







本文约3800字,建议阅读7分钟
本文对 VLN-CE 领域的碰撞问题进行了全面的分析,奠定了 VLN 在实际应用中部署的基础。
论文题目:
Safe-VLN: Collision Avoidance for Vision-and-Language Navigation of Autonomous Robots Operating in Continuous Environments
论文链接:
https://ieeexplore.ieee.org/abstract/document/10496163
https://arxiv.org/pdf/2311.02817.pdf
1、研究背景
在数字化、智能化浪潮下,通过指令控制无人系统执行一系列复杂操作达到某一特定目标的重要性日益凸显。而连续环境中的视觉和语言导航任务(Vision-and-Language Navigation in Continuous Environments,VLN-CE)[1] 便是其中的一项特定任务,并被视为人机交互领域在具身智能上的重要延伸。
具体而言,该任务通过自然语言指令控制无人系统在 3D 连续环境中根据视觉输入进行导航。另外,VLN-CE 属于计算机视觉、自然语言处理以及智能体等多学科交叉任务,通过对视觉语言进行特征提取与匹配,对智能体的下一动作进行推理。该技术能够使移动智能体在现实环境中理解人类的语言指令并完成任务,更贴近现实生活中人们对智能体的需求。
然而,在将 VLN 中算法迁移至 VLN-CE 任务中时,导航性能上有着显著差距,原因之一是在没有完美导航假设的连续环境中,智能体经常会发生碰撞。因此,本团队提出了面向 VLN-CE 中的碰撞问题的安全避障框架,针对 VLN-CE 中的碰撞情形进行了分类并提出 Safe-VLN,该工作近期发表在 IEEE Robotics and Automation Letters(RAL)上。
如图 1 所示,在视觉语言导航任务中,障碍物会导致智能体偏离原计划路线,甚至在一些特殊情况下,智能体会被困于障碍区域无法继续前进。因此,如何解决现实场景中存在的导航安全问题成为 VLN 算法从离散环境迁移到连续环境乃至现实环境中的关键。
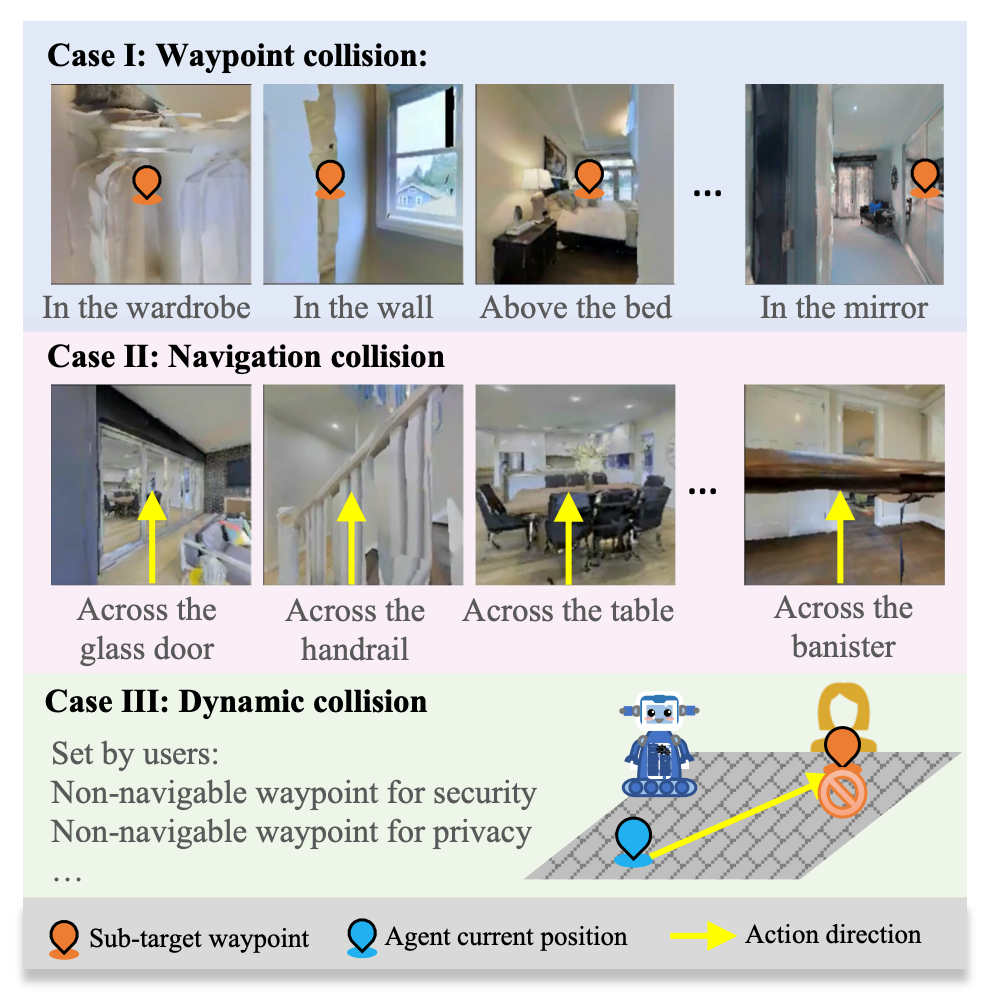
▲ 图1. VLN-CE碰撞情形分类示意图
