







来源:DeepHub IMBA
本文约3100字,建议阅读6分钟
本文中介绍了使用PyTorch Profiler来查找运行瓶颈和一些简单的提速方法。如果所有机器学习工程师都想要一样东西,那就是更快的模型训练——也许在良好的测试指标之后。
加速机器学习模型训练是所有机器学习工程师想要的一件事。更快的训练等于更快的实验,更快的产品迭代,还有最重要的一点需要更少的资源,也就是更省钱。
熟悉PyTorch Profiler
在进行任何优化之前,你必须了解代码的某些部分运行了多长时间。Pytorch profiler是一个用于分析训练的一体化工具。它可以记录:
CPU操作时间、CUDA内核计时、内存消耗历史。
要记录事件,只需要将训练嵌入到分析器上下文中,如下所示:
import torch.autograd.profiler as profiler
with profiler.profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
on_trace_ready=torch.profiler.tensorboard_trace_handler('./logs'),
) as prof:
train(args)然后就可以启动tensorboard查看分析轨迹。如果这一步有问题,请查看是否安装了torch-tb-profiler。
Profiler有很多不同的选项,但最重要的是activities和profile_memory,一般情况下我们只需要这两个选项,因为启用的选项越少,开销就越小。
如果只想要分析CUDA内核执行时间,那么关闭CPU分析和所有其他功能也是可以的。因为在这种模式下,我们可以理解为显卡能力的真实评测。
为了方便分析,我们可以为每一步操作指定名称,例如
with profiler.record_function("forward_pass"):
result = model(**batch)
with profiler.record_function("train_step"):
step(**result)或者增加更精细的自定义的标签,这里的名称将在跟踪中可见,我们就可以更简单的追踪想要的东西了。
with profiler.record_function("transformer_layer:self_attention"):
data = self.self_attention(**data)
...
with profiler.record_function("transformer_layer:encoder_attention"):
data = self.encoder_attention(**data, **encoder_data)查看PyTorch Traces
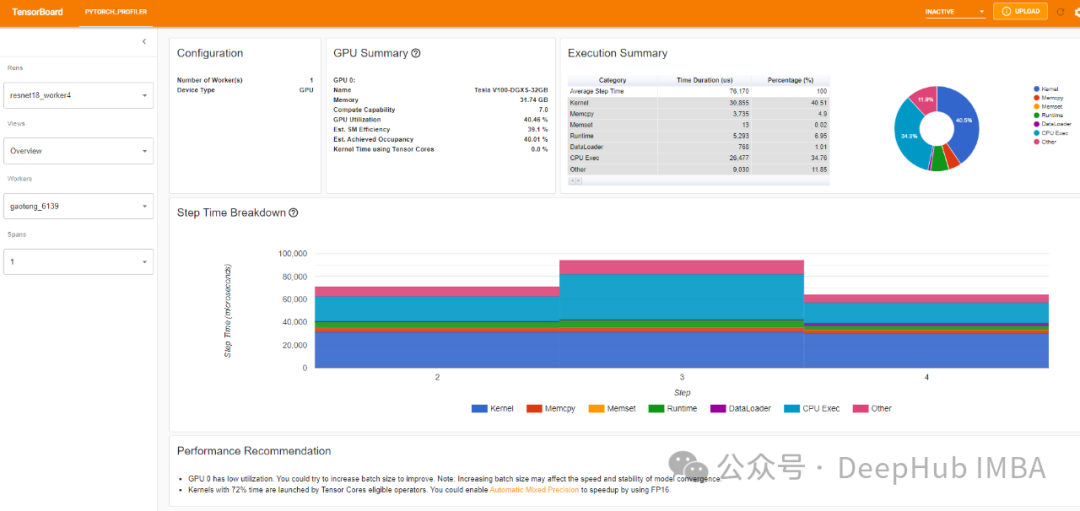
