







本文约16000字,建议阅读20+分钟针对围绕LLM的洞察思考上,我们尝试通过在几个方面进行对LLM内涵的深入阐释。本篇文章与2023年底尝试挖掘并探寻以chatGPT为代表的LLM和以AlphaGO/AlphaZero及当下AlphaDev为代表的RL思想的背后底层理论及形式上的统一,同时与最近OpenAI暴露出的project Q*可能的关于细粒度过程学习再到系统①(快)思考与系统②(慢)思考的形式化统一的延展性思考,以展望并探索当下面向未来的AGI->ASI的路径可行性。正如前几日AI一姐李飞飞所说,人工智能即将迎来它的「牛顿时刻」
本篇文章拟分为「上篇」「中篇」「下篇」
作者:吕明,坐标西二旗,技术探索方向LLM/RL/AGI/AI4S..
「上篇」
AlphaDev的尝试
探索的开始,想以一个去年(23年)年中颇具戏剧性的两个事件为开端...
故事的背景和起因是这样的,自AlphaGO为AI制造的涟漪还在、ChatGPT为AIGC掀起了更大的浪潮之后,以及基于LLM之上Agent模式初露头角后,人们将目光更多的关注在如何使得AI在达到AGI之后迈向ASI,而ASI的其中一条印证路径就是超越人类实现AI4S的突破...直到我们在去年底OpenAI内部的一次乌龙事件,似乎暴露出了一些隐藏在其背后的野心和端倪..
Think:这里可以关联到Agent探索&体会中的一篇关于XOT的paper中MCTS DRL路径探寻的模式思考,其中AOT那篇paper中也有部分思想的重合与指导性。
回望23年中的6月7日,曾经在最复杂的智力博弈领域风光无限的DeepMind,继AlphaGO神来之笔后,在LLM风靡世界的冷静期(2023.2H,Gemini和SORA发布前夕),又将强化学习带向了巅峰,又双叒叕带着重磅成果登上Nature了..在计算机领域最基础的两个算法上实现了人类未发现的新突破:针对基础排序算法和哈希算法实现了汇编指令层的算法突破,分别提升70%及30%效率。而正是因为这一最新成果 · AlphaDev,使得十年都没有更新的LLVM标准C++库都更新了,并且数十亿人将会受益。
这个AI名叫AlphaDev,属于Alpha家族“新贵”,并且基于AlphaZero打造。DeepMind的研究员给它设计了一种单人“组装”游戏,如下图所示:
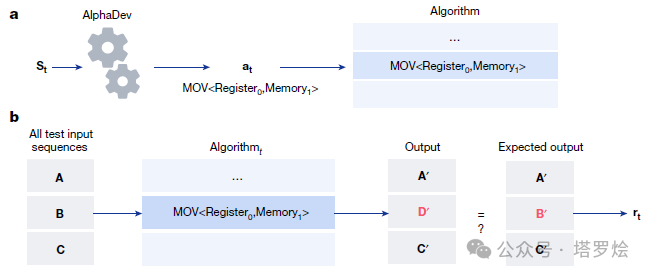
只要能够搜索并选择出合适的指令(下图A流程),正确且快速地排好数据(下图B流程),就能获得奖励。
其中,AlphaDev拥有两个核心组件:学习算法和表示函数。
学习算法主要是在强大的AlphaZero上扩展的,它可以结合DRL和随机搜索优化算法来进行巨量的指令搜索;主要的表示函数则基于Transformer,它能够抓住汇编程序的底层结构,并表示成特殊的序列。随着AlphaDev不断地打怪升级(在此过程中,研究员还会限制它能执行的步数,以及待排序列的长度),最终,AlphaDev发现了一种全新排序算法:
Think:这里可以关联到Agent探索&体会中的一篇关于XOT的paper中的MCTS DRL路径探寻的模式思考,其中AOT那篇paper中也有部分思想的重合。
具体的算法创新结果如下图所示:

如图所示:左边是利用了min(A,B,C)的原始sort3实现,右边是通过“AlphaDev Swap Move”,只需要min(A,B)的实现。能够发现可以省掉一步指令,还只需要算出A和B的最小值

如图所示,在对8个元素进行排序的算法中,AlphaDev也同样利用“AlphaDev Copy Move”,用max (B, min (A, C))替换了原始实现中更为复杂的max (B, min)
作者表示,这种新颖的方法让人想起当年AlphaGo的“第 37 步”——一种违反直觉的下法却直接击败传奇围棋选手李世石,让观众全都震惊不已,而在发现更快的排序算法后,作者也用AlphaDev试了试哈希算法,以此证明其通用性,结果也没有让人失望,AlphaDev在9-16字节的长度范围内也实现了30%的速度提升。如果序列较短,相比人类基准排序算法,它能将速度提高70%;如果序列长度超过25000个元素,则提高1.7%。
同时作者认为两种新算法的实现显示AlphaDev具有强大的发现原始解决方案的能力,并且将使我们进一步思考计算机领域基础形式化算法的改进方式。
不过在学术和产业界,针对此算法也有着诸多不同的声音与思考:
它计算的是算法延迟,而非传统意义上的时间复杂度。如果真算时间复杂度,数据可能不好看。
它改进的并不是排序本身,而是在现代CPU上做新的排序(特别是短序列)。这种操作其实不算罕见,比如FFTW、ATLAS这些库就是这么做的。
同意,他们只是为特定CPU找到了更快的机器优化,并不算发现新的排序算法,方法本身很酷,但还不算开创性研究...
接下来,围绕着AlphaDev等争论还未形成气候时,开头所讲的戏剧性的一幕发生了...DeepMind新AI登上Nature才一天,GPT-4就来打擂台了!具体GPT-4是通过两段提示内容,GPT-4就给出了和AlphaDev如出一辙的排序算法优化方法。
带来这个新发现的是一位来自威斯康星大学麦迪逊分校的副教授,名叫Dimitris Papailiopoulos。其两段提示内容分别为:
第一条:这有一段排序算法,我觉得它还能进一步优化。你能不能在下面几行,用*注明哪些指令可以删除或者改进?如果不需要修改,就什么都不动。一步一步解释原因,然后回去验证它是对的。同时还强调说,如果有什么新发现,先不要做改变,只是“看着”就好,写出来一些书面改进建议。
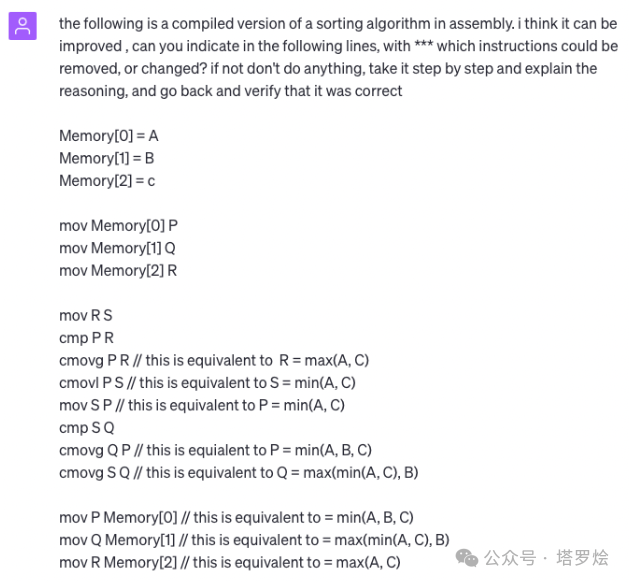
基于上述提示内容,GPT-4对代码做出了详细解释:

