







来源:时序人
本文约3000字,建议阅读5分钟
本文介绍了一种通用的校准方法,用于检测和调整经过训练的模型中的 CDS。近年来,将深度学习模型引入时间序列预测领域取得了显著成功。从数据生成的角度来看,现有模型容易受到时间上下文(无论是否被观测到)驱动的分布偏移的影响。这种由上下文驱动的分布偏移(CDS)会在特定上下文中引入预测偏差,并对传统的训练范式构成挑战。来自浙江大学的研究团队提出了一种通用的校准方法,用于检测和调整经过训练的模型中的 CDS,目前该工作已被 KDD 2024 接收。

【论文标题】
Calibration of Time-Series Forecasting: Detecting and Adapting Context-Driven Distribution Shift
【论文链接】
https://arxiv.org/abs/2310.14838
【代码链接】
https://github.com/HALF111/calibration_CDS
背景介绍
01 时间序列中的上下文分布偏移(CDS)
在时间序列中,分布偏移的问题普遍存在——所谓的分布偏移,即指时间序列统计特性以及分布会随着时间不断变化。这会导致训练集和测试集的分布不一致,那么按照机器学习范式在训练集训练的模型、在测试集上就会出现性能下降。
特别地,我们发现这种偏移通常是由一些上下文因素(称为context)驱动的。例如时间阶段(temporal segment)和周期相位(periodic phase)等均为重要的因素。
对于时间阶段,例如我国人均 GDP 存在逐年上涨的趋势,那么 2014 年的数据和 2024 年的数据分布会存在不同;对于周期相位,例如商场的人流量会随着每周的工作日和周末出现周期性变化,那么周三的数据和周六的数据分布也会存在不同。这些例子可以佐证这些上下文因素是会对分布情况造成影响的。
在本文中,我们将这种问题称为:上下文驱动的分布偏移(Context-driven Distribution Shift, CDS)。
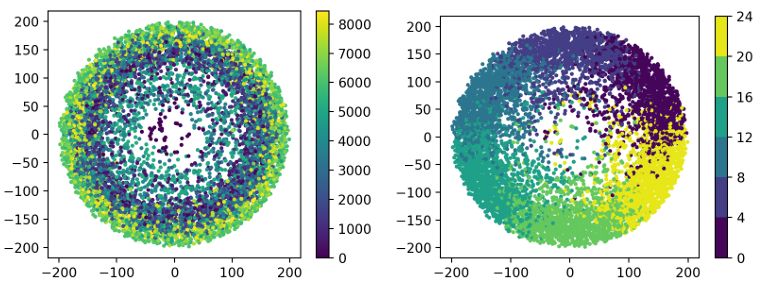
图1 左图为上下文:时间片段;右图为上下文:周期性阶段
02 CDS的影响
CDS 同样会影响模型的性能。例如我们以周期相位为例,分别统计了模型在不同的周期下的数据上的残差,以及总体数据上的残差(残差能够反映模型拟合性能的好坏)。
从图2中可以发现:总体残差是无偏的(总体的残差接近于一个均值为零的正态分布),但是特定上下文下的残差却存在偏差(即在 47th phase 和 32nd phase 这两个不同上下文内的残差分布的均值均不为零)。这说明受到上下文的影响,模型容易学到虚假的相关性,难以同时对每个上下文的数据都得到最优的性能。

图2 (条件)残差分布
03 论文贡献
针对 CDS,我们提出了一个"检测+微调"的模型校准框架。具体包括以下两个部分:
Reconditionor:基于残差的上下文分布偏移检测器(Residual-based Context-driven Distribution Shift Detector)。通过计算总体的残差分布以及各个 context 下的残差分布间的KL散度,量化并检测模型对 CDS 的敏感程度。该值越高、则说明模型受CDS影响越强。
SOLID:样本级上下文微调器(Sample-level Contextualized Adapter)。对于每个测试样本,构建一个和该测试样本有相似上下文的子数据集,并用该子数据集微调现有模型的预测层以校准其预测。理论分析证明,这一微调策略相较于不做微调/重新训练新预测层而言,能得到偏差-方差间的平衡。
此外,本文的方法也是模型无关的。对于已训练好的模型,只需要在测试时多做一个微调的校准步骤即可。
主要方法