收集完信息后,tensorboard显示是这样的。
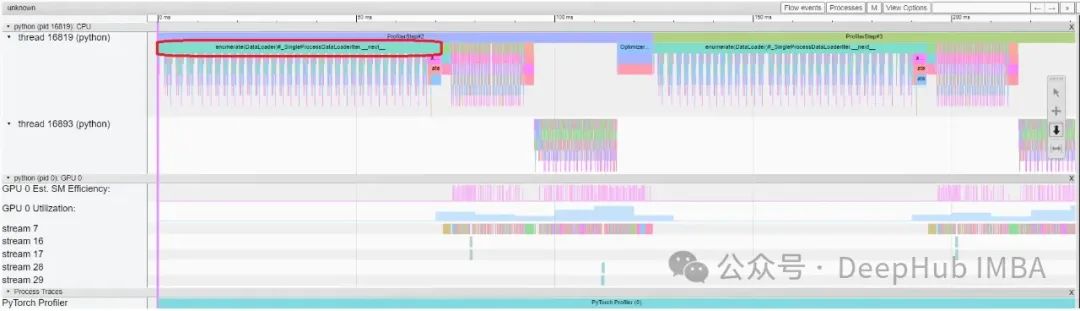
训练的过程一般包括:数据加载、前向传播、反向传播。
反向传播由PyTorch在一个单独的线程中处理(上图中的线程16893),因此很容易识别,这部分门也控制不了,因为都是Pytorch根据我们的计算来自动进行的。(当然也可以自定义反向传播,但是这过于复杂,一般不建议自己实现)
首先看看数据加载:对于数据加载我们希望时间接近于零。
这是因为在数据加载过程中,GPU什么也不做,这会使可用资源利用率不足。并且在Pytorch的训练时数据处理可以与GPU计算重叠,因为它们是独立的部分,也就是说我们加载一个批次的时间只要与一个前向和一个反向传播的时间相近就可以了,这样就可以最大化的利用GPU的资源。
这里可以很容易地识别GPU空闲的区域-查看性能分析器跟踪中的GPU Est. SM效率和GPU利用率数字。没有活动的区域是我们的关注点,因为GPU什么都不做。
如果使用PyTorch DataLoader,则可以通过指定num_workers来多线程处理数据。如果您使用IterableDataset,则会更复杂,因为数据将被复制。这个问题可以通过使用get_worker_info()来解决,需要以某种方式调整迭代,以便每个worker接收不同的、不相交的行,所以这个比较麻烦,一般尽量避免IterableDataset。
内存分配器 memory allocator
当你在CUDA设备上使用PyTorch分配张量时,PyTorch将使用缓存分配器。这里是CUDA的执行机制:cudaMalloc和cudaFree的操作比较昂贵,我们要尽量避免。所以PyTorch会尝试重用以前通过cudaMalloc块分配的,如果PyTorch的分配器有一个合适的块可用,它会直接给出它,而不调用cudaMalloc。这样cudaMalloc只在开始时被调用。
但是如果你处理的是可变长度的数据(比如文本数据),不同的正向传播将需要不同大小的中间张量。因此,PyTorch的分配器可能没有适当的可用数据块。在这种情况下,分配器会调用cudaFree释放以前分配的块,为新的分配释放空间。
然后分配器再次开始构建它的缓存,进行大量的cudaMalloc,这是一个昂贵的操作,但是可以通过tensorboard分析器查看器的内存分析器部分来发现这个问题。
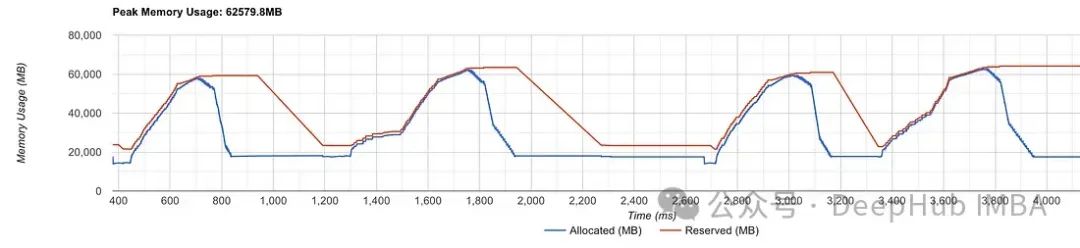
可以看到与分配器的保留内存相对应的红线不断变化。这意味着PyTorch分配器不能有效地处理分配请求。而当分配程序在没有频繁调用的情况下处理分配时,红线是完全笔直的,如下图所示:
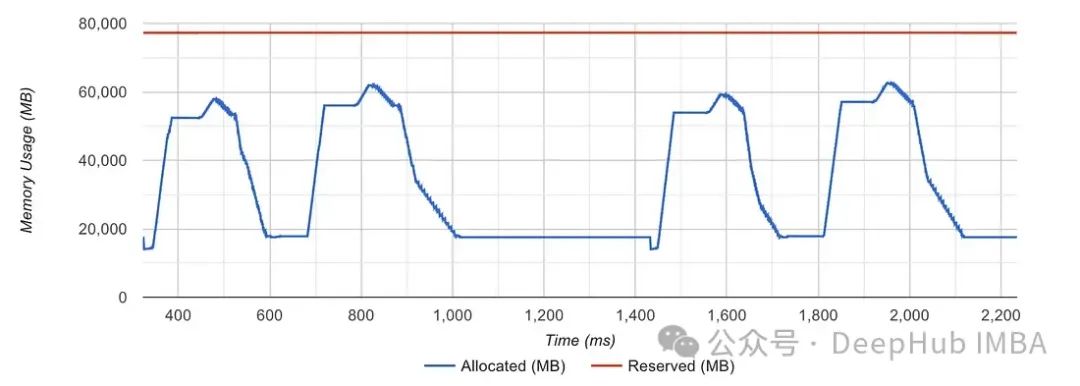
我们如何解决呢?