第二条:继续。如果你有很大的把握,按照上面的提示去做。Temperatur=0(让生成结果确定且一致),尽量简要避免混淆。
然后GPT-4给出了详细的步骤,最后总结说:
我们发现指令“mov S P”多余可以去掉,其他指令都是必需的。但在删除之后,应将P替换成S。
对比DeepMind新工作AlphaDev在处理同样问题上的思路,不能说毫无关系,只能说一模一样..
与此同时,跟昨日一样,在学术与互联网界,针对GPT-4这另一种推理方法,同样有着诸多争论与观点:
有人感慨说,Dimitris教授的操作进一步验证,只要有耐心、懂提示工程,GPT-4能做到的事还有很多。
也有人提出质疑,表示GPT-4能这么做会不会是因为它的训练数据中包含了一些排序算法的优化方法?
不过话说回来,之所以这件事能够引起这么大的关注和讨论,很大一部分原因是AlphaDev登上Nature存在争议。
不少人觉得这也不是什么开创性的研究,归咎于DeepMind的夸大其词。
当然也有人认为,AlphaDev本身的创新点更在于,它是利用强化学习来发现新算法的。
之所以会在两天内出现戏剧性一幕以及诸多争论和思考,一方面说明大家对AGI到ASI的期待与关注,另一方面,也体现出当前AI不管在以chatGPT为代表的序列自回归预训练LLM,还是之前以AlphaGO/AlphaZero及当下AlphaDev为代表的RL之中都会存在底层理论的缺失和形式上的统一。
Algorithm Distillation的启迪
在尝试进行针对上述以GPT4为代表的LLM序列预测框架及以Alpha家族包括GO/Zero/Dev及其它为代表的DRL框架两者间的深度剖解之前,在这里有必要多补充一些有关RL与LLM思想与方法融合的发展历史,以便我们能从更多角度广泛的了解RL与LLM,首先我们将目光聚焦在DeepMind于2022年秋天发布的一篇关于AD(算法蒸馏)的IN-CONTEXT RL方法,先拿他来拿拿味儿:)
2022年随着ChatGPT的火热,Transformer可谓是最强大的神经网络架构,大型预训练Transformer模型的泛化能力已经在多个领域得到验证,并且经过预训练的Transformer模型可以将prompt作为条件或上下文学习(in-context learning)适应不同的下游任务。
但是这里不得不要问一个看似更加深刻的问题:为什么当年同样大火的AlphaGO所采用的RL及后续RL的其它诸多变种中很少有采用预训练模型,又或者以ChatGPT为代表的LLM范式为何在其中看不到更多RL的影子?(ChatGPT在在aligning过程中虽然采用了一种RL的思想方法,即RLHF,但对于整个GPT架构来说亦非核心框架且没有起到主导作用,如对大量知识的压缩或学习主要还是位于pre-training阶段,RLHF仅仅在align的环境闭环中实现了R)
Think:这里可以思考一下:①LLM是否有必要次采用RL思想和方法吗?即便是采用了RL,会与之前的序列预测任务、训练模式、场景有何差异或特殊之处?RL的意义是?②序列预测模型是否可以运用RL的数据或思想,即在LLM模型推理过程中继承了某种类RL的推理过程?在后续的部分内容介绍中可能会对上述两个问题进行一定的阐释。
因此,从去年开始,已经有相关工作证明,通过将离线强化学习(offline RL)视为一个序列预测问题,那么模型就可以从离线数据中学习策略。但目前的方法要么是从不包含学习的数据中学习策略(如通过蒸馏固定的专家策略),要么是从包含学习的数据(如当前火热的Agent的过程历史)中学习,但由于其所收集的数据样本量、context长度、数据质量及任务&环境反馈模型等问题,以至于无法捕捉到策略提升。(PRM&Fine-Grained是基于什么思想?->这里暂且先栓个扣子)
尽管目前已经有很多成功的模型展示了Transformer如何在上下文中学习,但Transformer还没有被证明可以在上下文中强化学习。因此接下来可能探寻的思路方向为:为了适应新的任务,开发者要么需要手动指定一个提示,要么需要调整模型。如果Transformer可以适应强化学习,做到开箱即用岂不美哉?
随着研究的进一步探索,DeepMind的研究人员通过观察发现,原则上强化学习算法训练中所学习的顺序性(sequential nature)可以将强化学习过程本身建模为一个「因果序列预测问题」。具体来说,如果一个Transformer的上下文足够长到可以包含由于学习更新而产生的策略改进,那它应该不仅能够表示一个固定的策略,而且能够通过关注之前episodes的状态、行动和奖励表示为一个策略提升算子(policy improvement operator)。当然这里也给未来提供了一种技术上的可行性:即任何RL算法都可以通过模仿学习蒸馏成一个足够强大的序列模型,并将其转化为一个in-context RL算法。
基于此,DeepMind提出了算法蒸馏(Algorithm Distillation, AD) ,通过建立因果序列模型将强化学习算法提取到神经网络中。
其中来自OpenAISafety团队的负责人Lilian Weng也在不久前发布的那篇6000字的博客所述的AI Agent的COH思想也有提提及:将 CoH 的思想应用于强化学习任务中的跨集轨迹,其中算法被封装在长期历史条件策略中。由于 AI Agents 能够与环境多次进行交互,并不断进步,AD 连接这种学习历史记录并将其馈送到模型中。这样,就可以实现每一次的预测操作都比以前的试验带来更好的性能。AD 的目标是学习强化学习的过程,而不是训练特定于任务的策略本身。通过将算法封装在长期历史条件策略中,AD 可以捕获模型与环境交互的历史记录,从而使得模型能够更好地学习和改进自己的决策和行动,从而提高任务完成的效率和质量。
AD论文原文:2210.14215.pdf (arxiv.org)
AD论文摘要:文中提出了Algorithm Distillation (AD),这是一种通过因果序列模型对其训练历史进行建模,从而将强化学习(RL)算法蒸馏到神经网络中。Algorithm Distillation将强化学习作为跨episode的序列预测问题进行学习。学习历史的数据集由一个源RL算法生成,然后通过给定先前学习历史作为上下文,一个因果transformer通过自回归预测动作来进行训练。与post-learning或expert sequences的序列决策预测架构不同,AD能够在不更新其网络参数的情况下完全在上下文中改进其策略。文中证明,AD可以在各种具有稀疏奖赏,组合任务结构和基于像素观测的环境中进行强化学习,并发现AD能比生成源数据的方法学习到具有更高数据效率的RL算法。
本质上,其思想是将学习强化学习视为一个跨episode的序列预测问题,通过源RL算法生成一个学习历史数据集,然后根据学习历史作为上下文,通过自回归预测行为来训练Causal Transformer,其灵感来源于某些研究人员发现Transformer可以通过模仿学习从离线RL数据中学习单任务策略,这一灵感为提取通用的多任务策略提出了一个很有前景的范式:首先收集大量不同的环境互动数据集,然后通过序列建模从数据中提取一个策略。
于此同时,早在2021年,有研究人员首先发现Transformer可以通过模仿学习从离线RL数据中学习单任务策略,随后又被扩展为可以在同域和跨域设置中提取多任务策略。这些工作为提取通用的多任务策略提出了一个很有前景的范式:首先收集大量不同的环境互动数据集,然后通过序列建模从数据中提取一个策略,即 把通过模仿学习从离线RL数据中学习策略的方法也称之为离线策略蒸馏,或者简称为策略蒸馏(Policy Distillation, PD)。
尽管PD的思路非常简单,并且十分易于扩展。
但此种思想在某些训练任务及环境下也存在着一些直观上的天然局限性或者说是缺陷:生成的策略并没有从与环境的额外互动中得到提升。如文中所举实例:MultiGame Decision Transformer(MGDT)学习了一个可以玩大量Atari游戏的返回条件策略,而Gato通过上下文推断任务,学习了一个在不同环境中解决任务的策略,但这两种方法都不能通过试错来改进其策略。(这里可以思考一下AlphaGO)其中可能的假设原因为此种Policy Distillation不能通过试错来改进的原因是,它在没有显示学习进展的数据上进行训练,即Decision Transformers或者Gato只能从离线数据中学习策略,无法通过反复实验自动改进。
因此这篇论文中的AD算法通过优化一个RL算法的学习历史上的因果序列预测损失来学习内涵式策略改进算子的方法,其整体架构如下图所示:

