







 Transformer模型因其高效的注意力机制在NLP任务中广泛应用,本文深入解析Transformer的架构,包括自注意力、多头注意力、位置编码等核心概念,并探讨其在序列处理中的优势。
Transformer模型因其高效的注意力机制在NLP任务中广泛应用,本文深入解析Transformer的架构,包括自注意力、多头注意力、位置编码等核心概念,并探讨其在序列处理中的优势。

作者:杨金珊审校:陈之炎
本文约4300字,建议阅读8分钟“Attention is all you need”一文在注意力机制的使用方面取得了很大的进步,对Transformer模型做出了重大改进。目前NLP任务中的最著名模型(例如GPT-2或BERT),均由几十个Transformer或它们的变体组成。
背景
减少顺序算力是扩展神经网络GPU、ByteNet和ConvS2S的基本目标,它们使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐含表示。在这些模型中,将来自两个任意输入或输出位置的信号关联起来,所需的操作数量随着位置距离的增加而增加,对于ConvS2S来说,二者是线性增长的;对于ByteNet来说,二者是对数增长的。这使得学习遥远位置之间的依赖关系变得更加困难。在Transformer中,将操作数量减少到一个恒定数值,这是以降低有效分辨率为代价的,因为需要对注意力权重位置做平均,多头注意力 (Multi-Head Attention)抵消了这一影响。
为什么需要transformer
在序列到序列的问题中,例如神经机器翻译,最初的建议是基于在编码器-解码器架构中使用循环神经网络(RNN)。这一架构在处理长序列时受到了很大的限制,当新元素被合并到序列中时,它们保留来自第一个元素的信息的能力就丧失了。在编码器中,每一步中的隐含状态都与输入句子中的某个单词相关联,通常是最邻近的那个单词。因此,如果解码器只访问解码器的最后一个隐含状态,它将丢失序列的第一个元素相关的信息。针对这一局限性,提出了注意力机制的概念。
与通常使用RNN时关注编码器的最后状态不同,在解码器的每一步中我们都关注编码器的所有状态,从而能够访问有关输入序列中所有元素的信息。这就是注意力所做的,它从整个序列中提取信息,即过去所有编码器状态的加权和,解码器为输出的每个元素赋予输入的某个元素更大的权重或重要性。从每一步中正确的输入元素中学习,以预测下一个输出元素。
但是这种方法仍然有一个重要的限制,每个序列必须一次处理一个元素。编码器和解码器都必须等到t-1步骤完成后才能处理第t-1步骤。因此,在处理庞大的语料库时,计算效率非常低。
什么是Transformer
Transformer是一种避免递归的模型架构,它完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。Transformer允许显著的并行化……Transformer是第一个完全依靠自注意力来计算输入和输出的表示,而不使用序列对齐的RNN或卷积的传导模型。

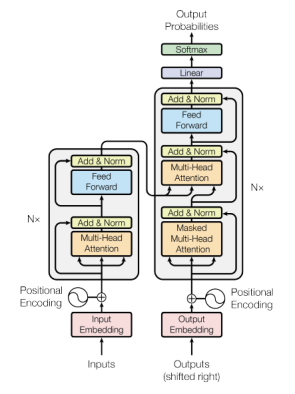
图1 Transformer 架构
从图1可以观察到,左边是一个编码器模型,右边是一个解码器模型。两者都包含一个重复N次的“一个注意力和一个前馈网络”的核心块。但为此,首先需要深入探讨一个核心概念:自注意力机制。
Self-Attention基本操作
Self-attention是一个序列到序列的操作:一个向量序列进去,一个向量序列出来。我们称它们为输入向量 ,
,  ,…,
,…, 和相应的输出向量
和相应的输出向量 ,
,  ,…,
,…, 。这些向量的维数都是k。要产生输出向量
。这些向量的维数都是k。要产生输出向量 ,Self-attention操作只需对所有输入向量取加权平均值,最简单的选择是点积。在我们的模型的Self-attention机制中,我们需要引入三个元素:查询、值和键(Queries, Values and Keys)。
,Self-attention操作只需对所有输入向量取加权平均值,最简单的选择是点积。在我们的模型的Self-attention机制中,我们需要引入三个元素:查询、值和键(Queries, Values and Keys)。
class SelfAttention(nn.Module):
def __init__(s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