第一件值得尝试的事情是设置PyTorch相对较新的分配器模式:
PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True"这告诉PyTorch分配器分配可以在将来扩展的块。但是,如果大小变化太大,它仍然可能无法解决问题。
所以我们智能手动来进行优化,那就是是使数据形状一致。这样分配器就更容易找到合适的数据块进行重用。
比如最简单的将数据填充到相同的大小。或者可以通过运行具有最大输入大小的模型来预热分配器。
内存历史记录
我们想要最大化的使用所有可用的GPU内存——这让我们能够运行大量数据,并更快地处理数据。但是在某些时候,当增加批处理太大时,将遇到CUDA内存不足错误。是什么导致了这个错误?
为了调试它,我们可以查看分配器的内存历史记录。它可以通过PyTorch记录,然后在https://pytorch.org/memory_viz上可视化。
Start: torch.cuda.memory._record_memory_history(max_entries=100000)
Save:
torch.cuda.memory._dump_snapshot(file_name)
Stop:
torch.cuda.memory._record_memory_history(enabled=None)
可视化会画出这样的东西:
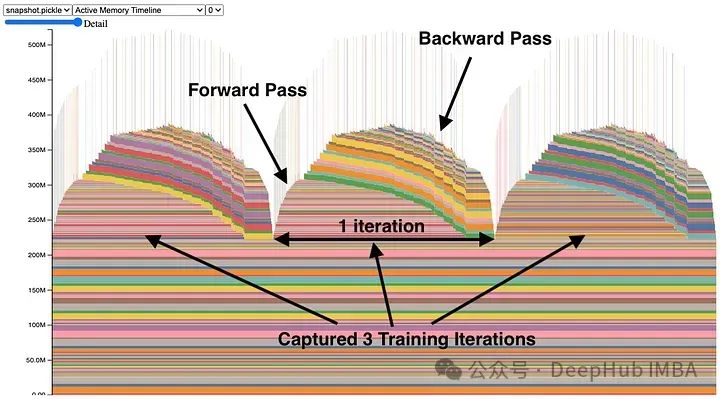
x轴表示时间,y轴表示已使用的总内存,彩色块表示张量。它显示了张量何时被分配,何时被释放。
你可能会注意到狭窄的尖峰,这些是持续时间很短的张量,并且占据了很多空间。通过点击一个张量,可以得到这个张量被分配到哪里的信息。我们希望的就是最小化这些峰值,因为它们限制了有效的内存使用。检查导致这个峰值的原因,并考虑优化或者使用其他计算方法替代。
除了峰值之外,很容易检测到内存泄漏:
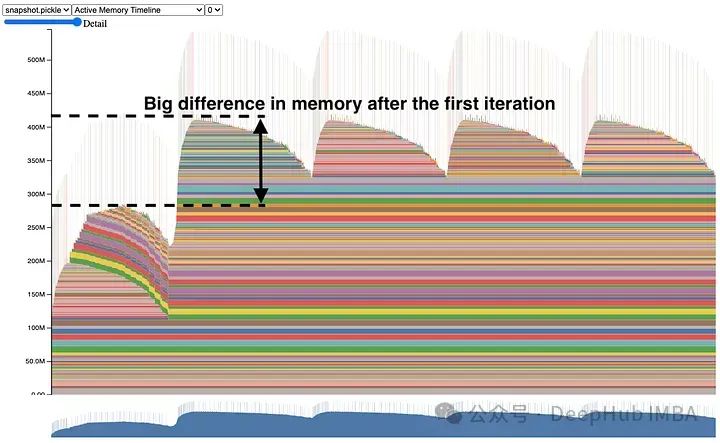
第一次运行之后的一些数据没有被清除,所以导致内存占用过高。通过点击块,可以知道这些张量是从哪里来的。在图像中,梯度在训练步骤之后没有被清除,因此它们在向前传递过程中处于无用状态,占用了宝贵的内存。
提高模型速度,减少内存使用
我们知道了原因,并且可以通过Profiler来找到瓶颈,那么我们可以通过什么方法来加速训练呢?
1、FlashAttention
首先可以使用FlashAttention来计算点积注意力来提高效率。如果你没有听说过它,它是一种计算精确的点积注意力的方法,并且不需要明确地构建注意力矩阵。这优化了GPU的io操作,提高了速度,也极大地减少了内存消耗。
但是FlashAttention仅适用于兼容硬件上的fp16和bf16精度。那就是NVIDIA Ampere, Hooper以上的GPU
当然也有其他的库可以替换,例如XFormers,和NV自己的Transformer Engine。
新版本的PyTorch也内置了FlashAttention的支持,在文档中:
torch.backends.cuda.enable_flash_sdp(): Globally enables or disables FlashAttention.