AD包括两个组成部分:1. 通过保存一个RL算法在许多单独任务上的训练历史,生成一个大型的多任务数据集;2. 将Transformer使用前面的学习历史作为其背景对行动进行因果建模
Ⅰ:首先训练一个强化学习算法的多个副本来解决不同的任务和保存学习历史。
Ⅱ:一旦收集完学习历史的数据集,就可以训练一个Causal Transformer来预测之前的学习历史的行动。
由于策略在历史上有所改进,因此准确地预测行动将会迫使Transformer对策略提升进行建模,即 Transformer只是通过模仿动作来训练,没有像常见的强化学习模型所用的Q值,没有长的操作-动作-奖励序列,也没有像 DTs 那样的返回条件。换句话说,AD 可以提取任何 RL 算法,研究人员尝试了 UCB、DQNA2C,一个有趣的发现是,在上下文 RL 算法学习中,AD更有数据效率。前提是,AD需要一个足够长的历史,以进行有效的模型改进和identify任务。
同时算法蒸馏的实验表明,Transformer可以通过试错自主改善模型,并且不用更新权重,无需提示、也无需微调。单个Transformer可以收集自己的数据,并在新任务上将奖励最大化。
总结下来,研究人员得出以下结论:
Transformer可以在上下文中进行 RL;
带 AD 的上下文 RL 算法比基于梯度的源 RL 算法更有效;
AD提升了次优策略;
in-context强化学习产生于长上下文的模仿学习。
Think:本质上,AD的这种基于长上下文历史过程为Prompt Learning方式,将基于上下文的过程历史输入指引经“蒸馏”过的Causal Transformer进行多轮自回归序列预测,在对于更高复杂类或深度推理问题来看挑战非常大,如围棋问题中AlphaGO/Zero所面临的复杂场景,而AlphaGO/Zero在RL过程中的状态-行动-奖励亦会需要对其价值网络及策略网络中的参数进行反馈传递的,并在不断传递过程中持续迭代而产生更优着子策略(结果),其RL过程中的价值网络与策略网络的逐步迭代亦是一种DNN式的“蒸馏”,但其依然是输入->最优结果策略的推理模式,而未进行通过更多步骤将RL过程显现。因此,未来是否可以进而迈入Fine-Grained Learning的路径,同时在构造了足够理想的世界模型(这里指的是封闭域的世界模型,如数学世界或逻辑世界)下,采用序列预测LLM方法进行直接E2E的PRM反馈训练亦或者通过将类似MCTS等策略模型采用某种方式与序列预测模型进行融合迁移,并论证其将上述所述在世界模型中学习到的各种形式化知识进行迁移,以满足深度泛化能力的构建,并最终实现AI4S的突破。
上述的AD算法似乎是尝试通过基于Transformers的模型结构序列预测模型对RL过程中的Q-learning、RM、Policy等环节进行序列蒸馏,这不得不说是在某种视角下,将当前的LLM与之前的RL建立了某种联系,其目的是尝试将RL的过程、策略、价值压缩到了LLM中,间接的使得LLM掌握了采用RL方法习得的领域深度洞察。
Think:这里可以尝试思考一下LLM的序列预测预训练框架与RL有何本质的差异或同源?
栓个扣子:在这里是否有嗅到Meta Learning的味道了呢?
基于RL的AlphaGO/Zero再探究 → “LLM×RL”
结合上一篇“AlphaDev的尝试”与“Algorithm Distillation的启迪”两个章节内容的思想回顾,我们似乎看到在以泛GPT为代表的预训练自回归编码模型(即LLM)与泛Alpha系列为代表的RL之间存在着一些事情,像是幽灵鬼魅般的位于不同空间中的两个量子间的纠缠,又像是看似不同物种在沿着遗传轨迹向上追溯的过程。因此,为了更深入的探究两者之间的本质,希望还是通过深入一个历史上经典而又成熟的两个前后进化模型·AlphaGO/Zero来一探究竟。
在围棋这一古老的游戏中,AI的挑战如同星辰大海般辽阔。围棋的搜索空间巨大,棋面的好坏难以准确评估,这给AI带来了极大的困扰。然而,DeepMind团队却勇敢地迎接了这个挑战。他们提出了一种全新的方法,利用价值网络来评估棋面的优劣,再通过策略网络选择最佳落子。(AlphaZero仅使用单一网络来决策步数,不像AlphoGO采用双塔网络,但背后的RL思想是一致的)
其中,AlphaGO这两个网络的训练过程十分类似人类的思维模式。价值网络和策略网络均以人类高手的对弈数据以及AI自我博弈的数据为基础进行训练,就像我们小时候学习围棋一样,但对于起来来说,这种更硬核的训练方式使得这两个网络在围棋对弈中达到了蒙特卡洛树搜索的水平。但DeepMind并未满足于此。他们再次进行了创新,将这两个网络与蒙特卡洛树搜索有机地结合在一起,打破了原有的局限。这种思想,使得AI在围棋领域取得了前所未有的突破。不仅提升了AI在围棋领域的实力,更为未来的科技发展打开了新的篇章。
在具有完备信息的游戏中,都存在一个最优的价值函数,其能够在任何状态下逼近准确地预测游戏的最终胜负,同时基于胜负概率及当前状态,亦能准确的逼近下一步最优策略。这一思想基于穷举法,通过递归地展开游戏环境当中的策略树,拿围棋来说,可以精确计算出所有可能落子位置的胜率。然而,实际应用中,完全展开策略树是不现实的,因为其复杂度高达b^d,其中b表示游戏中可落子位置的数量,d则表示游戏的深度。在实际操作中,这种穷举法的计算量巨大,难以应对。因此,我们需要寻求更有效的算法来解决这个问题。
在对于如何绕过这个困难点上来说,可以适当借鉴人类的认识、评估客观事务的角度及思维:
减少搜索深度:通过位置评估的方式,对树的搜索进行截断。比如搜索到某个状态s,使用一个近似函数来预测当前价值,就不继续向下展开游戏树了。
减少搜索宽度:在某个状态下,不对所有的可以落子的位置进行搜索,而是通过落子位置采样的方式,也就减小了搜索宽度。落子的采样可以服从某一策略的分布。
而且,在人工智能的持续发展中,人们对于利用人工智能新算法解决挑战性问题一直抱有着初心,如AI4S或AGI到ASI,因此随着RL的持续发展,针对在某些领域的挑战突破上,其中的一条可行的路径也许是找到一个适合的模拟任务环境(这点非常重要,且需要有自反馈机制,如围棋)从白板状态开始训练、学习,而非借助人类专家先验,以达到人类或超过人类的状态。而不借助专家历史经验或数据也是考虑监督学习最终会达到一个天花板,且这个天花板就是所有已知标签化监督数据被纳入到训练集中用于模型训练并最终达到的顶峰。这不不光是RL在算法上的创新突破,更体现出其深远的价值与意义。
为了能更好的洞悉这种深远的价值预意义,这里希望能再与大家一起简单回顾一下RL算法的实现原理与创新思想,鉴于AlphaZero整体结构相对简单且E2E的融合了AlphaGO的两个价值与策略双塔网络,因此用AlphaZero举例说明:
下图是AlphaZero的模型公式描述:

AlphaZero的模型公式描述
定义一个神经网络 ∫θ;
其网络权重为θ;
当前的棋盘状态(加上过去的历史状态)表示为s;
网络根据棋盘状态的得出的输出为(p,v)= ∫θ(s);
其中p表示采用每一个围棋动作之后的概率pa=Pr(a|s);
v表示一个估计值,用来估测当前状态s下的胜率;
(其中这里的p与v可以理解对齐为Policy Network与Value Network的输出)
详细的训练方法如下图所示:

AlphaZero通过自我博弈的方式,运用RL思想进行网络 ∫θ的梯度学习,在棋盘状态s下,MCTS执行最优搜索,并输出一个当前步骤最优策略的动作概率π,即进行相比之前步骤反馈的更强大的策略改善操作(π是一个比原始的NN·∫θ的输出更优的一个监督信息),以运用监督学习训练。同时,在其中的每次监督学习过程中,通过MCTS持续的搜索执行,探寻Game Winner z,作为当前最优策略着子者并将其策略持续反馈,以最终实现 ∫θ的输出(p,v)= ∫θ(s)最大逼近MCTS(π,z),详细的MCTS所主导的探寻+训练机制如下图所示:
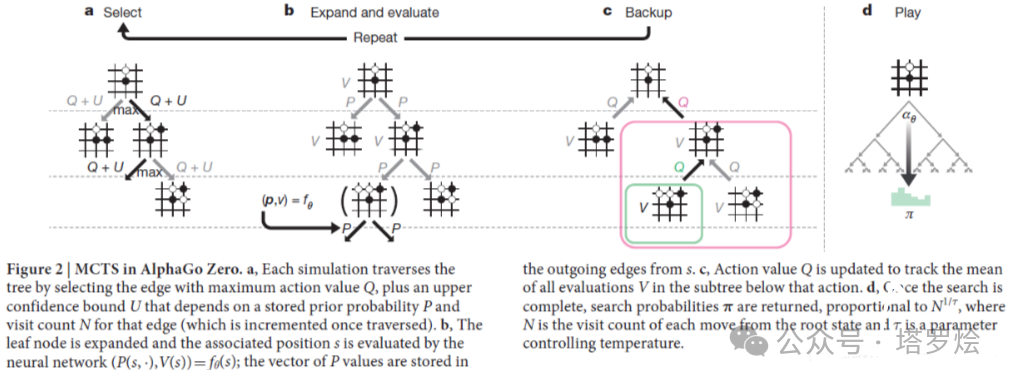
其中MCTS本质上在其中实现了两方面作用:通过∫θ的(p)来指导其路径(着子)探索,并使用其(v)输出代替传统的MC rollout算法。
对于其中的p与v,可以理解并对其为网络反馈学习中的Policy输出和Value输出,其训练过程中的损失函数亦对应Policy Loss和Value Loss:
Policy Loss:在预测的策略和从MCTS self-play过程中获得的策略目标之间计算交叉熵损失;
Value Loss:在游戏结束时使用价值分配获得的预测值和目标价值之间的均方损失。
在AlphaZero中训练NN的损失就是这两个损失之总和,合并称之为“AlphaLoss”。
其简单的走子示意及关联的模型训练过程如下图参考所示:
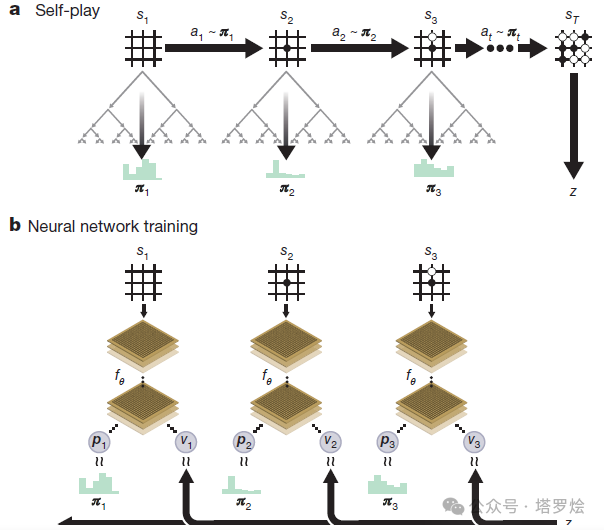
从上图中可看出,AlphaZero所采用的神经网络结构融合了AlphaGO的Policy Network和Value Network这两个网络,存在两个概率输出(p,v)。
具体的步骤为:
a.
首先,∫θ会初始化其网络参数θo,在每一次子迭代过程中,迭代次数被认为i>1,通过self着子的模拟环境就产生了。这样在每一个s时刻t下,MCTS算法会被执行:
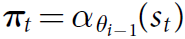
其中MCTS运用的算法是i-1迭代时候的网络∫θi-1,从而获得该时刻t下的棋盘着子可能性πt。
b.
在这里,可以看出:MCTS运用前一次迭代的∫θi-1来搜索着子策略,并将得到的这一次迭代的∫θi的训练信息。因此,MCTS通过搜索相应的策略达到∫θ的棋力提升,并用提升后的棋力着子策略作为新的训练信息反馈到∫θ中,从而保证其持续的提升(RL思想),以最终达到网络的收敛。
当MCTS搜索的着子策略search value低于某个阈值的时候,或者棋局大于某一长度的时候,该场对局会被给出一个最终reward:
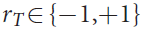
Mark:AlphaZero的self-play过程,对于RL框架来说,其得到的唯一Reward实在游戏结束时,因此在整个过程中所获得的奖励非常少,而我们的Value Network专注于预测Reward,如果我们想要完善Value训练即缩小ValueLoss,就需要增加AlphaZero的self-play次数;如果我们想提高Policy training,则可以关注更多MC回放。
此前每一时刻t的步数都着子路径都会被记录下来:
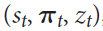
在监督信息与loss function上,网络的权重θi会采用上面MCTS所得到的记录信息进行训练,然后∫θ则期望尽量让p去逼近π,v逼近z,则使用先前步骤的信息来作为监督信息以更新网络权重:
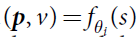
相应的loss指为最小均方值误差和交叉熵,如下:
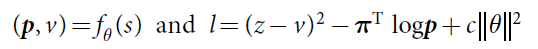
通过上述内容简单回顾了一下AlphaZero的RL训练思想与过程后,可以尝试在其中提炼出一些关键要素:
Self-play
MCTS
Policy Network & Value Network
Loss Function
Reward
Process
State > Action
一方面,这些关键要素可以帮助我们全局性的掌握以AlphaGO/Zero为代表的RL的整体框架思想,另一方面,也可以帮助我们看清RL在某些方面的内涵本质,并在接下来的章节中,我们将一步步剖析这些要素的同时,结合LLM序列模型或其他模型在训练、推理及所采用的数据模态及模式上进行更加深刻的关联性本质洞察。
另外,为了能够更加平滑的将思考路径引入到下一章节,在这里,想举一个LLM×RL的例子作为承上启下:
Think:其实ChatGPT预训练本身即是某种程度的LLM+RL,即在RLHF过程中,但出于RLHF对于大众认知的普遍性,并在其过程中RL过程的中体现出的Aligning的通用性以及RLHF作为LLM在整体训练过程中的其中一环,其初衷还是以任务为导向的人类偏好对齐,因此从思维惯性上来说这里对RL的运用更多具有一定的目标性且由于没有采用类似AlphaGO一种更加彻底的self-play博弈过程,包括在RL过程中所采用的RM在Reinforcement程度上缺少明确目标标准。而接下来的例子,虽说亦属于在LLM过程中采用RL思想来进行Synthetic Data的SFT,但在其中引入了self-play的方法,可以说从另一个角度,将RL中的self-play核心过程引入到LLM的SFT中,在SFT训练过程中弥补真实世界数据样本的充分性、全面性、深刻性、洞察性。
例子即来自于“arxiv.org/pdf/2401.00565.pdf”文章中介绍的一篇来自Google Research与Google DeepMind在2024年1月新出炉的一篇会话式医疗诊断人工智能应用AMIE“Towards Conversational Diagnostic AI”的论文。