碰撞情况在 VLN-CE 中普遍存在,这是由连续环境设置带来的挑战所引起的。首先,与离散环境中的航路点位置相比,由于对周围环境的不正确感知,航路点预测器会将候选航路点预测在障碍区,导致航路点不可达。其次,在连续环境中,没有了相邻节点之间的完美导航,当涉及到具有重建误差的障碍物时,智能体容易被障碍物干扰导航路线,从而无法到达下一个子目标。
虽然在智能体自主导航中存在许多避障研究,但由于 VLN-CE 中较长的导航路径、更复杂的环境以及额外的指令对齐等难度,处理避障的难度大大提升。受自主导航中碰撞研究的启发,本文对 VLN-CE 中碰撞的原因进行了分类,提出了连续环境下自主智能体视觉语言导航的安全避障方法,相应地改进了航路点预测器和导航规划模块,从而缓解 VLN-CE 中的碰撞问题。
2、方法介绍
由于 VLN-CE 中碰撞情形复杂,为了便于分析,本文通过大量实验将可能出现的碰撞分为三种类型,并分别讨论不同类型的碰撞产生的原因以及对导航性能的影响。
2.1 VLN-CE中的碰撞分类
为了提高智能体在 VLN-CE 中的导航性能,提高其在复杂连续环境中的适应能力,本文首先对 VLN-CE 中常见碰撞进行分类。
1. 航路点碰撞(waypoint collision):当预测的候选航路点位于障碍物区域(如衣柜、墙壁或床上方)内时,就会发生此类碰撞。
2. 导航碰撞(navigation collision):被定义为当智能体在向下一个航路点移动时遇到扶手、门、桌子等障碍物时发生的碰撞。
3. 动态碰撞(dynamic collision):发生在智能体动态运动过程中,由于安全或隐私问题,用户设置子目标航路点为不可导航状态。值得注意的是,本文考虑了 VLN-CE 现有数据集中没有出现的“动态碰撞”,以便全面捕捉现实世界应用中的所有潜在碰撞情况。
通过在 R2R-CE 数据集未见环境中进行验证,结果表明航路点碰撞和导航碰撞在现有方法中都经常发生,此外,为了模拟真实世界场景中的“动态碰撞”情况,本文以一定概率将智能体选择的下一航路点设置为不可导航状态。在考虑动态碰撞的情况下,现有算法成功率均有所下降。为针对性地解决这些碰撞带来的性能损失问题,本文提出 Safe-VLN 框架,如图 2 所示,Safe-VLN 包含对航路点预测器以及导航规划模块的改进。
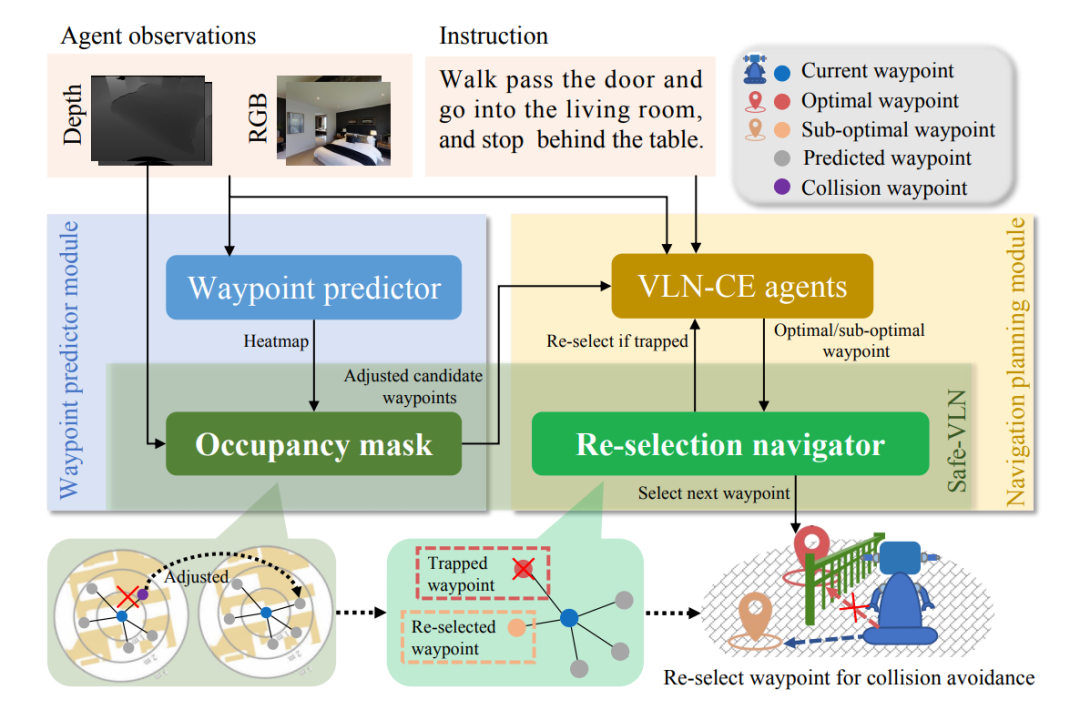
