








作者:黄娘球
本文约1800字,建议阅读6分钟
本文简述了蒙特卡罗控制方法用于优化策略。我们在《原创 | 一文读懂强化学习在动态规划领域的应用》回顾了强化学习的基础概念,以及预测与控制 (求解已知的MDP)。
并且在《原创 | 一文读懂无模型的预测(强化学习二)》讲述了无模型的预测与控制Model-free Prediction and Control 中的,无模型的预测 (Model-free Prediction)通过与环境的交互迭代来求解问题。本文将继续讲解Lecture 3中无模型的预测与控制的中的,无模型的控制(Model-free Control)- 蒙特卡罗控制(Monte Carlo Control)。
注:本文整理自周博磊和David Silver的课件,并添加了我个人的总结和见解。
无模型的控制(Model-free Control)
无模型的预测与控制,即在一个未知的马尔可夫决策过程(MDP)中,估计与优化价值函数。
无模型的预测 (Model-free Prediction):在不知道 MDP 模型的情况下,仅通过与环境交互来评估状态价值(state value)。这个过程不依赖于明确的状态转移概率和奖励函数,而是通过实际的经验数据,使用蒙特卡罗(Monte Carlo,MC)或时间差分(Temporal-Difference,TD)来估计状态价值。
无模型的控制(Model-free Control):优化未知 MDP 的价值函数(value function)。无模型控制的目标是找到最优策略,使得在每个状态下的价值最大化。这包括两种主要的方法:① 蒙特卡罗控制(Monte Carlo Control,MC):基于多次从起始状态到终止状态的完整采样,计算并优化策略的价值。② 时间差分控制(Temporal-Difference Control,TD):结合了蒙特卡罗方法的无模型特性和动态规划的更新方式,通过逐步更新来优化策略。我们可以将这两种方法纳入广义策略迭代(Generalized Policy Iteration,GPI)的框架。GPI 是指通过交替进行策略评估(Policy Evaluation)和策略改进(Policy Improvement)来逐步逼近最优策略的过程。在 GPI 中,策略评估阶段使用无模型预测方法(如 TD 或 MC)来评估当前策略的价值函数,而策略改进阶段则通过贪婪地选择能够最大化价值的行为来更新策略。
1.广义策略迭代(Generalized Policy Iteration,GPI)
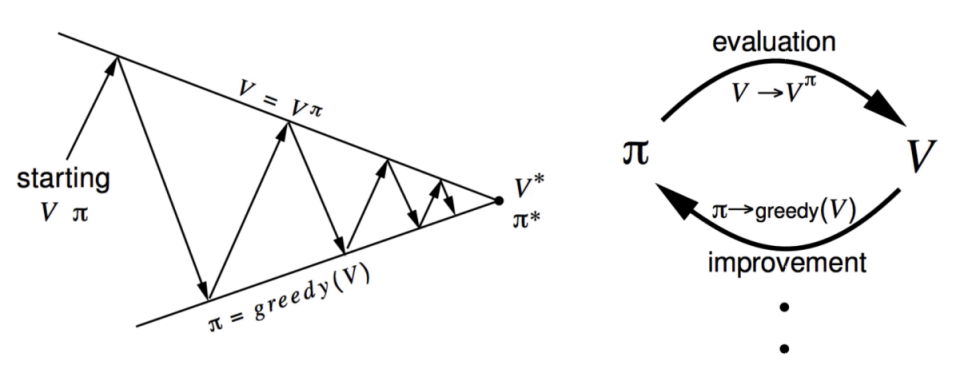
GPI 是通过交替进行策略评估(Policy
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4573
4573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









