







来源:专知
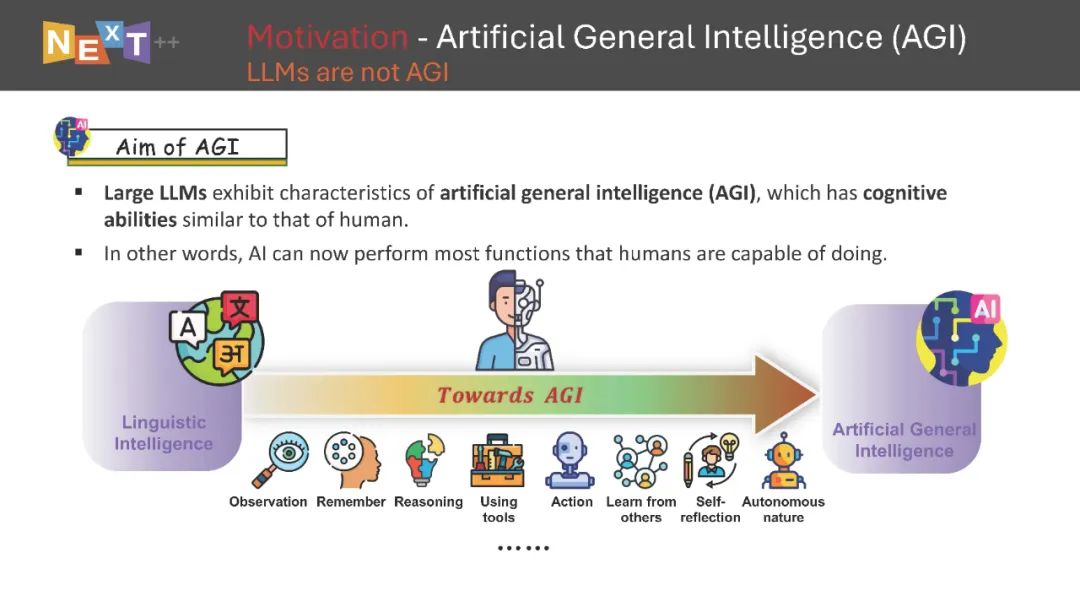
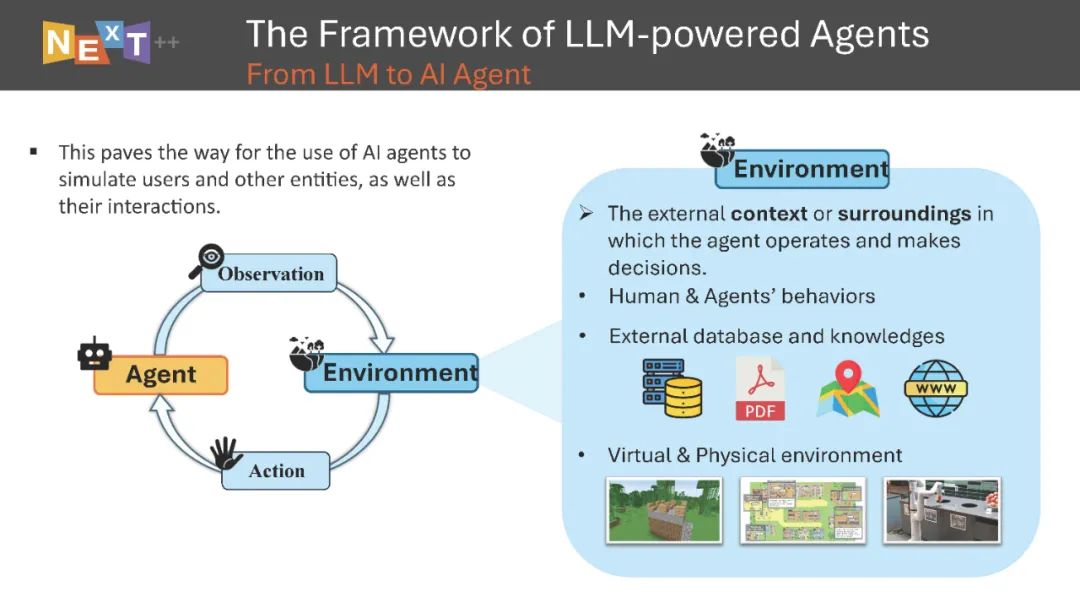
本文为论文介绍,建议阅读5分钟在本教程中,我们将深入探讨LLM驱动代理在各种信息检索领域中的前沿技术。信息检索的核心目标已不仅仅是将用户与其搜索的相关信息连接起来,还包括丰富连接的多样性、个性化和互动性,确保信息检索过程在全球数字时代中尽可能无缝、有效和支持性。目前的信息检索系统通常面临一些挑战,例如对查询理解的限制、响应的静态和僵化、个性化程度有限以及互动性受限。随着大语言模型(LLMs)的出现,通过将LLM驱动的代理集成到这些系统中,带来了变革性的范式转变。这些代理具备记忆和规划等关键的人类能力,使其在完成各种任务时表现得像人类一样,有效地增强用户参与度并提供量身定制的互动。
在本教程中,我们将深入探讨LLM驱动代理在各种信息检索领域中的前沿技术,例如搜索引擎、社交网络、推荐系统和对话助手。我们还将探讨在无缝集成这些代理时面临的挑战,并指出可能彻底改变信息检索方式的未来研究方向。
https://llmagenttutorial.github.io/sigir2024





关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