▲ 图2. Safe-VLN算法流程图
2.2 Safe-VLN避障框架
为了有针对性地解决上述碰撞类型,本文针对 VLN-CE 通用框架进行改进,提出 Safe-VLN。其中,VLN-CE 任务的通用框架分为三个模块:航路点预测器模块(waypoint predictor module)、导航规划模块(navigation planning module)以及底层动作控制模块(low-level control module),Safe-VLN 在航路点预测器模块加入障碍占比掩码以减少航路点碰撞,在导航规划模块采用“重新选择”策略以缓解导航碰撞情况。
1. 针对航路点碰撞的障碍占比掩码设计:Safe-VLN 的第一个模块旨在减轻航路点碰撞。通过航路点预测器获得候选航路点概率热图 。概率热图 表示以智能体为中心的 3 米半径内预测候选航路点的概率, 获得方法如下所示:
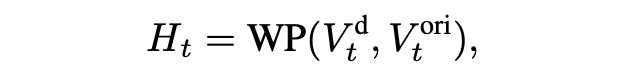
其中, 表示基于 Transformer 的航路点预测器,用于在连续环境中预测当前位置周围可导航的区域。 及 分别是全景视野下深度和角度特征。
随后,使用非最大值抑制 (Non-Maximum Suppression, NMS) 技术从热图 中采样 个候选航路点,航路点位置由集合 表示。基于 MP3D 数据集中的导航图训练上述航路点预测器,由于没有考虑周围的障碍物,预测的航路点可能位于障碍物区域内,导致航路点碰撞发生。
为了解决这个问题,本文首先使用深度信息生成模拟的二维激光占比掩码。其中占比掩码 与概率热图 具有相同的维度 ,可以通过下式获得:

其中, 的障碍物情况是通过模拟的二维激光信息得到的,将其与 相加后可得到调整后的概率热图。如图 3 所示,以智能体为中心的占比掩码 可提供周围环境的测距信息。通过将占比掩码合并到预测的概率热图 中,可以降低 中碰撞区域内的预测概率,从而获得调整后的概率热图 ,如下式所示:
其中, 是正则化操作,确保调整后的概率热图上的所有概率值之和等于 是控制占比掩码权重的超参数。
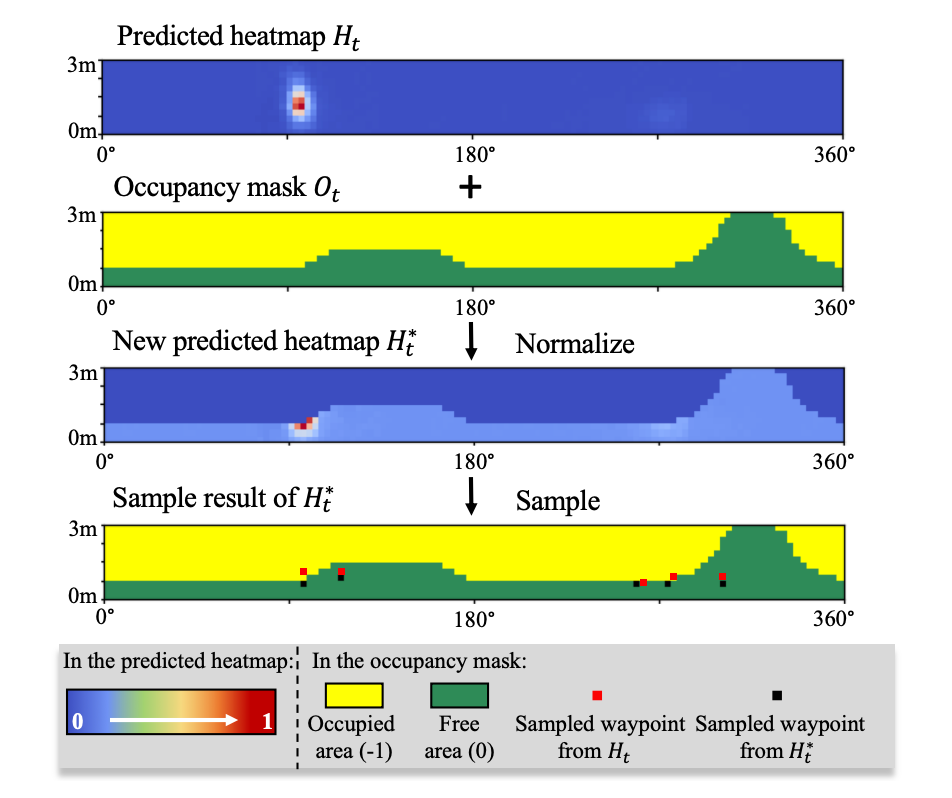
▲ 图3. 使用障碍占比掩码示意图