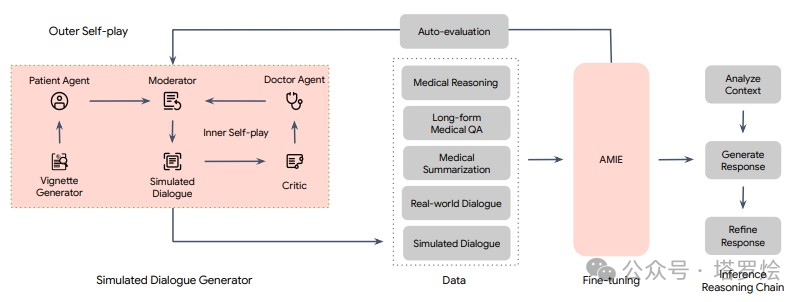
论文部分核心概念简述:
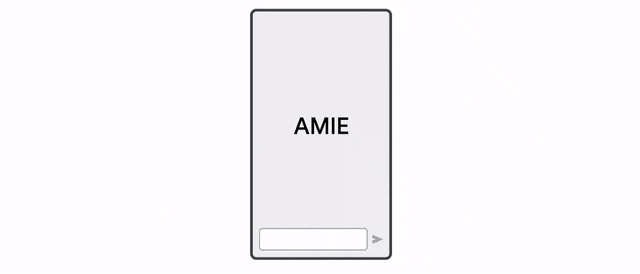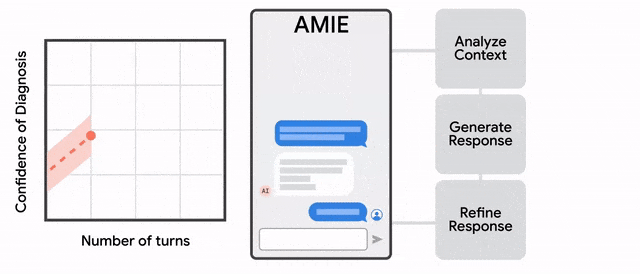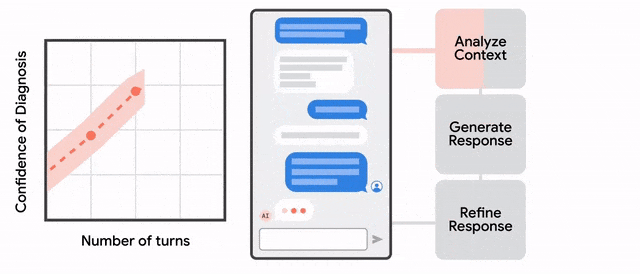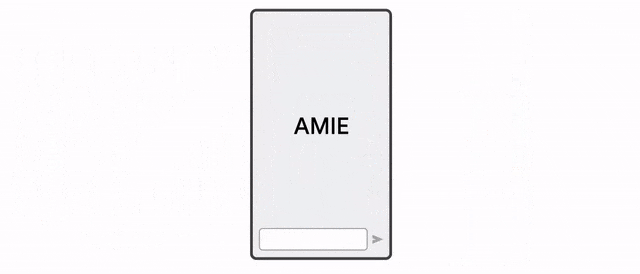
AMIE采用了一种强化学习算法中「自我博弈-self-play」方法,可以在一个模拟环境中自我对弈,并通过自动反馈机制,可在各种疾病、医学专科和环境中进行扩展学习。
本篇论文采用基于LLM的对话式诊断研究的角度尝试对对话式基础模型进行深度SFT的探索可能,同时在此之前,作者首先是考虑到当前用于临床诊断真实世界数据精调AMIE上可能存在的两项挑战:①真实世界数据对于大量复杂的医疗场景和真实条件捕捉的局限性,这可能阻碍了用于模型精调的数据集的局限性;②真实世界数据往往的病历质量是堪忧的,各种形式的噪声(口语化、表达风格、行为习惯..)。因此作者尝试构建一种自反馈的模拟环境(Multi-Agent思想),以扩展诊疗交互过程中可能出现的多种医疗条件和环境所隐含的数据和知识边界。这里感觉在数据结果上类似RLAIF,或者说是一种领域场景化的Self-RLAIF..
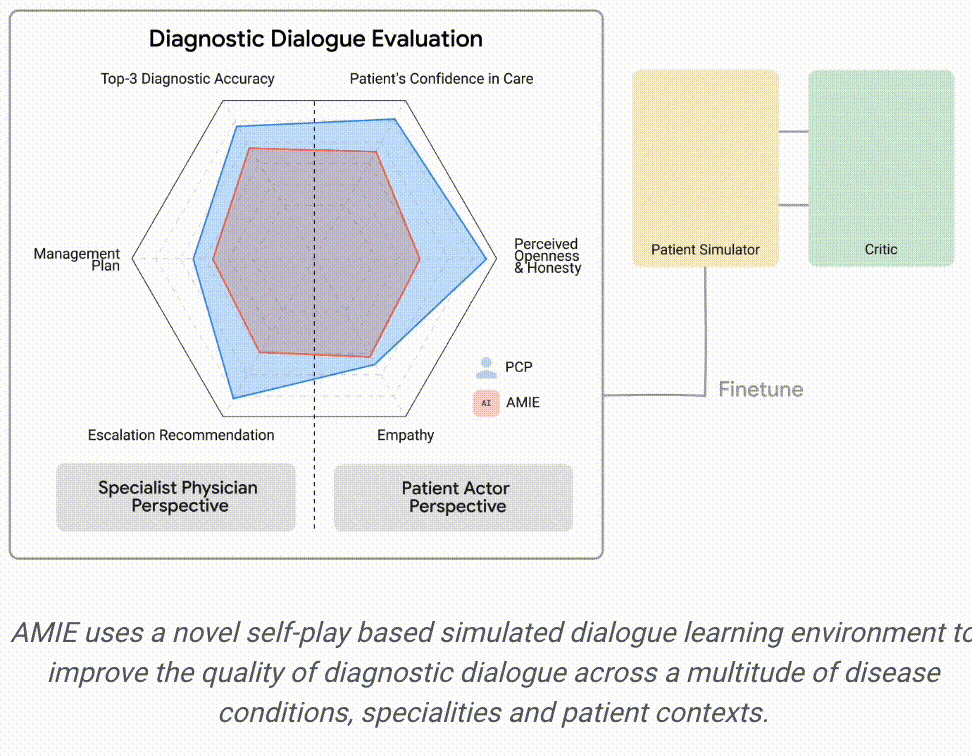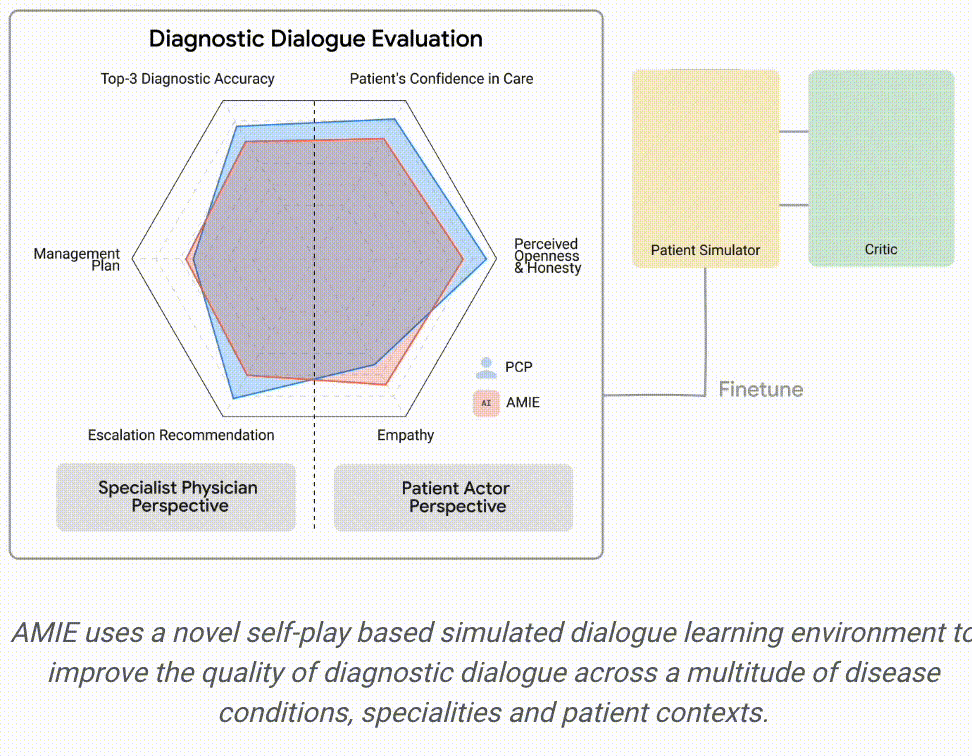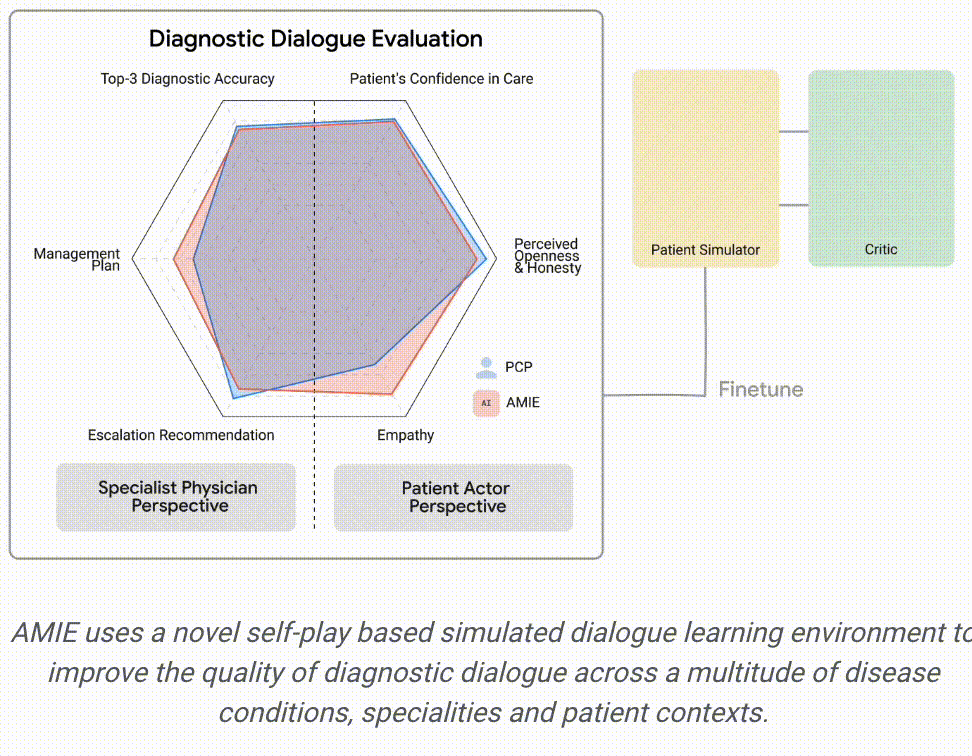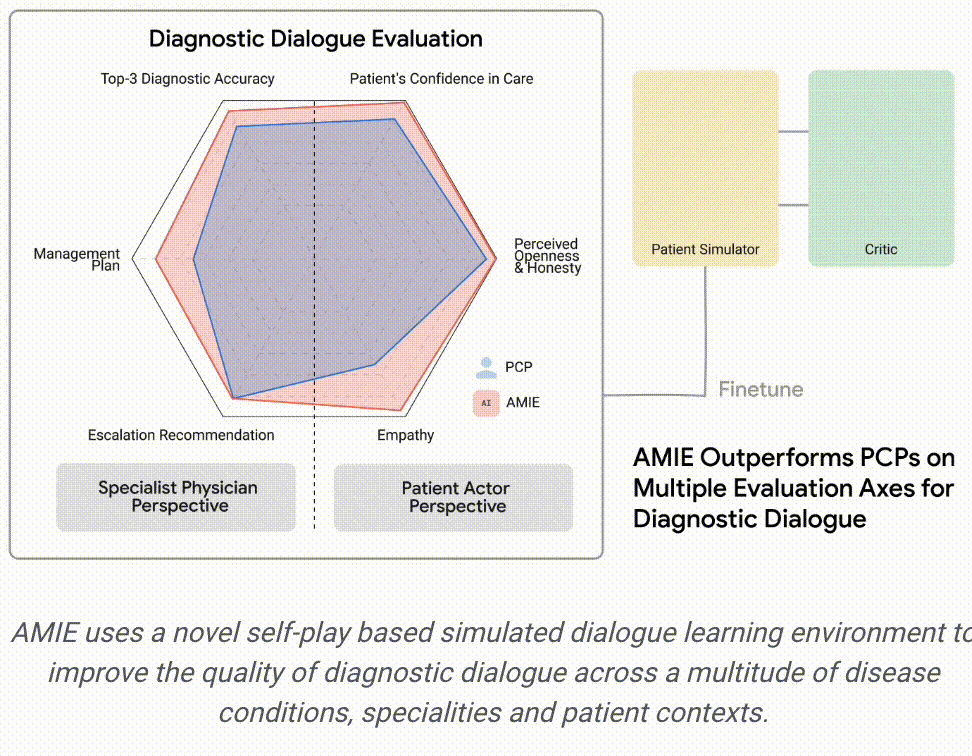
因此,基于上述框架思想,对应的训练机制采用了两层自循环过程:①「内部」自演循环,即AMIE利用上下文中批评者的反馈来完善其与人工智能患者模拟器进行模拟对话的行为;②「外部」自演循环,即完善的模拟对话集被纳入后续的微调迭代中;由此产生的新版AMIE可以再次参与内循环,形成良性的持续学习循环。
在推理方面,采用了推理时间链策略( inference time chain-of-reasoning strategy),使AMIE能够根据当前对话的情况逐步完善自己的回答,从而得出有理有据的答复。即某种Dialog-o-T。
探索性深度思考:
在AMIE整体学习训练过程中,针对其中的self-play环节即「内部」自演循环过程,对于整篇文章起到了核心的创新与价值意义,正如论文中所提及的由于采用真实世界数据的局限性,使得模型在SFT过程中会存在对广泛知识的学习以及模式识别泛化能力的缺乏,因此采用这种self-play自演循环的方法所实现的Synthetic Data以便可以较大程度解决上述问题。除了论文所解决的上述表象问题之外,我们不妨将Self-Play或Synthetic Data位于整个模型针对整个医学知识空间的SFT过程的内涵和意义再进行一番深入的探索与再理解。
相关Self-Play的内容也可参考如下两篇文章:(读者可自行搜索)
Scaling Law 的业内争议与讨论
My AI Timelines Have Sped Up (Again)
首先我们从Self-Play或Synthetic Data本身的意义上尝试进行一下思考的延展,这里由于Synthetic Data本身是建立在Self-Play的机制之上形成的,而Synthetic Data有很多种途径(RLAIF方法中的AI Generate与AI feedback即是其中一种途径),其中Self-Play即是一种看似带有目标场景性的数据生成途径,这个目标场景即是Self-Play中所处的带有一定目标性的模拟环境。而Synthetic Data最终会在后续过程中用于AMIE模型的Fine-Tuning。而为了更深入的理解Fine-Tuning的意义,则需要一步步回溯到合成的数据意义再到如何合成的数据,即数据的合成目标所带来的合成数据对整个模型用于模拟环境中的医学知识与能力空间Fine-Tuning的价值与意义。因此接下来我们将目标聚焦在核心的Self-Play之上。
