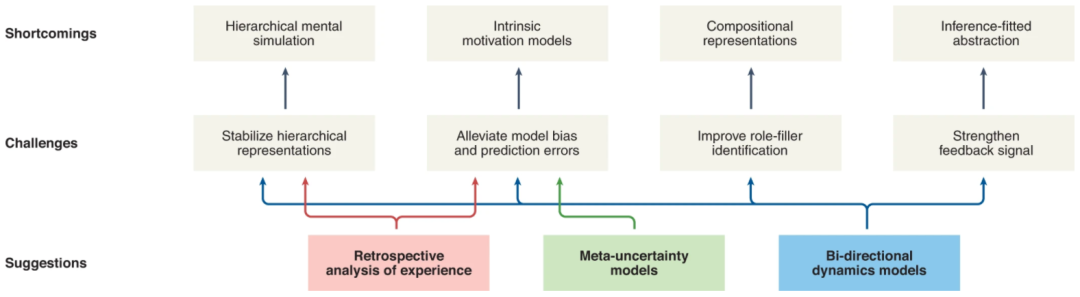
图示:HRL的不足、挑战和建议。(来源:论文)
应对挑战的展望和建议
经验回顾分析
HRL 的一个核心问题是,只有在较低级别的学习收敛后,才能出现稳定的高级表示。研究人员认为对经验进行回顾性分析可以缓解这个问题。通过事后学习来训练策略已经证明了这一点,其中策略的实现的世界状态被追溯地假装为期望的目标状态。
研究人员建议,后见之明是对记忆经验进行更一般的回顾性分析的一个特例。例如,事后也有可能学习分层前向模型,而高层不必等待低层收敛。这种技术也可能有助于减轻模型偏差。
元-不确定性模型
预测错误在心理模拟和内在动机中起着重要作用。研究人员讨论了自由能原理,它涉及建立在预测处理模型上的两个看似矛盾的机制。一方面是主动推理,旨在最大限度地减少长期意外。这可以通过最小化前向模型的不确定性或预测误差来实现。另一方面是主动学习,它寻求最大化信息增益。这可以通过各自的内在奖励函数最大化不确定性或预测误差来实现。
Schwartenbeck 团队通过建立预期的不确定性来统一这两种机制来解决这一矛盾。可以将预期的和意外的不确定性,理解为元-不确定性分析。
此外,关于前向模型不确定性的确定性可以导致改进的预测过程,这些过程意识到自己的局限性。
双向动力学模型
双向模型涉及前向和后向推理,研究人员认为这种组合有利于分层架构中的表示抽象。他们的假设基于 Pathak 和 Hafner 团队的工作,使用组合的正向和逆向模型以自我监督的方式生成潜在表示。双向模型在由抽象函数生成的潜在空间上运行。通过在潜在空间中同时执行逆向和反向预测,抽象函数获得了两个重要特征。
首先,潜在空间被去噪,因为只有潜在观察的可预测部分决定了前向和后向预测。其次,该方法是自我监督的,因此提供了比相对较弱的奖励信号更稳定的反馈信号。这减轻了预测误差并增强了整体学习信号。
结语
该团队概述了分层问题解决的认知基础,以及如何在当前的 HRL 架构中实现这些基础。
研究人员认为小样本解决问题是智能生物的终极能力,它们学会用尽可能少的试验来解决因果关系非微不足道的问题。作为他们的主要研究问题,该团队要求计算先决条件和机制,以便在智能动物的水平上解决人工计算代理的问题。
研究人员推断如果一种特定的机制对计算架构有用,那么它也可能对生物认知系统有益,反之亦然。通过这种方式,认知科学和人工智能相互启发,有望产生对人工智能和人类的未来有益的见解。
论文链接:https://www.nature.com/articles/s42256-021-00433-9
编辑:于腾凯
校对:杨学俊
















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