2. 针对导航碰撞的“重新选择”导航器:除了航路点碰撞之外,智能体还经常遇到导航碰撞或动态碰撞。为了解决这两种类型的碰撞,本文设计“重新选择”导航器作为 Safe-VLN 的第二个模块,通过调整 VLN-CE 框架中的导航规划模块,以预测最优及次优航路点来获得备选方案。基于此,当智能体被困于障碍区域时,能够重新选择作为备选方案的次优航路点,这不仅提高了其逃离障碍区域的可能性,还防止智能体为了避障与最终目标位置的显著偏离。
与 ETPNav [2] 类似,为了实现导航的长期规划,每一轮任务的历史路径都用图来描述:。这里 表示节点集,包括已访问节点、当前节点和已观察但未访问的节点。特殊节点 与所有其他节点互连,象征着动作“停止”。 表示所有边元素 的集合,其中 包含了两个相邻节点 和 之间的相对欧几里得距离。导航图 每个 时刻的节点更新。
对于每个节点 来说,其编码表示为 ,其中 表示连接操作, 表示当前智能体的位姿编码以及 表示时间步长的编码。
每个节点 的视觉语义编码 可表示为 ,其中, 是一个跨模态匹配模型,包含多层 Transformer 网络,用于对图像特征与指令特征进行匹配融合。
接着,导航规划模型 为 中的每一个节点生成得分 ,反映了模型对选择每个节点的概率偏好:。已访问节点和当前节点的分数被屏蔽,以防止不必要的重复操作。
最后,基于输出分数 ,智能体以贪婪的方式选择下一个航路点。如果选择了 ,智能体将在其当前位置停止移动,从而终止当前任务。
利用损失函数训练模型, 与 的训练目标是最大化最优航路点的分数,其中,最优航路点指的是具有离目标位置最短 Dijkstra 距离的航路点。为了选择合适的替代航路点,具有离目标位置第二短 Dijkstra 距离的次优航路点也被考虑在训练目标中,如下所示:
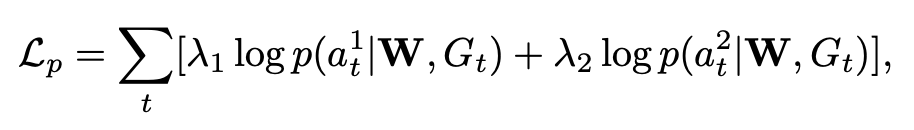
其中, 与 分别是距离目标的最短和第二短距离的航路点。 和 分别是时间步长 时刻的图和网络参数。选择 与 的概率分别是 与 。 与 是用于在最优和次优动作之间进行权衡的超参数。当发生碰撞时智能体可以重新选择次优导航节点。此时导航策略通过训练可以给出次优导航节点,这样在最优导航节点无法到达时,智能体可以选择另一个恰当的节点,在躲避障碍区域的同时,不会偏离目标路径过远。
3、实验结果
为了研究所提出的模型性能,五个评估指标被用来评估在见过和未见环境中模型的训练效果,评估后选出的性能较好模型进一步在未见环境中的测试集上对性能指标进行进一步测试。