在本篇论文中,Self-Play采用了类似Multi-Agent的思想,包括Patient Agent、Doctor Agent、Critic以及Moderator等角色,在整个自循环self-play过程中,我们发现经过多角色交互过程,在数据层面会合成扩展更多围绕诊疗环境的多种医疗条件和医学要素,而这些复杂的条件和要素又会作为模型非原始信息作为输入通过多角色进行进一步的模型生成、决策、反思或评判,是的,这里的关键就是这些「合成扩展的非原始信息作为输入 即 上下文提示」,它将在一步步的推理链条中将模型按照规定的情景引导至最终更标准、精确、更高泛化性的结果之上,而最终将模拟的对话结果用于模型的Fine-Tuning当中来,以保证对模型结果输出的正确性。这里可能大家会问,为什么需要如此繁琐的过程来合成数据呢?LLM自己不能直接在推理中解决问题吗?难道在采用大量的数据LLM预训练过程中并没有见到过这些数据?如果没见到,为什么模型还能通过在多角色的交互中合成出来?如果见到了这些数据,为什么还需要SFT,为什么还需要Multi-Agent、COT、TOT这一过程?当然要要完全回答上述这些问题,可能需要对LLM的预训练机制和原理进行展开和剖析,在了解了其训练本质后,也许会逐步找到解决上述疑问的办法。
在这里尝试再进行一些延申,试想一下,在LLM预训练过程中真实世界数据样本是真正足够的吗?与某个领域的任务对应的真实世界数据样本的组织和分布是合理的吗?即用于LLM pre-training的人类认知下的训练样本空间的「token」序列组织形态是天然COT的吗?LLM在预训练过程中所预测的下一个token学会的是什么?预训练时是否能够覆盖空间所有的复杂情况?模型提示词工程 Prompt Engineering与模型参数的Fine-Tuning的本质普遍性?基于Multi-Agent环境下,是否能达成类AlphaGO这样的self-play博弈环境的学习?等等这一系列问题似乎将会将我们带入到一个更本质的探寻空间。
在进行上述问题思考和探寻的过程中,刚好也联想到去年了解到的Mistral 7B,而由Mistral 7B也进一步了解到基于其微调的Zephyr 7B论文中的AIF+DPO(不同于RLHF PPO的算法)算法的思考,包括从Anthropic的RLHF到Cluade的RAILF,。在这里除了让大众眼前一亮的DPO算法(DPO利用从奖励行数到最优策略的解析映射,使得将奖励函数上的偏好损失函数转换为策略上的损失函数)之外,我想在AIF这一环节所带来的意义也是非常重大的。
在Zephyr中,如下图所示,其三步骤的训练方式与chatGPT的三阶段训练方式有着看似较大的差异:
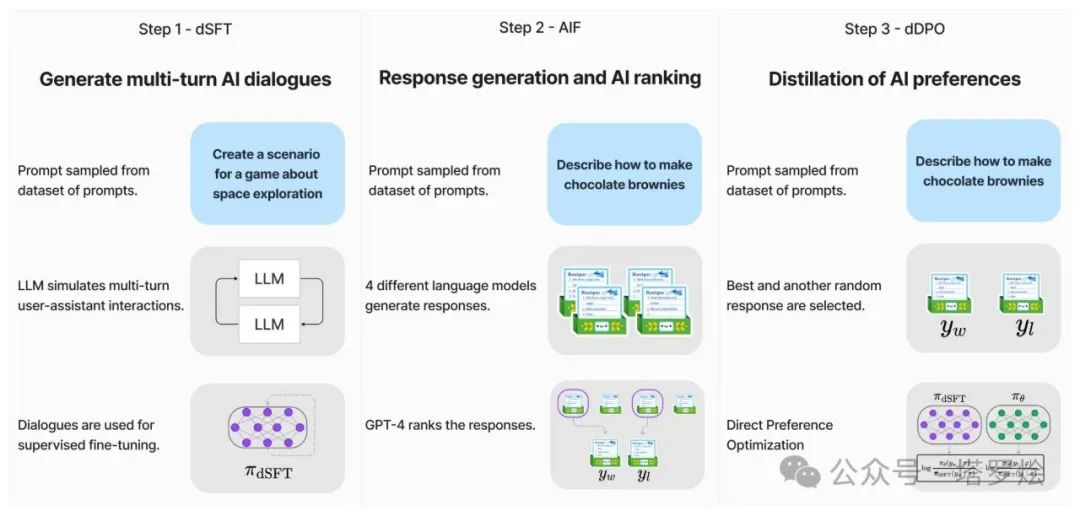
Step1 - sSFT:通过大规模、自指导式数据集(UltraChat)做精炼的监督微调(dSFT)。
Step2 - AIF:通过集成收集AI反馈(AIF)聊天模型完成情况,然后通过GPT-4(UltraFeedback)进行评分并二值化为偏好。
Step3 - dDPO:利用反馈数据对dSFT模型进行直接偏好优化·DPO。
其中这里的Step2 - AIF,即某种程度上的一种self-play,也是通过多模型prompt生成来进行的一种RL,试想,通过其中的AIF,对于模型最终所采用的DPO算法的SFT过程里,其用于最终模型的SFT所训练的AIF数据集在与原始pre-training数据集在数据(tokens)序列组织构象上应该有着一些差异,而这种差异是之前原始数据集在用于模型pre-training中很难找到的,而这也是一种Synthetic Data的路径,关键是这种Synthetic Data与原始Data上述中的那些特征与知识分布差异。
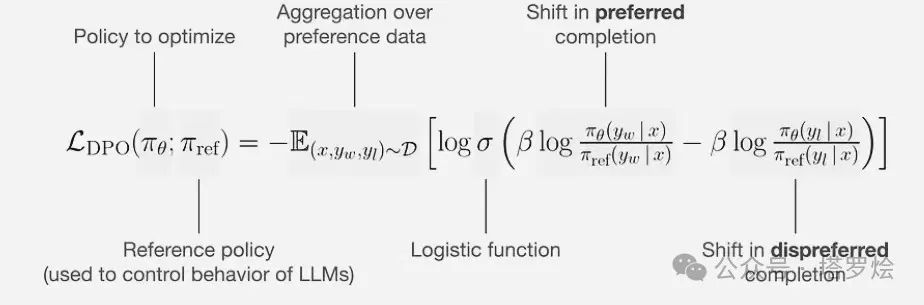
DPO算法:如下公式的解析通俗来讲就是:当一个答案是好的答案时,模型要尽可能增大其被策略模型生成的概率,而当一个答案是差的答案时,模型则需要尽可能降低其被策略模型生成的概率。