图3 校准框架的流程
01 Reconditinor-基于残差的
上下文分布偏移检测器
首先,我们提出了 Reconditionor,这是一个基于残差的检测器。其用于检测并量化模型受 CDS 的影响程度。
具体而言,我们计算模型在各上下文下的残差分布相较于总体残差分布的KL散度,用于检测分布偏移的程度。事实上这个表达式也可以转化成残差和上下文之间的互信息,可以理解为知道上下文后对于残差的不确定度的减少量。该值的计算公式如下:
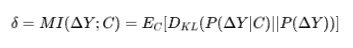
02 SOLID-样本级上下文微调器
其次,我们提出了 SOLID,这是一个样本级别的基于上下文的微调器。
对于每个测试样本,SOLID 构建一个和当前测试样本有相似上下文分布的样本的子数据集,并用该子数据集微调现有模型的预测层,从而对其做进一步的校准。
(1)SOLID 怎么做?
在 SOLID 中包含两个关键点:一个是需要做样本级别的微调,另一个则需要构建一个包含相似上下文分布的样本的子数据集。
样本级别微调(Sample-level adaptation):考虑到时间序列中的上下文也是一直在变的,因此即便对于一个校准后的模型,也很难对于所有样本适用。基于此,对于每个样本独立地去做微调是更加合理的。
相似上下文分布的子数据集(Contextualized dataset):考虑到对于待预测样本,无法获取其真实值,从而无法直接用其来做微调。因此我们这里需要做一次数据增强,从历史数据中找出和当前样本有相似上下文分布的那些样本。
(2)如何构建相似上下文子数据集?
受时间阶段上下文的影响,我们挑选时间间隔接近的样本。
受周期相位上下文的影响,挑选周期影响下的相位差接近的样本。
考虑到其他未观测到的上下文的影响,我们用样本相似度来衡量之,并挑选相似度最高的样本。
(3)偏差-方差平衡
从理论上分析,我们证明这样的方法能够达到偏差和方差间的平衡。
假如不做微调,则模型无法对于当前样本的上下文有效建模,因此会存在偏差。
假如完全重新训练新的预测层,则由于原来的知识丢失、以及当前相似上下文子数据集中的样本偏少,会导致方差增大。
因此,通过全局训练 + 使用相似上下文子数据集微调的方式,从而能够达到偏差-方差之间的平衡。
(4)模型无关
此外,我们的方法也是模型无关的。这是因为 SOLID 并不会修改原有模型的训练,只会在测试中额外做一个后处理的校准,从而能够较为轻松地用在各种时序预测模型上。
这一流程可以再次归纳如下:
训练阶段:直接用全局数据建模,因此无需修改原有模型训练过程。
微调阶段:针对当前测试样本,构建相似上下文子数据集,并微调模型的预测层以完成校准;再用校准后的模型完成预测,从而能得到更好的性能。
03 Reconditionor和SOLID算法流程