具体来说,这些指标是为路径长度(Trajectory Length,TL)、导航误差(Navigation Errors,NE)、Oracle 成功率(Oracle Success Rates,OSR)、成功率(Success Rates,SR)以及通过路径长度加权考虑的成功率(Success rates optimized by Path Length,SPL)。
通过在最先进的 VLN-CE 方法上验证测试所提出的方法的有效性,如表1所示,与性能较好的 VLN 基线 ETPNav 相比,导航性能的提升是显著的,例如未见环境中的验证结果中导航误差降低了 0.23m,成功率提升了 3%;对于测试集来说,导航误差下降了 0.11m,成功率提升了 1%。
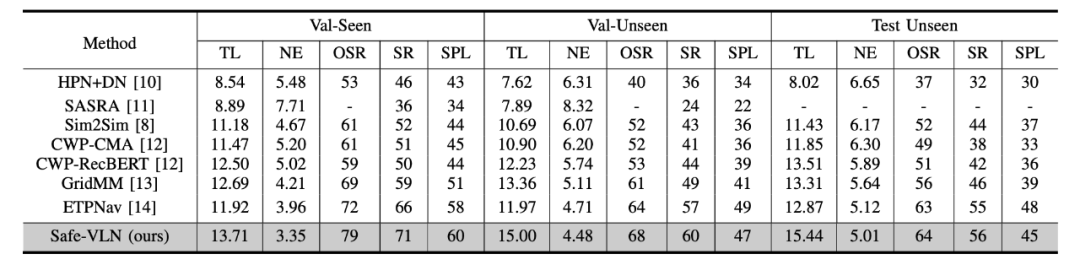
▲ 表1. R2R-CE数据集上的性能对比
为了说明在涉及航路点碰撞和动态碰撞的场景中重新选择导航器的有效性,我们在图 4 中给出了一个例子。如图 4(a)所示,智能体最初选择位于不可导航的泳池中的航路点作为子目标。随后,“重新选择”导航器调整其子目标航路点到可导航区域(如图 4(b)所示),并成功到达目标(如图 4(c)-(d)所示)。
此外,如图 4(e)所示,为了避免动态障碍,智能体选择一条替代路径来到达目标(如图 4(e)-(f)所示)。此示例表明,使用重新选择导航器,VLN-CE 中的智能体可以成功有效地避免连续环境中的障碍。
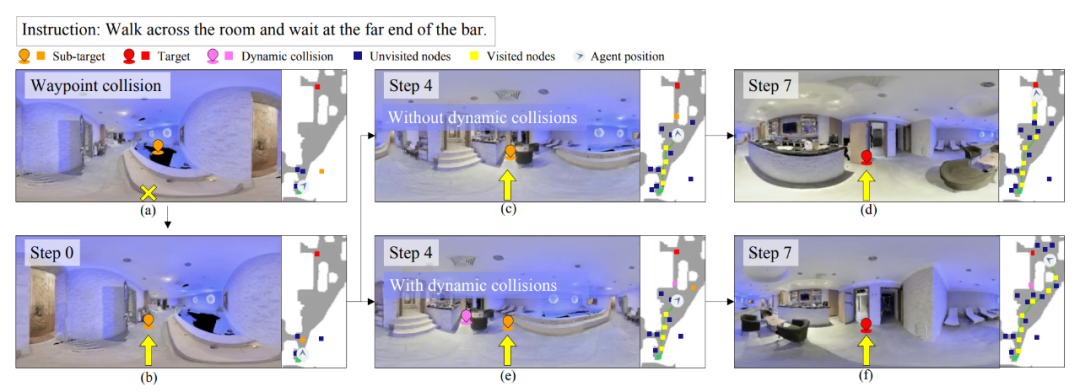
▲ 图4. 基于Safe-VLN的导航示例
4、总结
本文对 VLN-CE 领域的碰撞问题进行了全面的分析,奠定了 VLN 在实际应用中部署的基础。我们研究了 VLN-CE 及其碰撞场景对导航性能产生的影响,随后提出了一个名为 Safe-VLN 的避障框架。
所提出的方法使用了占用掩码来引导航路点预测器生成碰撞区域外的航路点。此外,Safe-VLN 采用了重新选择导航器以鼓励智能体灵活地调整行动,从而防止智能体被困在碰撞区域。计划在未来工作中将所提出的 Safe-VLN 应用于真实世界中并进行避障评估与分析。
参考文献
[1] J. Krantz et al., “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” in Proc. of ECCV. Springer, 2020, pp. 104–120.
[2] D. An et al., “ETPNav: Evolving topological planning for visionlanguage navigation in continuous environments,” arxiv, pp. 1–14, 2023.
[3] J. Krantz et al., “Waypoint models for instruction-guided navigation in continuous environments,” in Proc. of ICCV, 2021, pp. 15 162–15 171.
[4] M. Z. Irshad et al., “Semantically-aware spatio-temporal reasoning agent for vision-and-language navigation in continuous environments,” in Proc. of ICPR. IEEE, 2022, pp. 4065–4071.
[5] J. Krantz et al., “Sim-2-sim transfer for vision-and-language navigation in continuous environments,” in Proc. of ECCV. Springer, 2022, pp. 588–603.
[6] Y. Hong et al., “Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation,” in Proc. of CVPR, 2022, pp. 15 439–15 449.
[7] Z. Wang et al., “GridMM: Grid memory map for vision-and-language navigation,” in Proc. of ICCV, 2023, pp. 15 625–15 636.
编辑:于腾凯
校对:林亦霖


















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