以上,我们在RL×LLM上开了一个小头,了解到了一些两种算法或训练模式的融合例子,并尝试做出了一些探索性思考,接下来,将上述模型case以及延展的思考进行一下沉淀,回归第一性原理进行更进一步的本质探寻,以求找到两者之间所隐含的的共性、差异以及之所以呈现出当前技术发展路径与现状的必然性。
回归第一性原理
接下来将着重尝试阐释LLM与上述介绍的RL两种模型算法亦或训练思想的Uniqueness和Universality,也许有人会认为LLM与RL并不适合并列放在一起对比(一个是模型,一个是方法或思想),这在接下来的内容论述中会向大家进行解释,这里姑且把两者都作为一种模型训练思想+推理模式+所涉及的用于模型训练的真实世界数据组成、函数及工程的方法来统一看待。
LLM洞察&阐释:
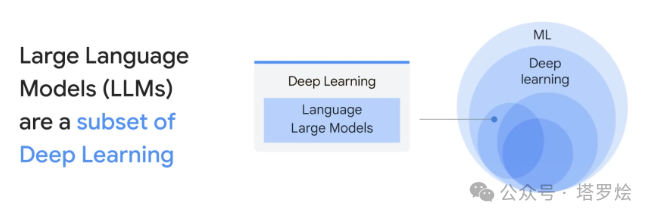
LLM大家都已经再熟知不过了,为了承上启下,这里针对LLM再做一些简单的概念以及自认为一些关键内涵的回顾。从概念分类角度上看,大语言模型是深度学习的分支。其中:
机器学习是人工智能(AI)的一个子领域,它的核心是让计算机系统能够通过对数据的学习来提高性能。在机器学习中,我们不是直接编程告诉计算机如何完成任务,而是提供大量的数据,让机器通过数据找出隐藏的模式或规律,然后用这些规律来预测新的、未知的数据。
深度学习是机器学习的一个子领域,它尝试模拟人脑的工作方式,创建所谓的人工神经网络来处理数据。这些神经网络包含多个处理层,因此被称为“深度”学习。深度学习模型能够学习和表示大量复杂的模式,这使它们在诸如图像识别、语音识别和自然语言处理等任务中非常有效。
大语言模型是深度学习的应用之一,尤其在自然语言处理(NLP)领域。这些模型的目标是理解和生成人类语言。为了实现这个目标,模型需要在大量文本数据上进行训练,以学习语言的各种模式和结构。如 ChatGPT,文心一言,就是一个大语言模型的例子。被训练来理解和生成人类语言,以便进行有效的对话和解答各种问题。如下图所示中LLM与ML、DL的关系:
同时,LLM还有一个可以说独有的特点,即生成式AI,这也是区别与其它传统模型或训练任务的Uniqueness,表面上看,这种技术包括用于生成文本、图像、音频和视频等各种类型的内容的模型,其关键特性是,它不仅可以理解和分析数据,还可以创造新的、独特的输出,这些输出是从学习的数据模式中派生出来的。
Think:这里可以稍微停下来思考一下生成式模型和判别式模型在底层模式的普遍性和差异性。在这里,个人认为“生成式”的核心之一在于采用了更高效的token化,而language亦或是code作为token化的承载媒介,是人类认知推理、链接物理世界、抽象化表达的最重要且涵盖范围十分广泛的概念化空间。而某种程度上,判别式模型在“判别侧”即模型输出“Y”侧对于生成式模型来说亦属于其子集(其实不光是“Y”,模型输入“X”侧且任务本身亦属于其子集--这里指的是用于模型推理过程的某种信息变换X→Y的整体模式),因此也就为大多数人所认为的LLM会取代或替代传统模型提供了理论的可能,即人们常说的:Token is all you need!--- 相比于之前的“Attention is all you need”,感觉Token化的意义会更大:Attention为AI打开了一扇通往对复杂世界理解的一扇门,Token化则是在在通过这扇门后对于未知世界迈出的第一步,对于视觉领域,结合OpenAI最近所发布的sora中所采用的一项创新,即“Patches”,就像Token一样将多种模态符号表示(代码语言、数学形式语言、自然语言)统一起来一样,sora采用将视觉数据压缩到低维的潜空间,然后表示分解为时空patches,从而实现了将像素级视觉数据降维转换为patches,即在这个“压缩”后的空间中接受训练,而后再利用扩展模型生成连续的像素级视觉数据(视频)---这里应该是openAI在sora中形式化训练了一个解码器模型,从而将生成的潜在表示映射回像素空间。
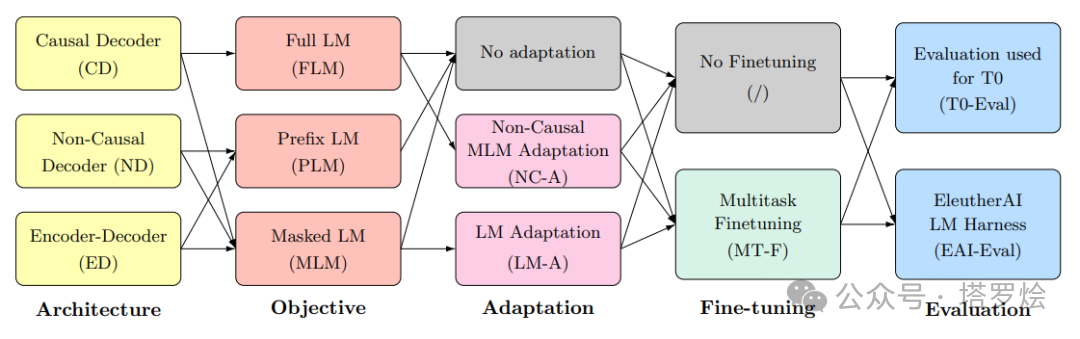
在模型架构及训练模式方面,以chatGPT为代表的大多数LLMs均是基于Transformer的序列预测/生成式模型架构,其中,LLMs之间会存在编/解码方式、训练任务目标等不同的差异性,如下图所示,这里需要指出的是:上述提及的“模型架构”更多是包含了广义上的一些理解,包含模型的网络拓扑结构(全连接/CNN/LSTM/Transformer/GCN..)及其中所蕴含的那些数学变换方法或思想、不同任务的学习目标及对应采用的损失函数,梯度策略等。针对生成式架构,亦包含诸如多模态视觉模型中采用的变分自编码器、掩蔽自编码器、去噪自编码器及LeCun提出的JEPA(联合嵌入预测架构)甚至最近OpenAI刚刚发布不久的sora所采用的扩散模型及其他诸如生成对抗网络等。
除了上述向大家所阐释的LLMs的token化生成式推理模式以及对应的模型架构的两个关键内涵之外,接下来想再跟各位读者一起分享探讨一下大模型(LLM)中的「In-Context Learning」这一概念和意义-不光局限于LLM本身的意义,甚至将「In-Context Learning」这一概念更广泛的延展到模型任务推理以及模型训练的普遍而深远的意义之上。之所以要将目光聚焦到「In-Context Learning」这一概念,主要原因更多是由于在LLM中Context对于模型训练任务过程中所采用的训练思想,模型推理过程中的few-shot和zero-shot以及带来的prompt learning&prompt engineering等一系列思想有着深刻的内涵联系。
Think:如果上述所提及的token化是针对于整个模型任务的输出侧的一种普遍适应性的创新,那么Context所涉及的上述一系列内涵思想则代表了对于模型任务输入侧的一种普遍适应性的创新。这里的“普遍适应性”则代表了模型处理广泛而普遍任务的一种泛化能力,同时利用上下文所实现的一系列x-shot或prompt engineering似乎与模型本身参数的Tuning又有着些许隐含的关联,或者在某些层面上两者有着本质的同一性。
在探索「In-Context Learning」这看似神秘和诡异的现象前,希望能先从几个问题入手,尝试从问题出发,逐步剥开其中的奇妙内涵。
在ChatGPT于2022年10月正式发布前,围绕语言模型的「In-Context Learning」「few-shot」「zero-shot」「prompt engineering」等思想已经有很多研究论文涌现出来,不同于传统判别式推理模型,其更多的提示场景用于解决生成式推理任务,而这种生成式推理任务场景似乎又与Prompt-Learning这种模型基于Prompt的训练、推理方式又有着某种天然的匹配与契合性。然而随着ChatGPT发布后为人们所带来的惊艳以及席卷全球的火爆热度之余,相当一部分AI研究者也将目光从这种惊艳与热点上缓缓移开,回归到冷静的思考,并结合之前自身所在的AI研究领域所进行的一系列技术路径的尝试及研究成果与ChatGPT在任务性能、任务类型、任务扩展、任务范围、训练思想、模型结构等维度进行反思与探寻,以寻求在技术与方法本身在底层逻辑上实现一定的对齐与自洽。