实验结果
01 Benchmark测试
下表中为不同的预测窗口长度下的平均结果, 表示 SOLID 提升的百分比;则表示 Reconditionor 受时间阶段和周期相位影响的值,其值越高(红色)则表示模型受 CDS 影响越严重;较低的值(蓝色)则表示模型受CDS影响较小。
可以观察到在 ETT、Traffic、Electricity、Illness 等常用时序数据集和 PatchTST、DLinear 等时序预测模型上,我们的方法均带来了提升。
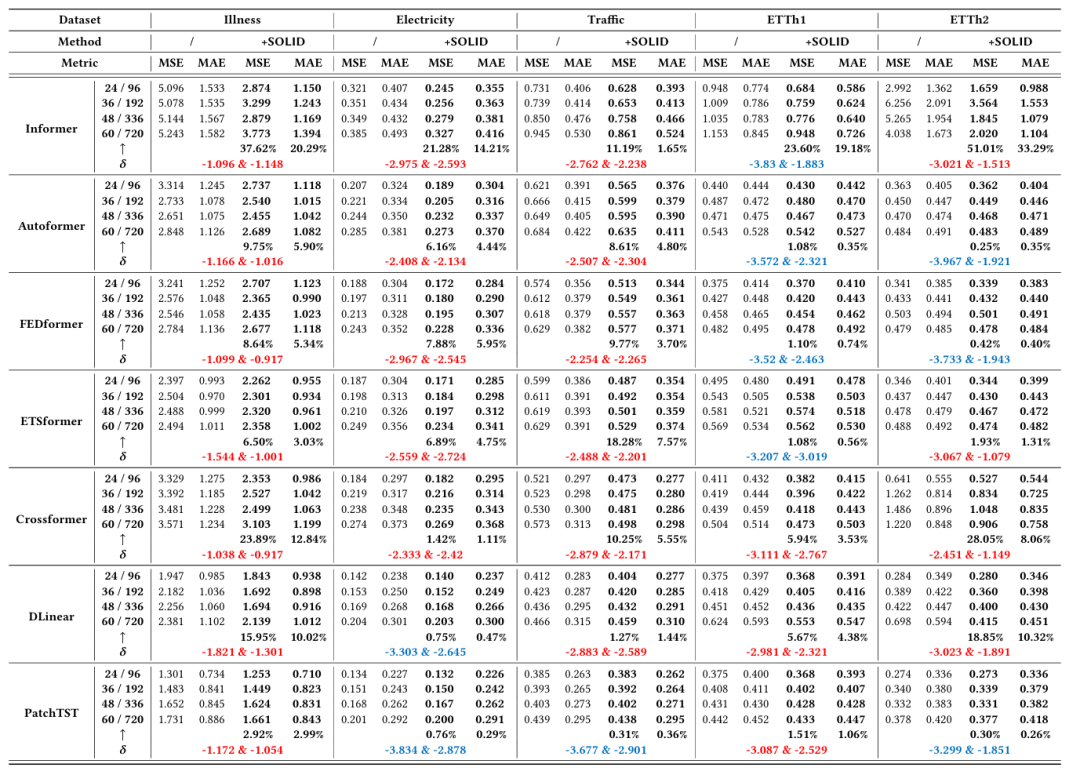
表1 性能比较
02 Reconditionor和性能提升
下图中展示了 Reconditionor 分数和 SOLID 带来的性能提升的关系。
可以发现二者呈现正相关,说明通过 Reconditionor 检测出受 CDS 影响越严重的模型,经过 SOLID 微调后性能提升的幅度也会更大。
这也说明本文的"检测+微调"的模型校准框架是能够生效的。
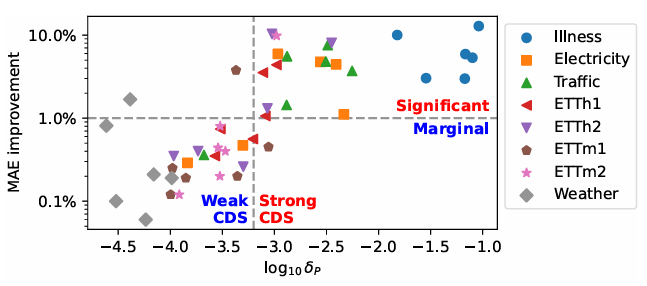
图4 Reconditionor分数和SOLID带来的性能提升的关系
03 可视化
下图为一些可视化的例子,其中蓝线为真实值,橙线为 SOLID 微调前的模型预测,绿线为 SOLID 微调之后的模型预测。可以观察到微调后的预测普遍会更接近真实值。

图5 跨不同数据集和模型的各类案例研究及本文提出方法的可视化
总结
本文发现了时间序列中的分布偏移通常是由一些上下文因素驱动的,并将这种问题称为:上下文驱动的分布偏移(Context-driven Distribution Shift, CDS)。目前的模型大多均会受到 CDS 的影响而影响其性能。
此外,本文还提出了"检测+微调"的模型校准框架 ——(1)通过计算模型在总体数据的残差分布和在各个上下文的残差分布间的KL散度,用于量化并检测模型对CDS的敏感程度;(2)对于每个测试样本,构建和该测试样本有相似上下文分布的子数据集,并用该子数据集微调现有模型的预测层、以校准其预测。
最后,在多个数据集和多个时序预测模型的实验结果验证了本文方法的有效性,能够成功用于解决普遍存在的上下文驱动的分布偏移的问题。
编辑:于腾凯
校对:梁锦程
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 9161
9161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