2、 FSDP 优化多gpu数据冗余
如果使用多个gpu来运行训练,基本的解决方案是使用DistributedDataParallel。生成了几个相同的进程,并且在反向传播期间聚合梯度。
当我们生成相同的进程时,在每个GPU上都有相同的模型和优化器状态,这是冗余的。可以通过跨数据分片来优化内存使用。
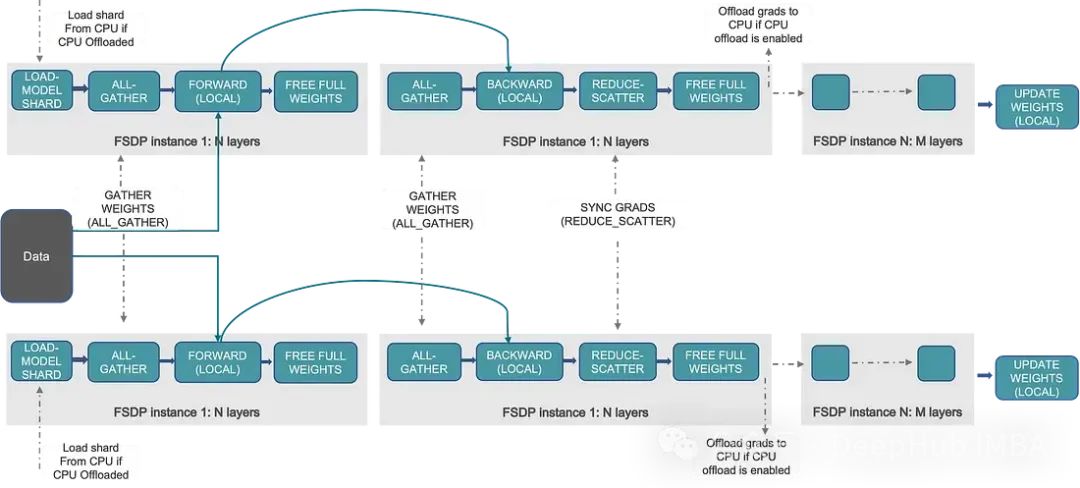
当在多个gpu上进行训练时,每个进程在使用DDP进行训练时都有相同数据的精确副本。可以通过实现以下几个增强功能来优化它:
ZeRO 1 :分片优化器状态
当使用DDP进行训练时,每个进程都拥有优化器状态的完整副本。对于zer01,可以让每个rank只保留优化器状态的一部分。在反向传播期间,每个rank只需要收集与其参数相关的优化器状态来进行优化步骤。这种冗余的减少有助于节省内存。
💡在Adam的情况下,它保存的参数大约是模型大小的两倍,将优化器状态分片为8个rank意味着每个rank只存储总状态大小的四分之一(2/8)。
ZeRO 2:梯度分片
除对优化器状态进行分片外,还可以修改优化器步骤来切分梯度。我们可以将所有与该rank持有的状态相关的梯度集合起来,计算优化步骤,然后将部分参数的优化步骤发送给所有其他rank
现在每个rank不需要保存一个完整的梯度副本,这样可以进一步降低峰值内存消耗。
ZeRO 3 :模型参数分片
我么不需要在每个rank上存储模型的完整副本,我们将在向前和向后期间及时获取所需的参数。在大型模型的情况下,这些优化可以显著降低内存消耗
如何使用FSDP?
其实很简单。我们所需要的就是用FSDP包裹模型:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
model = FSDP(model)
# it's critical to get parameters from the wrapped model
# as only a portion of them returned (sharded part)
optimizer = optim.Adam(model.parameters())
# consuct training as usual
train(model, optimizer)可以指定FSDP的分片策略。例如可以选择SHARD_GRAD_OP策略来实现与ZeRO2类似的行为。
3、torch.compile
这是最简单也是最直接的优化方式了,只要启用torch compile,它就可以将代码的速度提高几个百分点。
在Torch2.0中增加了compile方法,他会跟踪执行图,并尝试将其编译成一种有效的格式,以便几乎无需Python调用即可执行模型。
import torch
model = torch.compile(model)也就是说,2.0以后只要你的模型能用compile那么就用compile吧。
总结
本文中介绍了使用PyTorch Profiler来查找运行瓶颈,并且介绍了一些简单的提速方法,虽然这篇文章没有完整的解释,但是里面提供的方法都是值得马上尝试方法,希望对大家有所帮助。
编辑:于腾凯
校对:龚力
















 6114
6114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