问题一:为什么「In-Context Learning」或相关的「few-shot」「zero-shot」「prompt e与gineering」等思想能打破传统训练范式并建立新的技术路径进行模型下游任务的SFT,而不用在调整模型任何参数的情况下,在实现传统模型精调后的目标及Benchmark测试中,已经媲美或超越相当一部分的原有模型微调任务的SOTA(当然这里离不开LLM所采用的海量训练数据Pre-training下习得、压缩的广泛而通用知识)。
问题二:LLM与传统模型的任务有哪些差异和相同的点?
问题三:是否所有传统模型下的任务都能很好的尝试用LLM来有效解决?
针对问题一,在学术界和产业界一直有着相关理论上探讨和争论:
如在推理阶段,研究人员专注于基于给定的演示来分析In-Context Learning-ICL能力是如何运行的,因为不涉及显式学习和参数更新,通常从梯度下降的角度进行分析,并将ICL视为隐式微调。在这个思想框架下,ICL过程可解释如下:通过前向计算,LLM生成关于演示的元梯度,并通过注意力机制隐式地执行梯度下降。实验也表明,LLM中的某些注意力头能够执行与任务无关的原子操作(例如复制和前缀匹配),这与ICL能力密切相关。
为了进一步探索ICL的工作机制,一些研究将ICL等效地抽象为一个算法学习过程。具体而言,LLM在预训练期间基本上通过其参数对隐式模型进行编码,通过ICL中提供的样例,LLM可实现诸如梯度下降之类的学习算法,或者直接计算闭式解,以在前向计算期间实现对模型的等效更新。在这个解释框架下,已经表明LLM基于ICL可以有效地学习简单的线性函数,甚至可以使用ICL学习一些复杂的函数,如决策树。
因此,在LLM在进行训练过程中,通过学习到的大量“Concept”,掌握了诸多与Concept相关的多种多样文本级别的潜在变量,使得Concept结合非常多的潜在变量指定了文本语义的方方面面,在推理过程中,学者猜测LLM通过本身所具备的学习能力,在进行ICL过程中“借鉴”到其中的隐含的Concept,等效于隐式的对自身进行了精调。
而要搞清楚问题一的本质,可能要将问题二和问题三一起联系起来进行分析和探寻,这里尝试给出笔者自己的一些片面的考虑:
对于任何一个模型来说,其核心要素除了包含模型的参数之外、还包含模型的输入(X)、输出(Y)以及所涉及的任务本身,而这里的「任务」对于模型的输入(X)、输出(Y)及对应的模型参数有着多样化的在可变空间的组合(这里把模型所涉及的输入(X)、输出(Y)及对应的模型参数进行概念形式化要素的定义),而不同的组合则依托于模型在前向&反向传播过程中底层形式各样的数学变换(变换的是特征空间里的特征映射亦或概念空间中的概念映射),而多样化的数学变换又与模型本身的结构(这里指DNN/CNN/Transformer..)及多种目标函数的类型息息相关。这里用一张较抽象的示意图将LLM与传统模型进行相对直观对比说明:
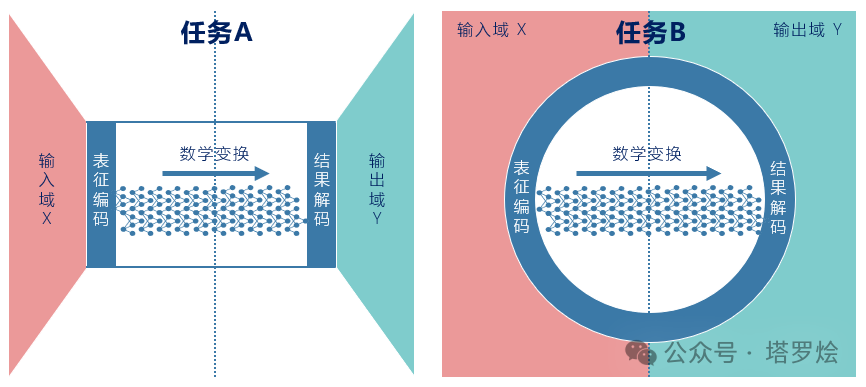
如上图所示,任务A对应与传统DL或ML,任务B对应LLM模型,两者最大的差异在于在输入域与输出域的表征空间上两者的拓扑结构上的差异。
对于传统模型对应的任务A来说:其输入域的表征编码空间与输出域的表征解码空间是完全独立且闭集的,因此,可以理解输入域的表征编码空间对于输出域的表征编码空间来说对于任务的目标函数具备某种固定模式映射规律,而这种「固定模式」直觉上(暂未找到一种合适的数学描述来衡量这种抽象概念与量)则更多会受到来自模型中参数的影响。同时,由于模型参数的大小有一定的局限性,因此在此种任务模式下,针对模型进行参数精调训练将会变得更加行之有效。
对于LLM对应的生成式任务B来说:与之对应的输入域的表征编码空间与输出域的表征解码空间均是前文所说的Token化的,且Token集合域处于统一符号空间(语言符号化表征或Sora的Patches化表征),因此模型在进行前向传播推理过程中,直觉上与之对应的模式是非固化的(这里同样由于无法找到一种适合的理论描述来论述这种抽象概念与量),而正式由于这种非固化的数学变换式推理过程中,除了需要更大的模型参数来压缩特征或语义应对这种推理模式外,亦为模型输入侧X提供了推理作用空间变换的权重。而对于模型本身的网络结构来说,这种输入域的表征编码空间与输出域的表征解码空间的全局Token化,也为模型的通用性及推理深度(如系统2中的COT、TOT等)提供了潜在空间。
因此,在得到针对上述两种任务所对应的两种模型来说,通过分析其两者之间的模式差异后,我们不难发现两者之间隐含着某些共性的东西,比如输入域表征与模型参数对于模型任务的推理(本质上是某种形式的数学变换)从底层数学变换的角度来看其本质是相同的,看似的表象上的差异则是这两者之间数学变化的复杂程度及与之对应的模型结构的复杂性的区别。
在上述针对围绕LLM的洞察思考上,我们尝试通过在几个方面进行对LLM内涵的深入阐释,包括:Token化、In-Context Learning、模型编码结构及推理空间等维度,希望通过这样的阐释,能帮助我们更好的找到LLM与传统DDL或RL本质上的统一 - 这也是我们采用回归第一性原理的思考方法所做出的一小步尝试,也为我们将探索进一步扩展到基于LLM×RL进行「世界模型」和「系统二思考」的探索上铺设了一些基础。
以上本篇文章「上篇」完结。
「中篇」将涵盖以下内容:
LLM×RL本质&阐释;
系统二思考的本质&阐释;
世界模型的内涵;
AGI到ASI通过AI4S的路径探索。
「下篇」
盘道了辣么多,本篇的目的是什么?
探究以泛GPT为代表的预训练自回归编码模型(即LLM)与泛Alpha系列为代表的RL的本质普遍性及表象差异性,以及为什么要将其两者联系起来?
鉴于LLM与RL两者间的差异化能力考量,业内不少的思路尝试将两种方法结合在一起,但结合后要么看着不是很巧妙,要不就是看起来很僵硬,总感觉像是一个过渡性的结合,并且看起来并没有以终为始,也不是原生的思想与方法的融合,因此想要尝试探寻一下两种学习方法是否能更巧妙的相互结合与统一。
探究思维系统的两种推理模式:系统Ⅰ(快系统)和系统Ⅱ(慢系统)在推理过程的本质普遍性及表象差异性,以及快慢思考是否与两类学习方法(LLM/RL)存在着某种关联?Agent在其中的内涵与定位是什么?
Prompt对于LLM来说其意义是什么,Prompt Learning给我们的更深一层的提示是什么?Meta Learning又是什么鬼?
模型中知识或模式的迁移及泛化能力代表了什么?
LLM的路径能达到一个真正意义上的世界模型WM并成为AGI甚至是ASI吗?WHY?HOW?
AI4S是否能带来科学突破?不光是改变研究范式,甚至是触达到探索知识的另一片天空之城?
将在「下篇」进行持续更新..敬请期待。
精神的助产士 · 苏格拉底的追问模式
苏格拉底式的交互式prompt给出的模型持续探索的意义..

华人数学家陶哲轩在天空之城的探索模式

KeyPoint:
陶哲轩成功应用AI工具形式化多项式Freiman-Ruzsa猜想的证明,引起数学界广泛关注。
他详细记录了使用Blueprint在Lean4中形式化证明的过程,强调了正确使用AI工具的重要性。
利用Blueprint工具,陶哲轩团队分解证明过程,通过众多贡献者并行工作成功形式化了PFR猜想。
陶哲轩认为形式化证明的主流化或创造既人类可读又机器可解的证明,将数学演变成一种高效的编程。
这一成果引发了对数学研究未来的讨论,一些人认为形式化将成为主流数学中的关键趋势,但陶哲轩提醒不要削弱理解证明的重要性。

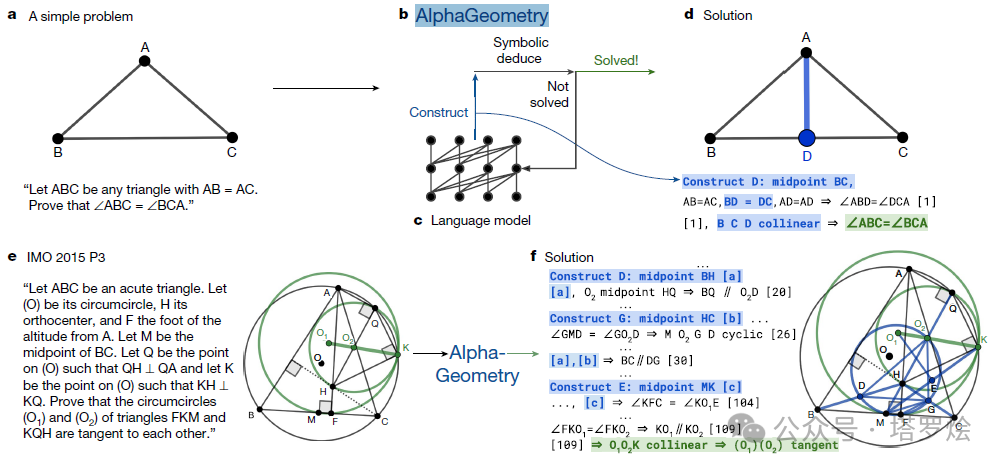
欧几里德的助手 · AI4S之AlphaGeometry
Q*猜想
先来看下来自LeCun的两篇推文...

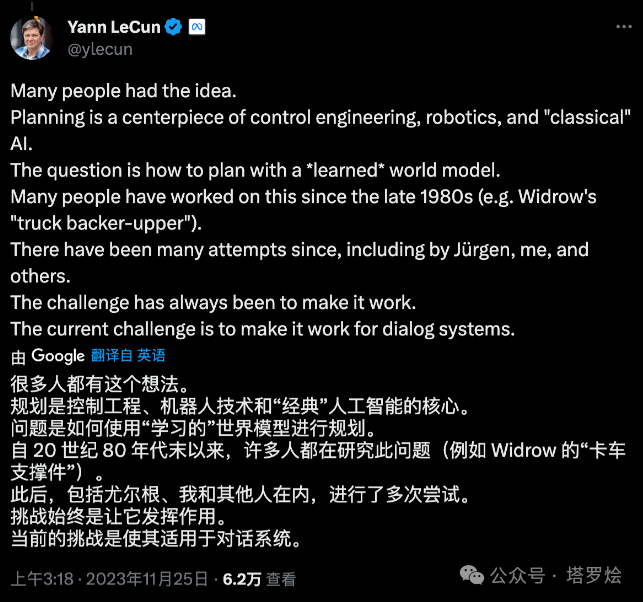
将在「下篇」进行持续更新..敬请期待。
编辑:黄继彦















 50
50











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









